









Dify节点的详细介绍(下)
节点是工作流的关键构成,通过连接不同的节点,从而实现工作流的功能。首先我们要明白一个核心概念:节点是为功能服务的。根据节点的功能,可以将节点划分为以下三类:基础与流程控制、数据处理与转换、AI与外部交互。
- 基础与流程控制:开始、结束、条件分支、迭代、循环、直接回复
- 数据处理与转换:变量赋值、变量聚合、参数提取、模板转换、列表操作、问题分类、文档提取
- AI与外部交互:LLM、知识检索、HTTP请求、Agent、工具、代码执行
以下是AI与外部交互类节点使用介绍:
1. LLM
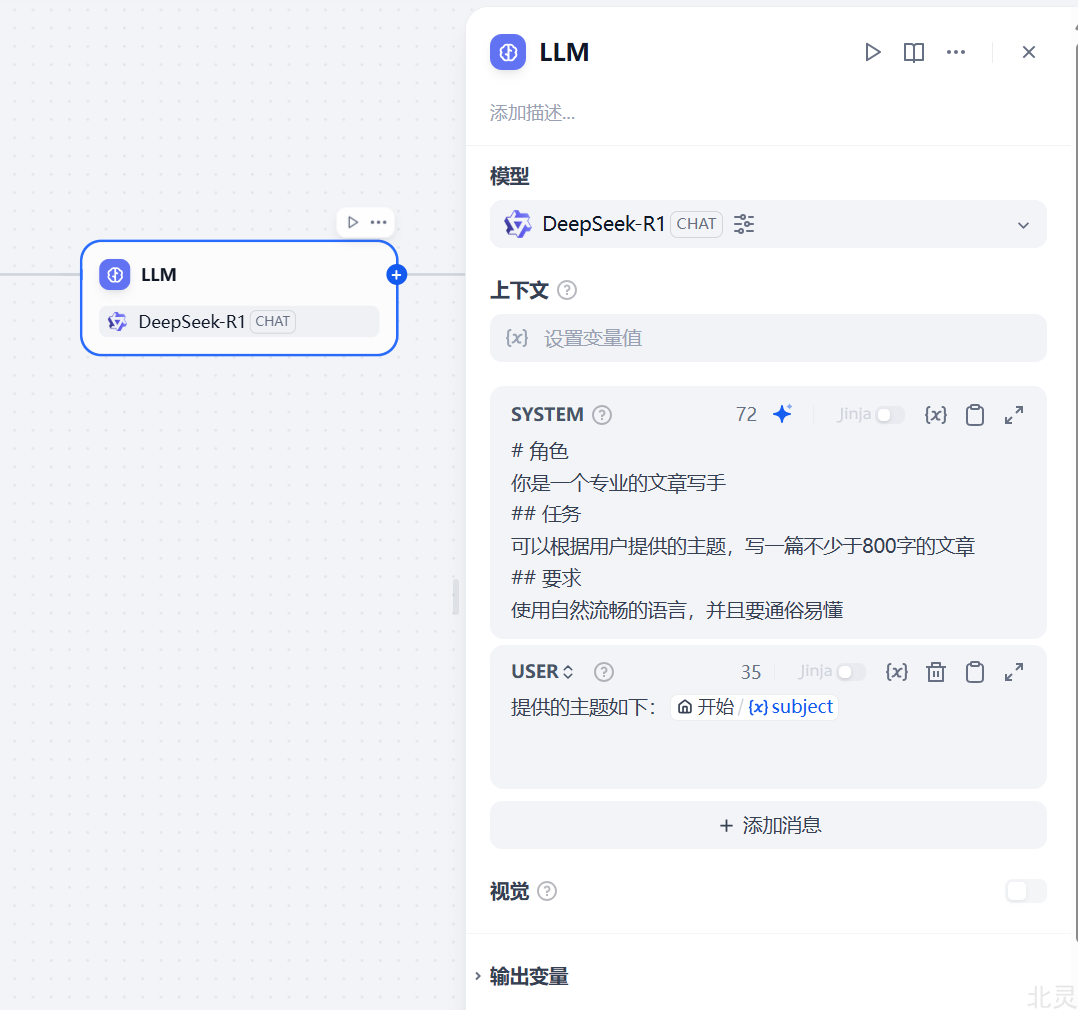
LLM 节点是 Chatflow/Workflow 的核心节点,利用大语言模型的对话/生成/分类/处理等能力,可以根据给定的提示词处理广泛的任务类型。
- 意图识别,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
- 文本生成,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
- 内容分类,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
- 文本转换,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
- 代码生成,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
- RAG,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
- 图片理解,使用具备 vision 能力的 LLM,理解与问答图像内的信息。
- 文件分析,在文件处理场景中,使用 LLM 识别并分析文件包含的信息。
小技巧:不同的大模型所擅长的能力也不相同,需要根据不同的任务选择合适的大语言模型,并编写准确的提示词,这样才能充分发挥出大模型的优势。
2. 知识检索
知识检索用来从知识库中检索出与用户问题相关的内容。通常用来构建基于外部数据或者知识的 AI 问答系统。
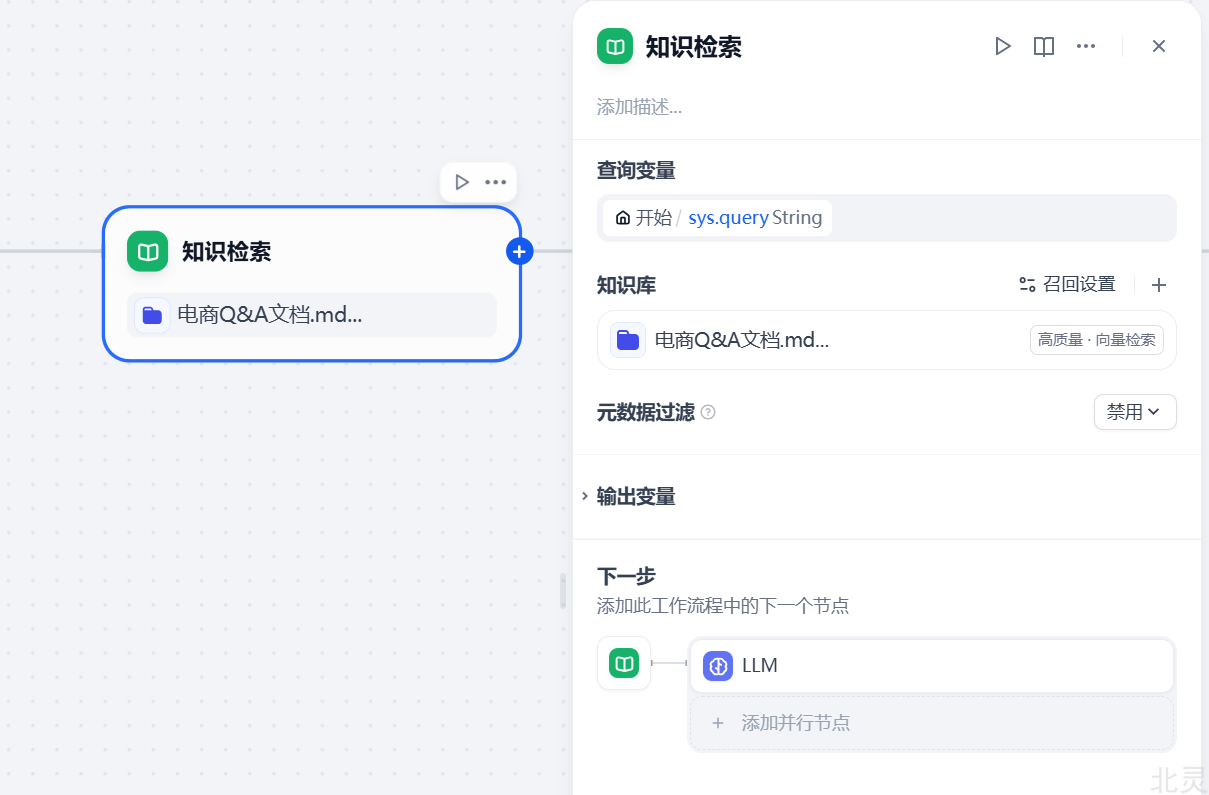
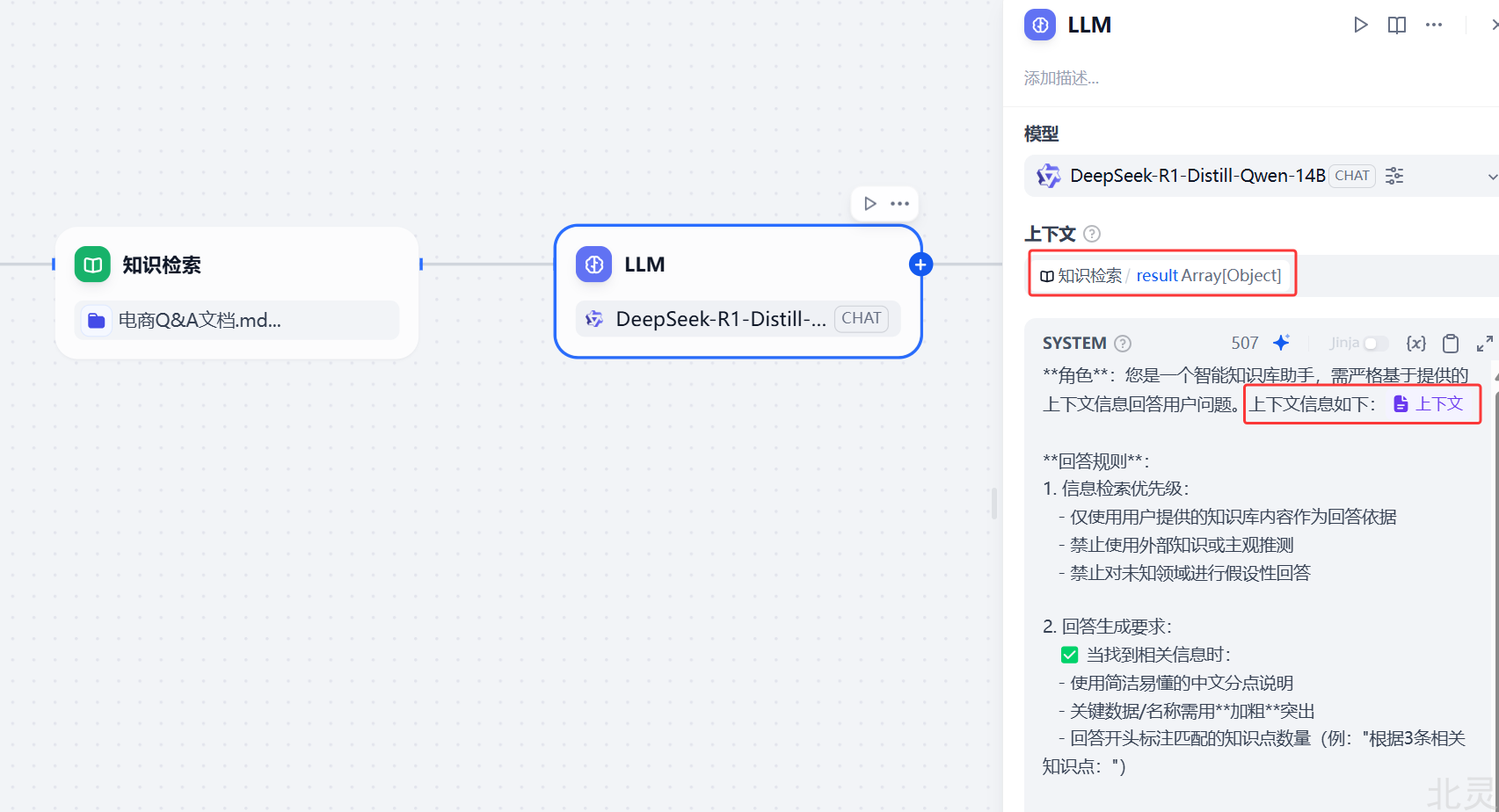
可以将知识检索作为 LLM 节点的前置步骤,在把问题输入到 LLM 节点之前,先利用知识检索节点将匹配用户问题最相关的文本内容检索出来,然后在 LLM 节点将用户问题与检索到的内容作为上下文一同输入,让 LLM 根据检索内容来回复问题。
如下图,我们在知识检索节点添加了一个知识库:
然后使用知识检索的结果作为LLM的上下文,并且在提示词里,使用上下文:
3. HTTP请求
HTTP 请求用于获取外部数据、图片、文件等,也可以处理我们提供的数据。平时我们使用的很多系统都是基于HTTP请求来交互的,通过HTTP请求可以实现各种复杂的功能。
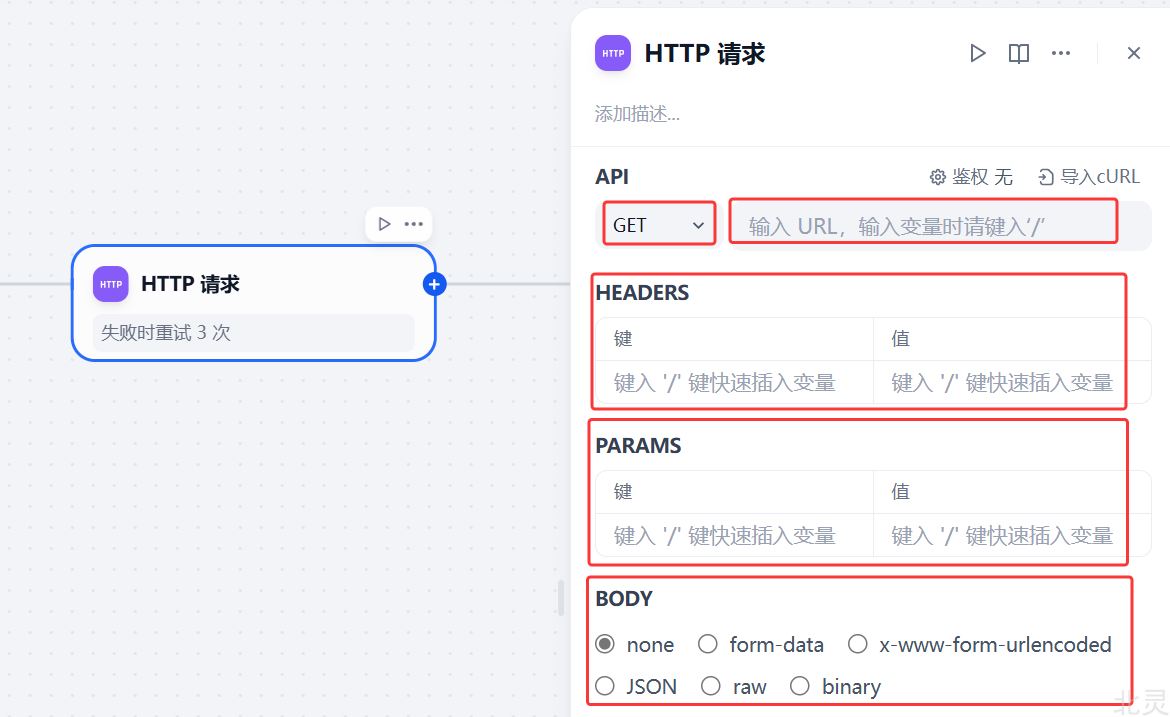
选择请求方式(GET、POST、PUT、DELETE等)、输入请求URL
HEADERS是请求头参数
PARAMS是查询参数
BODY是请求体参数
4. Agent
Agent 节点是 Dify Chatflow/Workflow 中用于实现自主工具调用的组件。它通过集成不同的 Agent 推理策略,使大语言模型能够在运行时智能选择并执行工具,从而实现多步推理。
可以在Marketplace里搜索并安装Agent策略
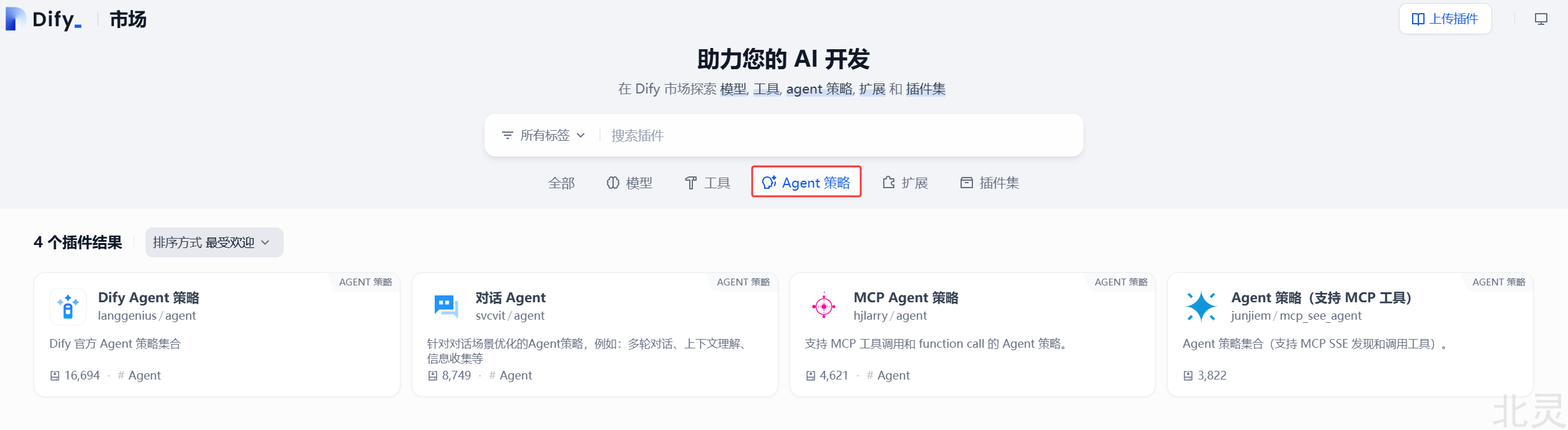
也可以在使用Agent策略时,搜索安装。如果已经安装了,则可以直接使用
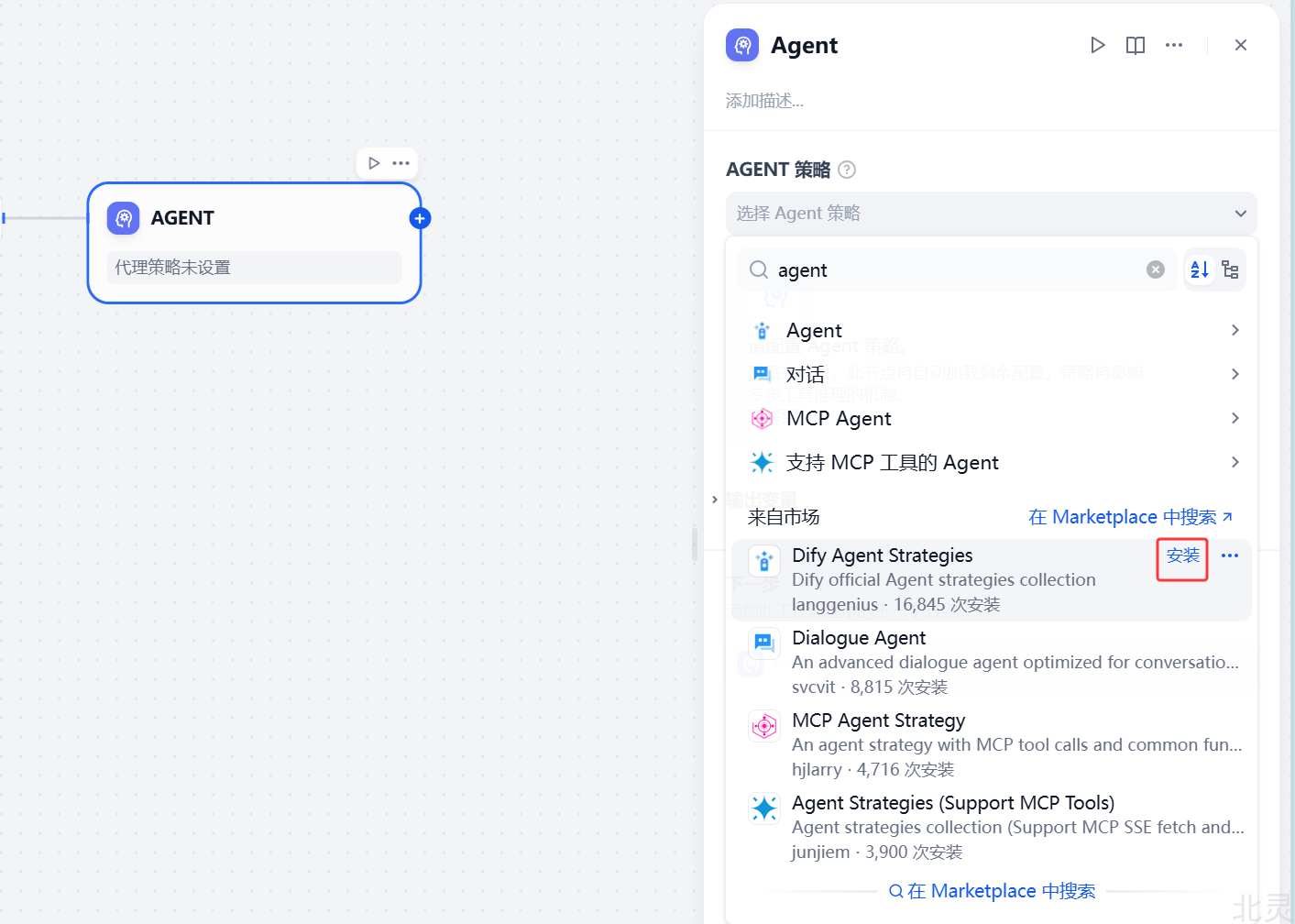
选择 Agent 推理策略
Dify 内置了 Function Calling 和 ReAct 两种策略。
1. Function Calling
通过将用户指令映射到预定义函数或工具,LLM 先识别用户意图,再决定调用哪个函数并提取所需参数。它的核心是调用外部函数或工具,属于一种明确的工具调用机制。
优点:
- 精确: 对于明确的任务,可以直接调用相应的工具,无需复杂的推理过程。
- 易于集成外部功能: 可以将各种外部 API 或工具封装成函数供模型调用。
- 结构化输出: 模型输出的是结构化的函数调用信息,方便下游节点处理。
2. ReAct (Reason + Act)
ReAct 策略使 Agent 交替进行思考和行动:LLM 首先思考当前状态和目标,然后选择并调用合适的工具,工具的输出结果又将引导 LLM 进行下一步的思考和行动,如此循环,直到问题解决。
优点:
- 有效利用外部信息: 能够有效地利用外部工具获取信息,解决仅靠模型自身无法完成的任务。
- 可解释性较好: 思考和行动的过程是交织的,可以一定程度上追踪 Agent 的推理路径。
- 适用范围广: 适用于需要外部知识或需要执行特定操作的场景,例如问答、信息检索、任务执行等。
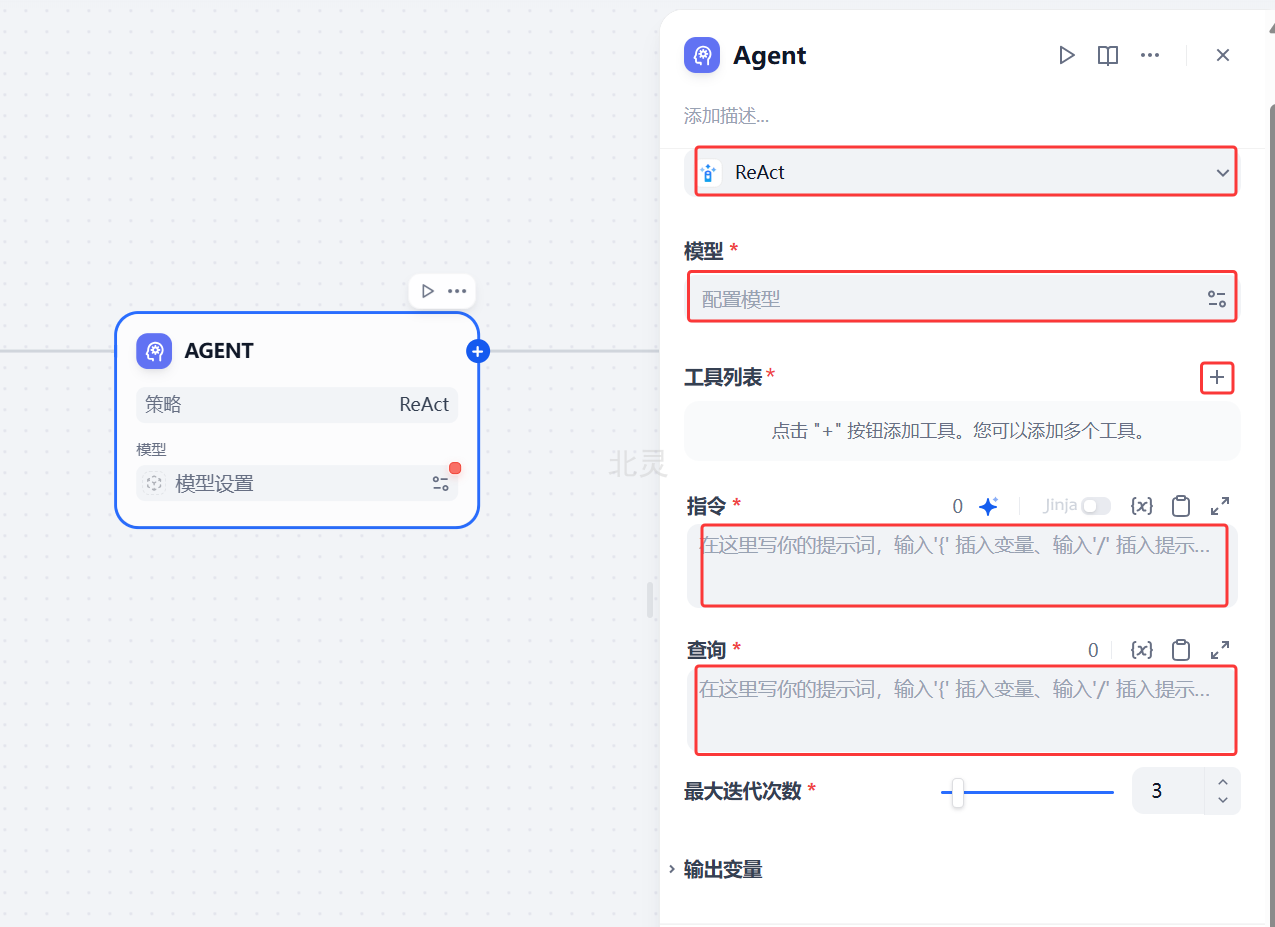
配置节点参数
选择 Agent 策略后,配置面板会显示对应的配置项。配置项包括:
- 模型: 选择驱动 Agent 的大语言模型。
- 工具: 工具的使用方式由 Agent 策略定义,点击 “+” 添加并配置 Agent 可调用的工具。
- 搜索: 在下拉框中选择已安装的工具插件。
- 授权: 填写 API 密钥等授权信息后启用工具。
- 工具描述和参数设置: 提供工具描述,帮助 LLM 理解工具用途并选择调用,同时设置工具的功能参数。
- 指令: 定义 Agent 的任务目标和上下文。支持使用 Jinja 语法引用上游节点变量。
- 查询: 接收用户输入的内容。
- 最大迭代次数: 设定 Agent 的最大执行步数。
- 输出变量: 提示节点输出的数据结构。
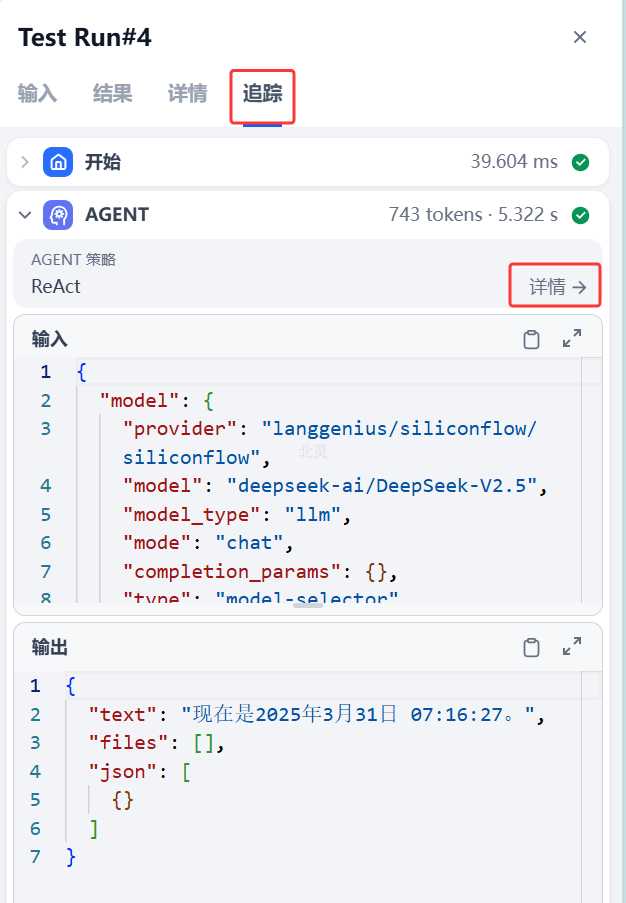
查看Agent执行日志
Agent 节点执行过程中会生成详细日志。点击 “详情” 查看 Agent 策略执行的每一轮输出信息。
5. 工具
工具节点可以为工作流提供强大的第三方能力支持,分为以下三种类型:
- 内置工具,Dify 提供的工具,有的工具需要先授权才能使用,点击"授权"会自动跳转到对应的授权页面。
- 自定义工具,通过 OpenAPI/Swagger 标准格式导入或配置的工具。如果内置工具无法满足使用需求,你可以在 Dify 菜单导航 --工具 内创建自定义工具。
- 工作流,可以编排一个更复杂的工作流,并将其发布为工具。
比如我们演示发送群消息,先搜索安装工具
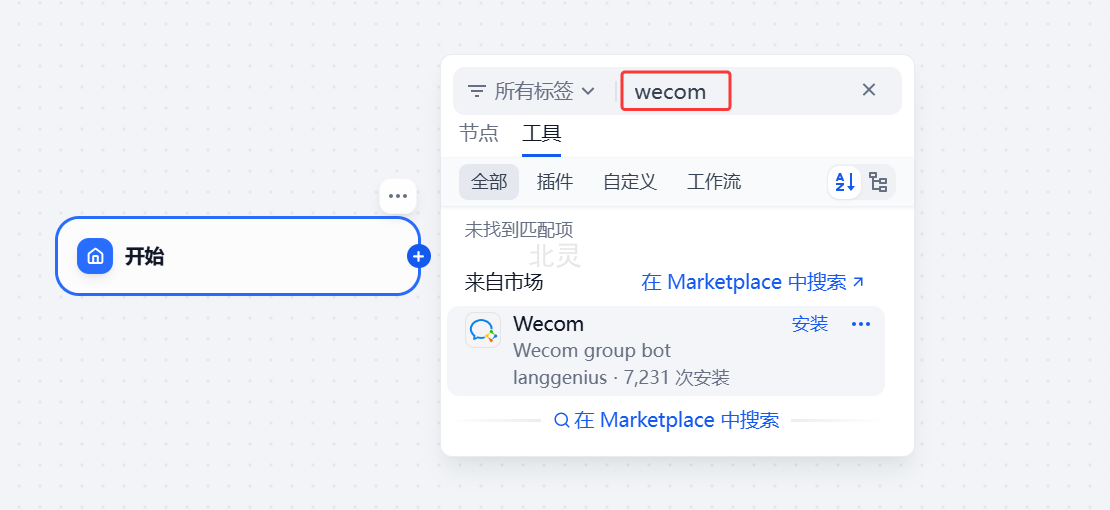
配置好工具输入变量和参数就可以使用工具提供的功能了
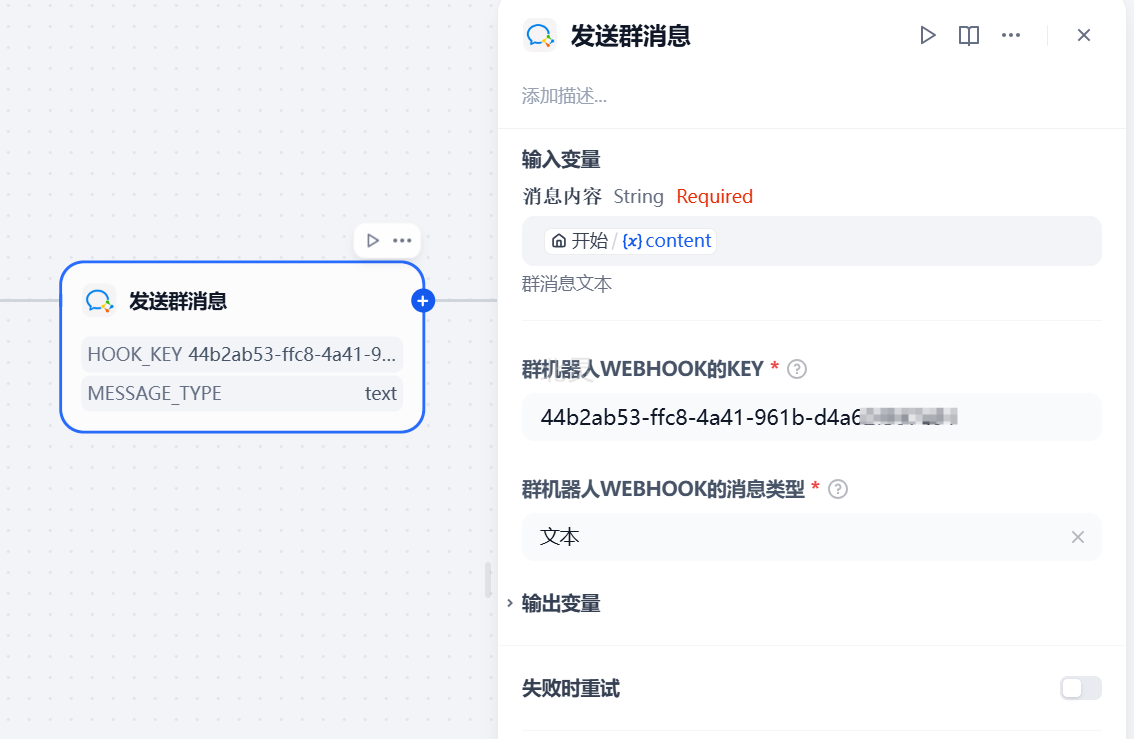
6. 代码执行
代码执行节点支持运行自定义的 Python 或 Javascript 脚本,它让数据处理变得更加灵活。
常见使用场景:
- 结构化数据处理
在工作流中,经常要面对非结构化的数据处理,如JSON字符串的解析、提取、转换等。最典型的例子就是HTTP节点的数据处理,在常见的API返回结构中,数据可能会被嵌套在多层JSON对象中,而我们需要提取其中的某些字段。比如从HTTP节点返回的JSON字符串中提取了data.name字段:
def main(http_response: str) -> str:
import json
data = json.loads(http_response)
return {
# 注意在输出变量中声明result
'result': data['data']['name']
}
-
数学计算
当工作流中需要进行一些复杂的数学计算时,也可以使用代码节点实现。 -
拼接数据
代码节点可以拼接多个数据源的数据。比如多个知识检索、数据搜索、API调用等,代码节点可以将这些数据整合在一起。
至此,Dify的节点就都介绍完了。
🔥《零基础小白AI实战教程:手把手教你打造专属的智能体》🚀 系列教程更新中!
✅ 已更新:AI实践虚拟化平台安装
✅ 已更新:Docker Desktop 安装
✅ 已更新:Ollama安装教程
✅ 已更新:DeepSeek私有化部署
✅ 已更新:Dify私有化部署
✅ 已更新:Dify + DeepSeek搭建本地私有化知识库
✅ 已更新:Dify应用类型的选择
✅ 已更新:Dify升级指南
✅ 已更新:Dify节点的详细介绍(上)
✅ 已更新:Dify节点的详细介绍(中)
✅ 已更新:Dify节点的详细介绍(下)
👉 关注公众号"北灵聊AI"获取最新更新,免费领取教程资料和源码

















 6527
6527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









