









概述
DeepPose 2014 年由谷歌的研究人员提出,是最先将神经网络应用在人体姿态估计和关键点定位方面的论文。
如下图所示,关键点定位中存在一些问题:
- 一些关键点可能很小或者几乎不可见;
- 关键点可能被遮挡,这时候它的位置只能靠猜测;
- 不同部位的关键点可能发生混淆等。

方法
DeepPose 直接回归关键点坐标,为了提高回归精度,首先基于人体 box 框对关键点坐标进行归一化:
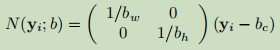
模型结构方面如下图所示,使用 5 个卷积层和两个全连层,最后对于 k 个关键点输出 2k 个坐标值。为了获得更高的定位精度,使用多个网络进行级联,将前一阶段的网络预测输出附近图像截取出来,输入后一阶段网络获取更精细化的定位坐标值。

损失函数方面使用预测值和标注值之间的 L2 距离作为损失。
数据集
数据集方面使用 FLIC(Frames Labeled In Cinema) 和 LSP(Leeds Sports Dataset) 数据集。FLIC 是一个好莱坞电影数据集,包含 4000 张训练图像和 1000 张测试图像,标注了 10 个上半身关键点。LSP 数据集包含 11000 张训练图像和 1000 张测试图像,标注了 14 个全身关键点。
指标及效果
通过叠加多阶段模型,在当时获得了最高的关键点定位精度。当然随着关键点定位方法的发展,有许多新的方法被提出,DeepPose 可以被当做一个背景知识做了解,实际应用还是应该选用更先进的关键点定位方法。
















 5744
5744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











