







在AIGC大火的今天,很多人都听过和用过ChatGPT和New Bing等聊天交互软件,GPT-4出来后,人们更对它的强大能力感到震惊,决定把相关论文都读一读
GPT-1模型来源于论文《Improving Language Understanding by Generative Pre-Training》,GPT是Generative Pre-Training的简写。从18年GPT-1提出预训练模型+fine-tune的思路后,到后来居上的Bert的大火,这些年NLP领域有好多的故事可讲。
模型简介
论文摘要翻译:自然语言理解包括一系列不同的任务,如文本蕴涵、问答、语义相似度评估和文本分类。虽然大型的未标记文本语料库丰富,但用于学习这些特定任务的已标注数据很少,这使得分别训练的模型难以达到效果。我们证明,通过在不同的未标记文本语料库上先训练一个预训练生成语言模型,然后对每个特定任务进行微调(fine-tune),可以在这些任务中实现较大的收益。与以前的方法不同,我们在微调期间利用任务相关的输入转换来实现有效的传输,仅需要对模型架构进行最少的更改。我们在一系列自然语言理解基准上展示了我们方法的有效性。我们的通用任务无关模型比使用专门为每个任务单独定制的模型性能更好,在试验的12个任务中有9个显著提高了最新水平。例如,我们在常识推理(Stories Cloze Test)、问答(RACE)和文本蕴涵(MultiNLI)任务上的绝对改进分别为8.9%、5.7%和1.5%。
在论文中,作者把GPT称为一种半监督(semi-supervised)方法, 它分为两个阶段:首先,在未标注数据上使用语言模型的目标函数训练一个神经网络;接着,使用相应的有监督目标函数来使模型的参数适应特定的任务。
模型使用Transformer的decoder,因为当时transfomer不如现在那样为人们所熟知,所以作者解释了下说,使用Transformer可以在处理文本中的长依赖时提供更多的结构内存(more structured memory)。
模型框架
无监督预训练
对于给定的无监督语料的tokens 集合,使用标准的语言模型目标函数,即最大化下面的似然函数(实际训练为最小化时,就在前面添加负号),式中的k是上下文窗口,条件概率P是由神经网络的参数
得到的:
对于语言模型,使用的是多层的原始Transformer 的解码器(decoder) (下面图1中的左半部分), 用公式表示如下:
上式中,是tokens的上下文向量, n是模型层数,
是token的embedding 矩阵,
是位置embedding 矩阵。
有监督的fine-tune
根据目标函数1训练得到模型之后,就到了对特定任务进行微调以调整模型参数的阶段了。假设有一个已标注数据集C,数据集中每一个实例包含一个输入tokens序列, 以及标签y。 我们把tokens序列输入到已经训练好的模型并得到transformer块最后一层的输出
, 将它输入一个新增的参数为
的线性输出层来预测y。
此时我们最大化如下目标函数:
作者发现如果在fine-tune时将语言模型的目标函数作为辅助目标函数加入有助于学习,因为两个原因:(a): 有助于提升有监督模型的泛化性; (b):加速模型收敛。 添加一个权重 后,目标函数变为:
所以在微调阶段,只需要添加额外参数和分隔tokens的embedding (具体下一节会提到)
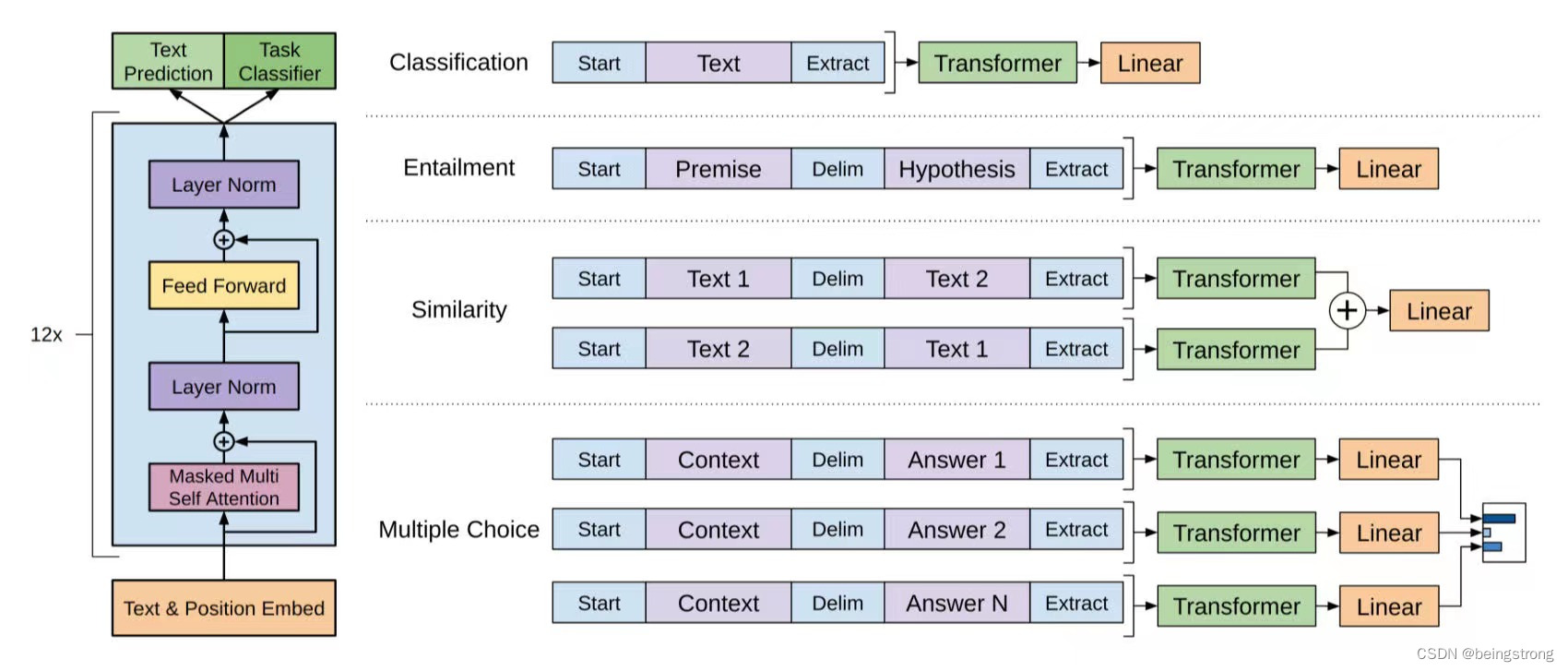
图1 GPT模型示意(论文中的Figure 1)
不同NLP任务的输入转换
因为模型预训练时的输入是连续的文本序列,所以对不同的NLP要对任务的输入做一些转换, 如图1右侧所示。在所有输入转换后都将包括embedding 随机初始化的开始和结束token
- 文本分类:直接在文本的首尾加上开始和结束token
- 文本蕴含:将前提p和假设h的token序列使用分隔符($)连接起来,再加上开始和结束token
- 文本相似性:因为计算相似性时,两个句子的顺序不重要,所以交换两个句子的顺序生成两个句子表示
,并将它们按位相加后输入到线性输出层。
- 问答和常识推理:对于上下文文档z、问题q、以及可能的答案集合
, 将文档和问题连接后使用分隔符$连接每一个可能的答案,即
, 得到的这些序列经过模型处理后,通过softmax层来得到每一个可能答案的分布。
实验部分
无监督训练的数据集
使用BooksCorpus 数据集来训练语言模型,BooksCorpus 数据集包含7000本不同种类的未出版书籍,题材广泛包含如冒险、浪漫、玄幻等题材。因为这个数据集包含很长的文本,很适合生成模型来学习从很长的信息中获取前提条件。
ELMO模型使用的1B大小的数据集Word Benchmark, 因为是句子级别的文本,文本的长结构被破坏了。
语言模型细节
- 12层的只有掩码自注意力的Transformer decoder, 其中隐藏层的大小是768, 12个attention head。 position-wise feed-forword 网络的隐藏层大小为3072
- 使用最大学习率为2.5e-4, 前2000个训练步逐渐从0开始线性增大学习率,然后使用cosine schedule 退火到0
- 以64的batch 大小一共训练了100个epoch, 序列长度为512
- 因为layernorm的使用,权重初始化使用N(0, 0.02)
- token的处理使用了40000 merge的 BPE(bytepair encoding) 词表
- 残差层、embedding层、attention层使用0.1的dropout
- 对权重使用了一个w=0.01的修改过的L2 正则化方法
- 激活函数使用的是GELU(Gaussian Error Linear Unit)
- 使用可学习的位置embedding 而不是transformer论文中的sine版本
- 使用ftfy库 来清洗BooksCorpus的文本, 使用SpaCy的tokenizer来处理标点和空格
微调细节
- 除了特别提到的情况外,所有超参都与预训练时一样
- 对于分类器使用0.1的dropout
- 对于大多数任务,使用6.25e-5的学习率,32的batch大小; 使用了0.2% 的训练样本来warmup 学习率的linear learning rate decay
- 式5的权重
为0.5
- 微调时训练速度很快,一般3个epoch就够了
分析部分
- 预训练的每一个层对于解决特定任务都有用
- 语言模型有一定的能力学习到特定任务相关的信息,所以有zero-shot的潜力
- 消融实验:1. 加入辅助的语言模型损失函数对于fine-tune更大的数据集有收益,而相对小的数据集则没有; 2. transfomer的学习能力比LSTM要强; 3. 无监督的预训练过程对于提高特定任务的效果是很明显的(对比直接将模型架构来训练有监督任务)
参考资料
1. 论文下载地址:language_understanding_paper.pdf (openai.com)
4. Generalized Language Models | Lil'Log (lilianweng.github.io)

















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









