




摘要:在深度学习领域,创新迭代日新月异,推动着各行业智能化变革。DeepSeek 模型凭借其卓越技术优势,成为众多开发者和研究者的探索焦点。蓝耘智算平台则为其高效运行提供有力保障。
一、蓝耘智算平台:AI 新基建
在人工智能飞速发展的当下,算力已成为推动技术进步和产业变革的核心要素。蓝耘智算平台,作为算力服务领域的杰出代表,为各类人工智能应用提供了强大的计算支持,成为众多开发者和企业实现 AI 创新的得力助手。
蓝耘智算平台是一个基于 Kubernetes 的现代化云平台,专为大规模 GPU 加速工作负载而精心打造。它凭借行业领先的灵活基础设施以及大规模的 GPU 算力资源,构建起了一个功能强大、高效便捷的智能计算生态系统。在算力资源方面,蓝耘智算平台拥有丰富且强大的 GPU 集群,支持多种主流 GPU 型号,如 NVIDIA A100、V100 等。这使得平台能够满足不同用户对算力的多样化需求,无论是进行大规模的 AI 模型训练,还是处理实时推理任务,都能提供充足且稳定的算力支持。举例来说,在训练一个大型的图像识别模型时,蓝耘智算平台的强大算力可以显著缩短训练时间,提高模型的迭代速度,帮助研究人员更快地验证模型的有效性和准确性。
从功能特性来看,蓝耘智算平台具备高度的开放性和灵活性。它支持多种 AI 框架,如 TensorFlow、PyTorch 等,以及各种开发工具。这意味着用户可以根据自身的项目需求和技术偏好,自由选择适合的开发环境,实现资源的高效利用。同时,平台还提供了全流程的 AI 支持,涵盖了从数据预处理、模型构建、训练优化,到推理部署的每一个环节。用户可以在蓝耘智算平台上一站式完成从项目开发到上线的所有操作,大大提升了工作效率。
蓝耘智算平台还具有显著的成本优势。其速度可比传统云服务提供商快 35 倍,成本降低 30%。这种高效且经济的特性,使得蓝耘智算平台在众多算力云服务中脱颖而出,无论是对于初创企业还是大型机构,都能为其量身定制经济高效的解决方案,帮助用户在降低算力使用成本的同时,获得卓越的计算性能。
此外,蓝耘智算平台还提供了一系列贴心的服务和功能。例如,其智能调度系统能够根据任务的特点和紧急程度动态分配算力资源,确保计算资源的高效利用并有效缩短任务执行时间;平台具备高可靠性和安全性,采用多重数据备份和加密技术,全面保障用户数据的安全与隐私;在易用性方面,蓝耘智算平台提供简洁直观的操作界面,科研人员和企业开发者都能够快速上手,轻松提交任务、监控进度并获取结果。
二、DeepSeek 模型:AI 时代的智慧引擎
在 AI 大模型的璀璨星空中,DeepSeek 模型以其卓越的性能和独特的技术优势,成为备受瞩目的焦点。它不仅在技术架构上进行了大胆创新,还在性能表现、成本控制以及开源生态建设等方面展现出了非凡的实力。
DeepSeek 模型基于 Transformer 架构,并在此基础上进行了深度优化,融合了稀疏注意力机制,有效降低了计算复杂度。同时,引入动态路由网络,能够依据输入内容智能调配计算资源,显著提升了长文本及复杂逻辑任务的处理速度。例如,在处理一篇长达数万字的学术论文时,DeepSeek 模型能够快速准确地提取关键信息,进行内容摘要和要点总结,展现出强大的长文本处理能力 。
在模型训练过程中,DeepSeek 采用了预训练、对齐和领域微调的分阶段训练策略。在预训练阶段,模型沉浸于万亿级多语言语料库,涵盖中文、英文及代码等,并融入知识图谱,深化了对实体的理解;对齐阶段结合人类反馈强化学习(RLHF)与宪法 AI 理念,确保输出既安全又符合价值观导向;领域微调阶段则针对金融、医疗等特定领域注入专业数据,提升了模型在专业任务上的表现。以医疗领域为例,通过对大量医学文献和病例数据的微调,DeepSeek 模型能够辅助医生进行疾病诊断、药物推荐等工作,为医疗行业的智能化发展提供了有力支持。
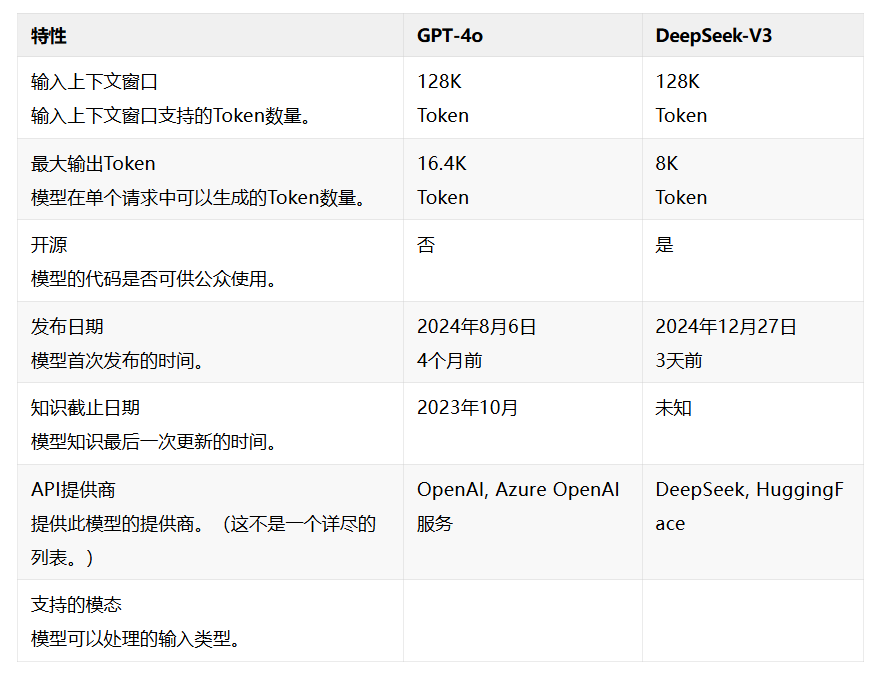
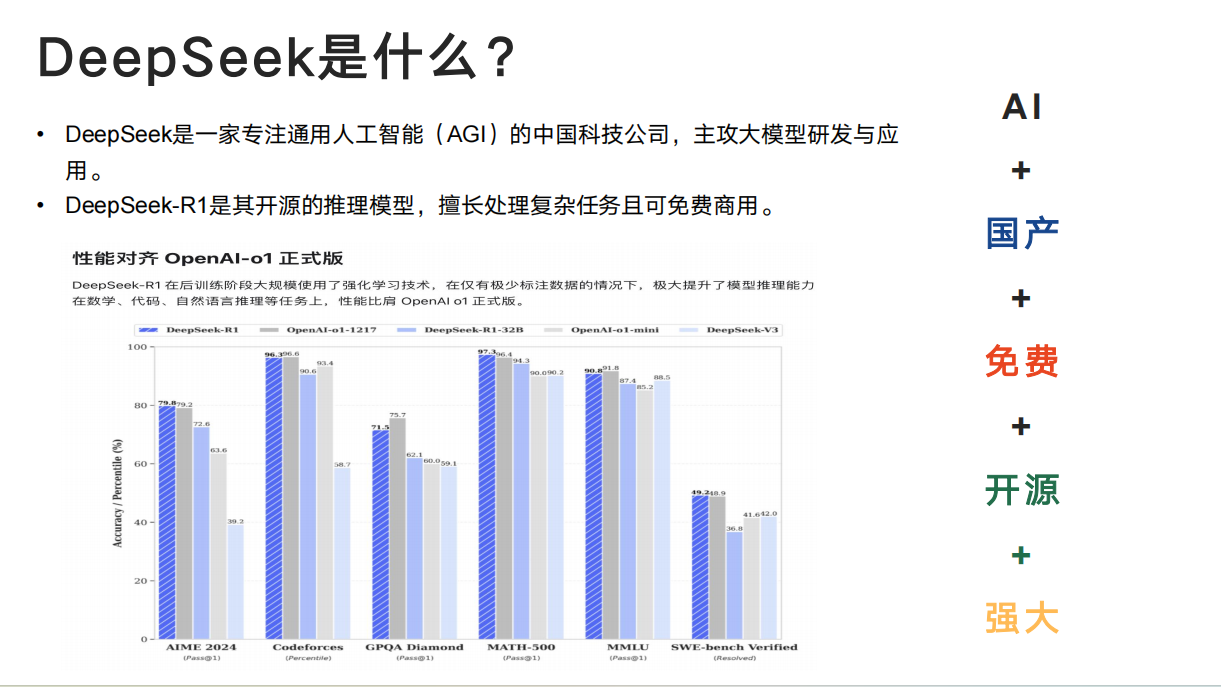
在性能表现上,DeepSeek 模型十分亮眼。在数学、代码、自然语言推理等任务上,其性能比肩 OpenAI - o1 正式版。根据永信至诚依托生成式人工智能(AIGC)加持的春秋 AI 测评 “数字风洞” 平台的测评数据显示,DeepSeek - R1 在综合测评成绩、智能度和匹配度等方面均领先于 Llama3.1、GPT - 4o - Mini 等主流 AI 大模型。在数据运算、复杂推理场景下,DeepSeek - R1 较 Llama3.1 解决问题的能力更强;在正确回复一致度方面,DeepSeek - R1 也高于 GPT - 4o - Mini,表现得更加稳定可靠。
DeepSeek 模型的成本优势也十分显著。据官方技术论文披露,V3 模型的总训练成本为 557.6 万美元,而与之性能相当的 GPT - 4o 等模型的训练成本约为 1 亿美元。DeepSeek - R1 的 API 服务定价也极具竞争力,为每百万输入 tokens 1 元(缓存命中)/4 元(缓存未命中),每百万输出 tokens 16 元,均大幅低于同性能下海外主流模型价格。这种低成本优势,使得更多的企业和开发者能够使用 DeepSeek 模型进行 AI 应用的开发和创新,降低了 AI 技术的应用门槛。

此外,DeepSeek 模型的开源与生态建设也为其发展注入了强大的动力。它以相对开源的方式发布,允许研究人员和开发人员自由访问和修改代码,这种开源精神促进了 AI 技术的共享与创新。全球知名开源平台抱抱脸公司等多个团队已宣布复现了 DeepSeek - R1 的训练过程,吸引了众多开发者参与到模型的优化和应用拓展中。同时,国内多家 GPU 企业纷纷宣布支持 DeepSeek,加速完成国产 GPU 与 DeepSeek 的适配,如华为昇腾与硅基流动联合发布了基于昇腾云服务的 DeepSeek R1/V3 推理服务,通过软硬协同优化,实现了与全球高端 GPU 部署模型效果持平的推理性能。沐曦、天数智芯、摩尔线程、海光信息、云天励飞等企业也完成了与 DeepSeek 的适配工作,推动了国产 GPU 在 AI 领域的应用和发展,进一步完善了 DeepSeek 的生态体系。
三、平台初体验:开启蓝耘之旅
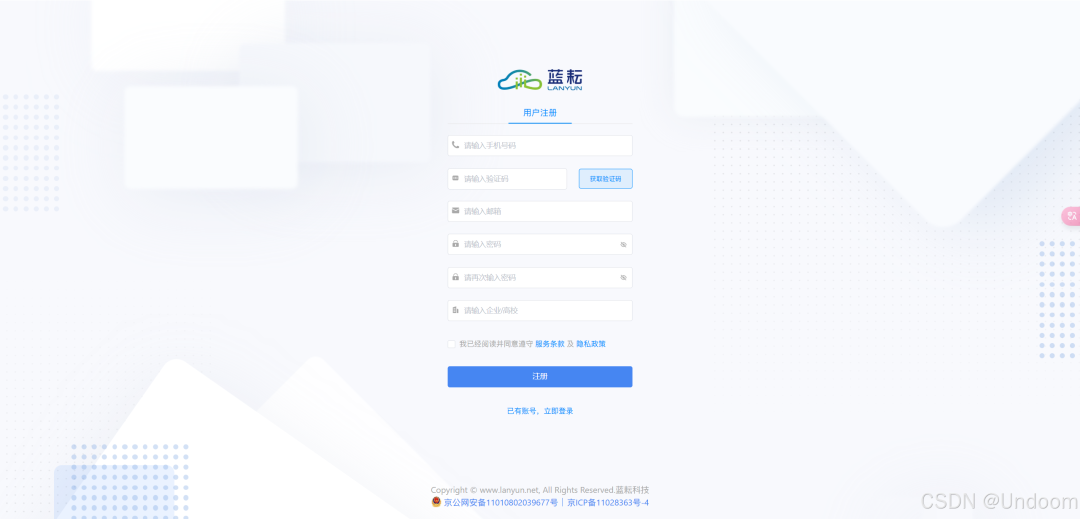
1.注册与登录
在使用蓝耘智算平台运行 DeepSeek 模型之前,首先需要完成注册与登录的步骤。这是进入平台、获取算力资源的基础,每一个环节都至关重要。
打开你常用的浏览器,在地址栏中输入蓝耘智算平台的官方网址,然后按下回车键,即可进入平台的官方首页。此时,你会看到一个充满科技感与现代设计风格的页面,展示着平台的各项优势与服务。在首页的显著位置,通常位于页面右上角,你会找到 “注册” 按钮。这个按钮的设计醒目,以吸引用户的注意力,引导新用户开启注册流程。点击该按钮后,页面将跳转到注册页面。
在注册页面,首先需要填写一个有效的邮箱地址。这个邮箱将作为你在平台的登录账号之一,同时也是接收平台通知、密码找回等重要信息的渠道。确保你填写的邮箱是你经常使用且能够正常接收邮件的,例如你的工作邮箱或常用的个人邮箱。接着,设置一个强密码,长度至少为 8 位,包含字母(大小写)、数字和特殊字符,如 “Abc@123456”。强密码能够有效保护你的账号安全,防止被他人轻易破解。之后,再次输入刚才设置的密码,以确保密码输入的准确性。这一步骤是为了避免因密码输入错误而导致后续登录或使用过程中出现问题。为了验证你是真实用户而非机器人,平台会提供一个验证码输入框。验证码通常是由数字和字母组成的字符串,显示在输入框旁边的图片中。仔细观察图片中的验证码,然后在输入框中准确输入。完成上述信息填写后,点击 “注册” 按钮,提交注册信息。
提交信息后,你会收到一封验证邮件或短信。如果是验证邮件,登录到你注册时填写的邮箱,找到来自蓝耘智算平台的验证邮件,点击邮件中的验证链接,按照指引完成验证,即可成功注册。如果是验证短信,在手机上查看短信内容,按照短信中的提示进行验证操作。注册成功后,返回平台首页,点击 “登录”。输入注册时使用的邮箱或手机号码以及密码,即可登录到蓝耘智算平台,开启你的 AI 探索之旅。
2.资源申请
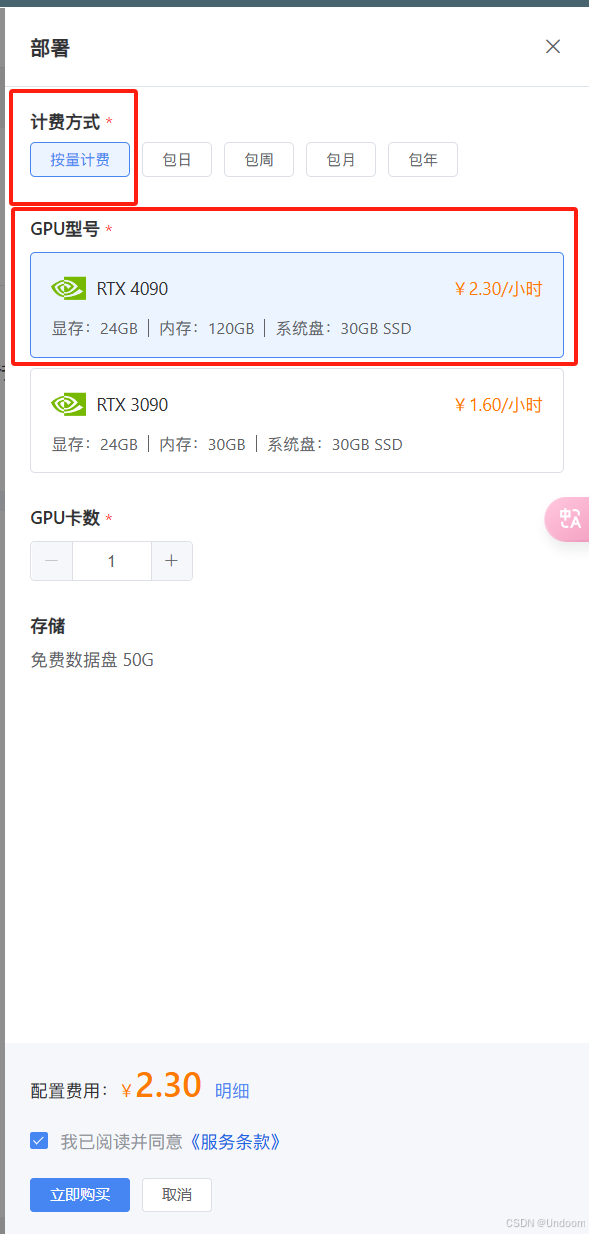
登录成功后,在控制台中找到 “资源申请” 板块,这是获取运行 DeepSeek 模型所需计算资源的关键步骤。由于 DeepSeek 模型在训练和推理过程中可能对算力要求较高,因此需根据任务规模申请合适的 GPU 资源。例如,若你只是进行小型数据集测试,可选择基础款 GPU,如 NVIDIA T4,它具有一定的计算能力,足以应对一些简单的模型测试任务,能够帮助你初步了解 DeepSeek 模型的性能和特点。若处理大规模数据,如进行大规模的文本语料训练或复杂的图像识别任务,应申请性能更强的 GPU,如 NVIDIA A100 ,其强大的计算核心和高速的内存带宽,能够显著加速模型的训练和推理过程,大大缩短任务执行时间。
在申请资源时,还需要设置资源使用时长。初次使用建议先申请较短时长,如 2-3 小时,这样可以在熟悉平台操作和模型运行流程的同时,避免因长时间占用资源而产生不必要的费用。在熟悉流程后,你可以根据实际任务需求按需调整使用时长。例如,对于一些需要长时间运行的模型训练任务,你可以申请数天甚至数周的使用时长;而对于一些简单的推理任务,可能只需要几个小时的资源使用时间即可完成。
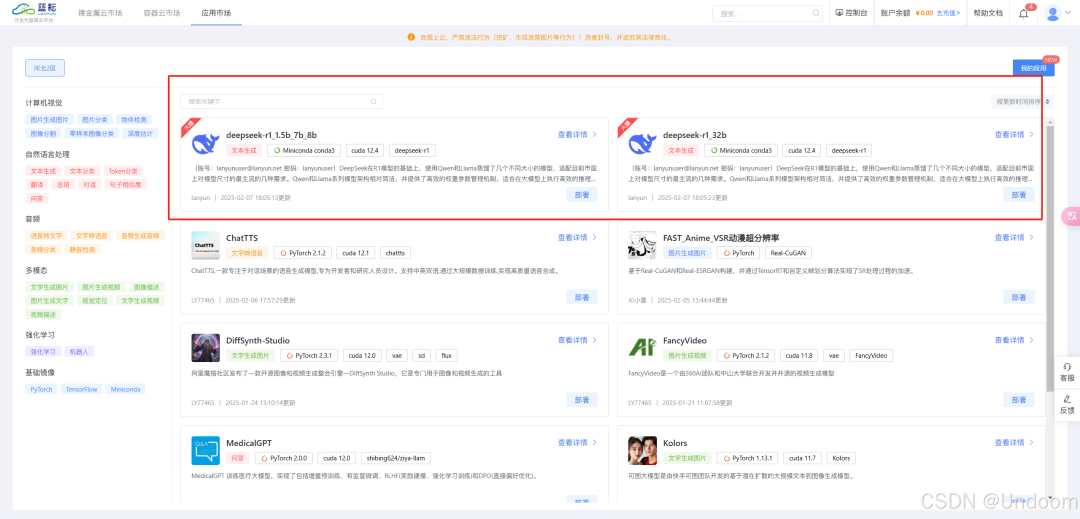
填写申请理由也是必不可少的环节,简要说明使用 DeepSeek 模型进行的任务,如 “基于 DeepSeek 模型的简单图像分类测试”“利用 DeepSeek 模型进行自然语言处理中的情感分析研究” 等。清晰明确的申请理由有助于平台更好地了解你的需求,从而更合理地分配资源,同时也方便平台审核你的申请。提交申请后,耐心等待审核通过。审核时间通常会根据平台的繁忙程度和申请数量而有所不同,一般在数小时到一天之内会有审核结果通知。在等待审核期间,你可以进一步了解平台的功能和 DeepSeek 模型的相关知识,为后续的使用做好充分准备。
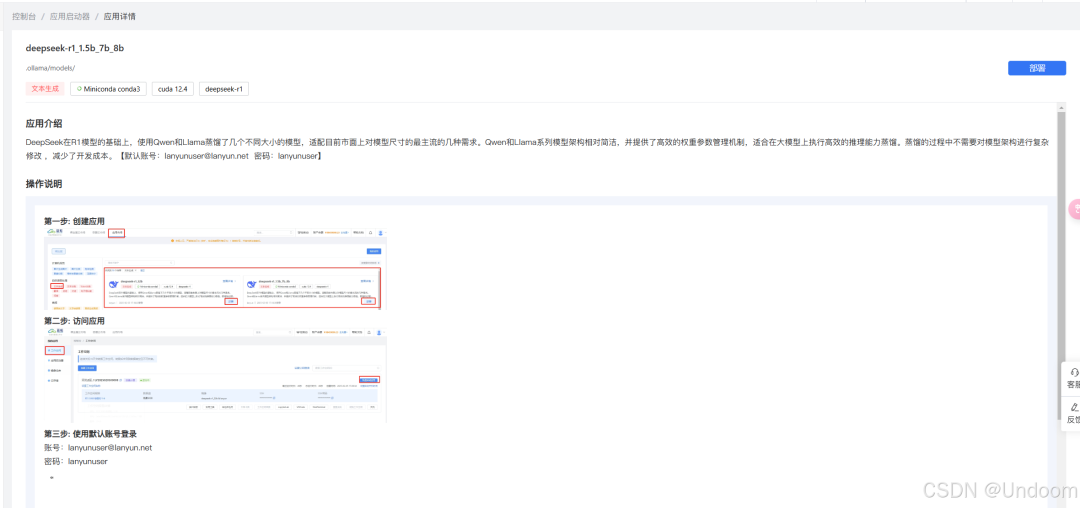
四、环境搭建:为 DeepSeek 筑牢根基
1.创建虚拟环境
在蓝耘智算平台提供的强大计算资源中,为了避免不同项目之间的依赖冲突,使用 Anaconda 或 Miniconda 创建 Python 虚拟环境是一个非常好的选择。如果你还没有安装 Anaconda 或 Miniconda,可以从它们的官方网站下载对应系统的安装包进行安装。安装完成后,打开终端,以 Anaconda 为例,输入以下命令查看当前已有的虚拟环境:
conda env list接下来,创建一个新的虚拟环境,这里我们将其命名为 “deepseek_env”,并指定 Python 版本为 3.8(你可以根据实际需求调整版本号):
conda create -n deepseek_env python=3.8在创建过程中,系统会提示你确认是否继续安装,输入 “y” 并回车即可。创建完成后,激活这个虚拟环境:
conda activate deepseek_env此时,你会发现终端的命令提示符前面多了 “(deepseek_env)” 字样,这就表示你已经成功进入了新创建的虚拟环境。
2.安装依赖包
DeepSeek 模型的运行依赖于一系列深度学习框架和工具。首先是深度学习框架 PyTorch,它是 DeepSeek 模型训练和推理的核心框架。此外,还需要安装 numpy、pandas 等常用的 Python 库,用于数值计算和数据处理。以安装 PyTorch 为例,由于不同的 CUDA 版本需要对应不同的 PyTorch 版本,这里给出几个常见的示例:
如果你的 CUDA 版本是 11.7,使用 pip 安装 PyTorch 的命令如下:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117如果你的 CUDA 版本是 11.3,使用 conda 安装 PyTorch 的命令如下:
conda install pytorch==1.9.0 torchvision==0.10.0 torchaudio==0.9.0 cudatoolkit=11.3 -c pytorch -c conda-forge安装完 PyTorch 后,再安装其他依赖包,例如安装 numpy 和 pandas,可以使用以下命令:
pip install numpy pandas安装过程中,请耐心等待,根据网络情况,安装时间可能会有所不同。安装完成后,你可以使用pip list命令查看已安装的包及其版本,确保所有依赖包都已正确安装。
3.获取 DeepSeek 模型
要在蓝耘智算平台上使用 DeepSeek 模型,需要先从官方指定代码仓库获取模型代码。DeepSeek 模型的代码通常托管在 GitHub 上,你可以使用 git clone 命令将代码克隆到本地。首先,确保你已经安装了 git 工具,如果没有安装,可以通过系统的包管理器进行安装,例如在 Ubuntu 系统中,可以使用以下命令安装:
sudo apt-get install git安装完成后,在终端中输入以下命令克隆 DeepSeek 模型代码仓库(假设仓库地址为https://github.com/deepseek-ai/DeepSeek):
git clone https://github.com/deepseek-ai/DeepSeek执行上述命令后,git 会将 DeepSeek 模型的代码下载到当前目录下的 “DeepSeek” 文件夹中。进入该文件夹,你可以看到模型的源代码、配置文件以及相关的文档等内容。
cd DeepSeek通过上述步骤,你已经成功获取了 DeepSeek 模型的代码,接下来就可以根据模型的文档和需求,对模型进行进一步的配置和使用了。
五、实战操作:让 DeepSeek 为你所用

1.数据准备
在使用 DeepSeek 模型之前,首先要明确你的任务类型,因为不同的任务对数据的要求和处理方式也不同。如果是文本分类任务,如判断一篇新闻是属于政治、经济还是娱乐等类别,就需要收集大量对应类别的文本数据;若是问答系统,那数据则应该包含问题和对应的准确答案。收集数据的途径多种多样,公开数据集是一个很好的起点,像知名的 IMDB 影评数据集,包含了大量电影评论及情感倾向标注,非常适合用于文本情感分析任务。也可以从网络爬虫获取相关数据,比如爬取各大论坛上关于某一产品的评价,用于产品口碑分析。
收集到的数据往往是原始且杂乱的,需要进行清洗与预处理。对于文本数据,常见的操作包括去除 HTML 标签、特殊字符、停用词(如 “的”“了”“在” 等对语义理解帮助不大的词)。例如,使用 Python 的re库去除 HTML 标签,代码如下:
import re
def remove_html_tags(text):
clean = re.compile('<.*?>')
return re.sub(clean, '', text)
text_with_html = "<p>这是一段包含 <a href='#'>链接</a> 的文本</p>"
cleaned_text = remove_html_tags(text_with_html)
print(cleaned_text)处理完后,还要进行数据加载与批量处理。在 DeepSeek 模型中,通常使用torch.utils.data.Dataset和torch.utils.data.DataLoader来实现。首先,创建一个自定义的数据集类,继承自Dataset,并重写__init__、__len__和__getitem__方法。假设我们有一个文本分类任务,数据存储在一个 CSV 文件中,第一列是文本,第二列是标签,代码示例如下:
import torch
from torch.utils.data import Dataset
import pandas as pd
class TextDataset(Dataset):
def __init__(self, csv_file):
self.data = pd.read_csv(csv_file)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
text = self.data.iloc[idx, 0]
label = self.data.iloc[idx, 1]
return text, label
dataset = TextDataset('data.csv')
dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True)这样就可以方便地按批次加载数据,提高训练效率。
2.模型加载与推理
在蓝耘智算平台上,可以使用transformers库来本地加载 DeepSeek 模型。首先,确保已经安装了transformers库,若未安装,可使用pip install transformers命令进行安装。加载模型的代码如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "deepseek-ai/DeepSeek-R1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)加载完成后,对输入数据进行预处理。以文本为例,需要将文本转换为模型能够接受的格式,即 token 序列。代码如下:
input_text = "请介绍一下人工智能的发展历程"
inputs = tokenizer(input_text, return_tensors="pt")接下来,使用模型进行推理。调用模型的generate方法,生成相应的输出:
outputs = model.generate(**inputs)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)除了本地推理,还可以通过 API 调用实现推理。如果蓝耘智算平台提供了 DeepSeek 模型的 API 服务,首先需要获取 API 密钥,然后按照平台提供的 API 文档进行请求。以 Python 的requests库为例,假设 API 地址为https://api.lanyun.com/deepseek/inference,代码如下:
import requests
api_key = "your_api_key"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
data = {
"input_text": "请介绍一下人工智能的发展历程"
}
response = requests.post("https://api.lanyun.com/deepseek/inference", headers=headers, json=data)
if response.status_code == 200:
result = response.json()
generated_text = result["generated_text"]
print(generated_text)
else:
print(f"请求失败,状态码: {response.status_code}")3.模型训练与优化
如果需要对 DeepSeek 模型进行微调训练,以适应特定的任务,首先要自定义训练流程。在 PyTorch 中,可以使用torch.nn.Module来定义训练过程。假设我们要在前面的文本分类任务上微调 DeepSeek 模型,定义一个简单的训练函数:
import torch
import torch.optim as optim
def train_model(model, dataloader, epochs, learning_rate):
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model.train()
for epoch in range(epochs):
running_loss = 0.0
for i, (texts, labels) in enumerate(dataloader):
optimizer.zero_grad()
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
outputs = model(**inputs)
logits = outputs.logits
loss = criterion(logits.view(-1, logits.size(-1)), labels.view(-1))
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(dataloader)}')
# 调用训练函数
train_model(model, dataloader, epochs=3, learning_rate=1e-5)在训练过程中,调整超参数是优化模型性能的关键。常见的超参数包括学习率、批次大小、训练轮数等。学习率决定了模型在训练过程中参数更新的步长,过大的学习率可能导致模型无法收敛,过小则会使训练速度过慢。可以通过学习率调度器来动态调整学习率,如torch.optim.lr_scheduler.StepLR,它会在指定的步数后降低学习率。批次大小影响每次训练时输入模型的数据量,较大的批次大小可以加快训练速度,但可能会占用更多内存,需要根据实际情况进行调整。
4.模型部署与应用
将训练好的模型部署到蓝耘平台上,以便在实际应用中使用。在蓝耘智算平台的控制台中,找到模型部署相关的功能模块。首先,上传训练好的模型文件,包括模型的权重文件和配置文件。然后,根据平台的提示,配置模型的运行环境,如选择合适的 GPU 资源、设置内存限制等。配置完成后,提交部署请求,等待平台完成模型的部署。部署成功后,平台会提供一个访问接口,通过这个接口就可以调用模型进行推理。
以智能问答系统为例,展示如何在实际场景中使用 DeepSeek 模型。在智能问答系统中,用户输入问题,系统通过调用部署在蓝耘平台上的 DeepSeek 模型,获取答案并返回给用户。假设我们使用 Flask 框架搭建一个简单的 Web 应用来实现这个功能,代码如下:
from flask import Flask, request, jsonify
from transformers import AutoModelForCausalLM, AutoTokenizer
app = Flask(__name__)
model_name = "deepseek-ai/DeepSeek-R1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
@app.route('/question_answer', methods=['POST'])
def question_answer():
data = request.get_json()
question = data['question']
inputs = tokenizer(question, return_tensors="pt")
outputs = model.generate(**inputs)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return jsonify({'answer': answer})
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5000)通过这个简单的应用,就可以将 DeepSeek 模型集成到实际的业务场景中,为用户提供智能问答服务。
六、避坑指南:常见问题与解决方法
1.环境搭建方面
在环境搭建过程中,依赖包版本不兼容是一个常见问题。比如,在安装深度学习框架 PyTorch 时,如果选择的版本与 CUDA 版本不匹配,可能会导致无法使用 GPU 加速,或者在模型训练和推理过程中出现错误。以 CUDA 11.7 为例,如果安装的 PyTorch 版本不支持 CUDA 11.7,就会出现类似 “RuntimeError: CUDA error: no kernel image is available for execution on the device” 的错误。解决这个问题,需要仔细查看 PyTorch 官方文档,根据 CUDA 版本选择正确的 PyTorch 安装命令。如前面提到的,CUDA 11.7 对应的安装命令为pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117。
此外,网络问题也可能导致依赖包安装失败。在安装过程中,如果网络不稳定或者下载源速度较慢,可能会出现安装中断或超时的情况。此时,可以尝试更换下载源,比如使用国内的镜像源,如清华大学的镜像源Simple Index。在安装命令中添加-i参数指定镜像源,如pip install -i Simple Index numpy,这样可以提高下载速度,确保依赖包顺利安装。
2.模型加载与推理方面
模型加载失败的原因可能有多种,其中模型文件路径错误是一个常见原因。如果在代码中指定的模型文件路径不正确,或者模型文件本身损坏,就会导致模型无法加载,出现类似 “FileNotFoundError: [Errno 2] No such file or directory” 的错误。解决这个问题,需要仔细检查模型文件的路径是否正确,确保模型文件已经成功下载并放置在指定路径下。同时,可以使用文件管理工具查看模型文件是否存在,以及文件的完整性。
推理结果异常也是一个需要关注的问题。有时候,模型推理得到的结果可能与预期不符,比如生成的文本逻辑混乱、答案错误等。这可能是由于输入数据的格式不正确,或者模型的参数设置不合理导致的。对于输入数据格式问题,需要仔细检查数据预处理的步骤,确保输入数据符合模型的要求。以文本数据为例,需要确保文本已经正确地进行了分词、编码等操作。对于模型参数设置问题,可以尝试调整模型的超参数,如温度(temperature)、最大生成长度(max_new_tokens)等。温度参数控制着生成文本的随机性,取值范围一般在 0 - 1 之间,值越小生成的文本越确定,值越大生成的文本越随机。如果生成的文本过于单调,可以适当提高温度参数;如果生成的文本过于随机、逻辑混乱,可以降低温度参数。最大生成长度参数则限制了生成文本的长度,如果生成的文本长度不符合预期,可以调整这个参数。
3.数据处理与准备方面
在数据处理过程中,数据格式错误是一个常见问题。比如,在将数据加载到模型中时,如果数据格式与模型期望的格式不一致,就会导致数据加载失败或者模型运行错误。以图像数据为例,如果模型期望的输入是 RGB 格式的图像,而实际输入的是灰度图像,就会出现问题。解决这个问题,需要在数据预处理阶段,将数据转换为模型期望的格式。可以使用相应的图像处理库,如 OpenCV、PIL 等,对图像进行格式转换。例如,使用 PIL 库将灰度图像转换为 RGB 图像的代码如下:
from PIL import Image
# 打开灰度图像
img = Image.open('gray_image.jpg')
# 转换为RGB图像
rgb_img = img.convert('RGB')数据缺失也是一个需要处理的问题。如果数据集中存在缺失值,可能会影响模型的训练和预测效果。对于数值型数据,可以使用均值、中位数等方法进行填充;对于文本数据,可以使用特殊标记(如 “”)进行填充。以 Python 的 pandas 库为例,使用均值填充数值型数据缺失值的代码如下:
import pandas as pd
# 读取包含缺失值的数据
data = pd.read_csv('data_with_missing.csv')
# 使用均值填充数值型数据缺失值
data.fillna(data.mean(), inplace=True)4.模型训练方面
模型训练过程中,训练中断是一个令人头疼的问题。这可能是由于硬件故障、网络问题、内存不足等原因导致的。如果是硬件故障,如 GPU 过热、硬件损坏等,需要检查硬件设备,确保其正常运行。可以使用硬件监控工具,如 NVIDIA 的 GPU-Z,查看 GPU 的温度、使用率等参数,及时发现硬件问题。如果是网络问题,可能会导致数据加载失败或者分布式训练时节点之间通信中断。此时,需要检查网络连接,确保网络稳定。可以使用 ping 命令测试网络连通性,或者使用网络监控工具,如 Wireshark,分析网络流量。如果是内存不足导致的训练中断,可以尝试减少模型的批处理大小(batch size),或者增加系统内存。批处理大小是指每次训练时输入模型的数据量,减小批处理大小可以降低内存占用,但可能会增加训练时间。
过拟合也是模型训练中常见的问题。当模型在训练集上表现很好,但在验证集或测试集上表现很差时,就可能出现了过拟合。过拟合的原因通常是模型过于复杂,或者训练数据量不足。为了解决过拟合问题,可以采取以下措施:增加训练数据,通过数据增强(如图像的旋转、缩放、裁剪等)、收集更多的数据等方式,增加数据的多样性和数量,使模型能够学习到更广泛的特征;使用正则化方法,如 L1 和 L2 正则化,在损失函数中添加正则化项,惩罚模型的复杂度,防止模型过度拟合;采用 Dropout 技术,在模型训练过程中随机丢弃一部分神经元,减少神经元之间的协同适应,降低模型的复杂度。以 PyTorch 为例,使用 L2 正则化的代码如下:
import torch
import torch.optim as optim
# 定义模型
model = torch.nn.Linear(10, 1)
# 定义损失函数
criterion = torch.nn.MSELoss()
# 定义优化器,使用L2正则化(weight_decay参数)
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=0.0001)5.成本与资源管理方面
在使用蓝耘智算平台资源时,合理控制成本是非常重要的。首先,要根据任务的实际需求选择合适的算力资源。如果任务对算力要求不高,却选择了高性能的 GPU 资源,就会造成资源浪费和成本增加。例如,对于一些简单的文本处理任务,使用 NVIDIA T4 GPU 就足够了,而不需要选择更高级的 NVIDIA A100 GPU。可以通过对任务进行性能测试和分析,确定所需的算力资源级别。在训练模型之前,可以先使用小规模的数据进行测试,观察不同算力资源下模型的运行时间和性能表现,从而选择性价比最高的资源配置。
此外,优化资源利用效率也可以降低成本。比如,在模型训练过程中,可以合理调整批处理大小、训练轮数等参数,提高训练效率,减少资源占用时间。同时,要及时释放不再使用的资源,避免资源长时间闲置。在使用完蓝耘智算平台的计算实例后,要及时关闭实例,避免不必要的费用产生。蓝耘智算平台通常提供了资源监控和管理功能,可以通过这些功能实时查看资源的使用情况,及时发现并解决资源浪费的问题。还可以根据平台提供的计费信息,分析资源使用成本的构成,找出可以优化的部分,进一步降低成本。
七、DeepSeek相关的代码示例
1.Python SDK调用示例
配置API,进行基础对话和推理模型示例调用。
import openai
# 配置API
openai.api_key = "YOUR_API_KEY"
openai.api_base = "https://api.deepseek.com/v1"
# 基础对话示例
def basic_chat():
try:
response = openai.ChatCompletion.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "你好,请介绍一下你自己"}
]
)
print(response.choices[0].message.content)
except Exception as e:
print(f"Error: {e}")
# 推理模型示例
def reasoning_chat():
try:
response = openai.ChatCompletion.create(
model="deepseek-reasoner",
messages=[
{"role": "user", "content": "请解决这个问题:一个小球从10米高度自由落下,每次弹起高度为原高度的一半,问第三次落地时共经过多少米?"}
]
)
print(response.choices[0].message.content)
except Exception as e:
print(f"Error: {e}")
if __name__ == "__main__":
basic_chat()
reasoning_chat()2.使用DeepSeek R1和Ollama开发RAG系统
利用PDFPlumberLoader提取PDF文本,SemanticChunker进行文档语义分块,HuggingFaceEmbeddings生成文本嵌入,FAISS构建向量数据库,Ollama配置DeepSeek R1模型,以及PromptTemplate定义提示模板,组装RAG处理链。
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
# 创建Streamlit文件上传组件
uploaded_file = st.file_uploader("上传PDF文件", type="pdf")
if uploaded_file:
# 临时存储PDF文件
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# 加载PDF内容
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
# 初始化语义分块器
text_splitter = SemanticChunker(
HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
)
# 执行分块操作
documents = text_splitter.split_documents(docs)
# 生成文本嵌入
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# 配置检索器
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
# 初始化本地模型
llm = Ollama(model="deepseek-r1:1.5b")
# 定义提示模板
prompt_template = """
根据以下上下文:
{context}
问题:{question}
回答要求:
1. 仅使用给定上下文
2. 不确定时回答"暂不了解"
3. 答案控制在四句话内
最终答案:
"""
QA_PROMPT = PromptTemplate.from_template(prompt_template)
# 创建LLM处理链
llm_chain = LLMChain(llm=llm, prompt=QA_PROMPT)
# 配置文档组合模板
document_prompt = PromptTemplate(
template="上下文内容:\n{page_content}\n来源:{source}",
input_variables=["page_content", "source"]
)
# 构建完整RAG管道
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
# 创建问题输入框
user_question = st.text_input("输入您的问题:")
if user_question:
with st.spinner("正在生成答案..."):
# 执行查询并显示结果
response = qa(user_question)["result"]
st.success(response)这些代码示例可以帮助您更好地理解和使用DeepSeek,实现各种应用场景。
3.DeepSeek-R1 API来生成文章的大纲
如果您需要使用DeepSeek-R1来撰写文章,可以参考以下代码示例,它展示了如何调用DeepSeek-R1 API来生成文章的大纲,包括引言、主体部分和结论。您可以根据这个大纲来撰写文章的结尾部分,确保它与文章的主要内容和观点相呼应。
import requests
# 填写你的 API Key
API_KEY = "sk-你的密钥"
url = "https://api.deepseek.com/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
data = {
"model": "deepseek-reasoner", # 指定使用 R1 模型(deepseek-reasoner)
"messages": [
{"role": "system", "content": "你是一个专业的助手"},
{"role": "user", "content": "请帮我生成“中国农业情况”这篇文章的大纲"}
],
"stream": False # 关闭流式传输
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
result = response.json()
print(result['choices'][0]['message']['content']) # 输出大纲内容
else:
print("请求失败,错误码:", response.status_code)请注意,上述代码需要您替换API_KEY为您自己的DeepSeek API密钥。此外,您可能需要根据实际需求调整API的URL、请求头和数据内容。
八、总结与展望
在蓝耘智算平台上使用 DeepSeek 模型,为我们开启了一扇通往人工智能创新应用的大门。从平台的注册登录、资源申请,到环境搭建、模型的加载与推理、训练与优化,再到模型的部署与应用,每一个环节都紧密相扣,共同构成了一个完整的 AI 开发流程。蓝耘智算平台凭借其强大的算力资源、灵活的功能特性以及贴心的服务,为 DeepSeek 模型的运行提供了坚实的保障;而 DeepSeek 模型则以其卓越的性能、创新的技术架构以及丰富的开源生态,为用户带来了无限的创新可能。
通过在蓝耘智算平台上使用 DeepSeek 模型,我们能够更高效地进行自然语言处理、图像识别、智能问答等各类 AI 任务。在实际应用中,无论是企业开发智能客服系统,提高客户服务效率;还是科研机构进行自然语言处理的前沿研究,探索语言的奥秘;亦或是个人开发者开发创新的 AI 应用,满足个性化的需求,蓝耘智算平台和 DeepSeek 模型都能发挥重要的作用。
展望未来,随着人工智能技术的不断发展,蓝耘智算平台和 DeepSeek 模型也将持续演进。蓝耘智算平台有望进一步提升算力,优化资源调度算法,降低使用成本,为用户提供更加高效、便捷、经济的算力服务。同时,平台可能会加强与更多行业的合作,针对不同行业的需求,提供定制化的解决方案,推动人工智能在更多领域的深度应用。
DeepSeek 模型也将不断优化升级,提升性能表现,拓展应用领域。在模型架构方面,可能会进行更多的创新,引入新的技术和算法,进一步提高模型的语言理解和生成能力、逻辑推理能力等。在训练数据方面,会不断扩充数据规模和多样性,涵盖更多领域和语言,使模型具备更广泛的知识储备和更强的泛化能力。在应用领域,DeepSeek 模型可能会在医疗、金融、教育、智能制造等行业发挥更大的作用,如辅助医生进行疾病诊断、为金融机构提供风险评估和投资建议、助力教育机构开展个性化学习、推动制造业实现智能化生产等。
随着技术的进步和应用的拓展,蓝耘智算平台和 DeepSeek 模型将在人工智能领域绽放更加耀眼的光芒,为我们的生活和社会带来更多的创新和变革。

感谢您耐心阅读本文。希望本文能为您提供有价值的见解和启发。如果您对[智算云巅,DeepSeek启航:平台上部署实操秘籍]有更深入的兴趣或疑问,欢迎继续关注相关领域的最新动态,或与我们进一步交流和讨论。让我们共同期待[智算云巅,DeepSeek启航:平台上部署实操秘籍]在未来的发展历程中,能够带来更多的惊喜和突破。
再次感谢,祝您拥有美好的一天!

博主还写了本文相关文章,欢迎大家批评指正:
2、DeepSeek开启程序员副业增收新通道,财富密码大公开!
3、手把手教你在Windows+docker本地部署DeepSeek-R1
蓝耘智算平台注册地址![]() https://cloud.lanyun.net//#/registerPage?promoterCode=0131
https://cloud.lanyun.net//#/registerPage?promoterCode=0131


















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











