








DeepSeek的MOE(Mixture of Experts,混合专家)架构是一种基于专家模型(Mixture of Experts)的深度学习框架,旨在通过动态选择和激活部分专家模块来提高计算效率和模型性能。以下是对其核心特点和工作原理的详细介绍:
1. 核心概念与架构
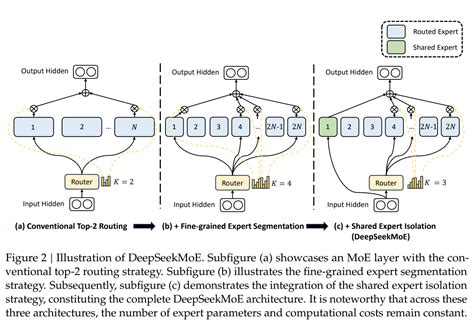
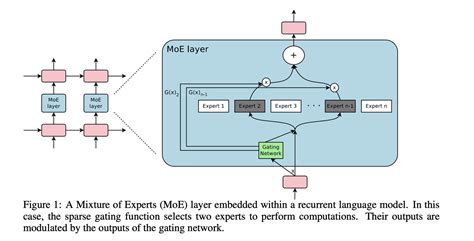
MOE架构的基本思想是将模型划分为多个“专家”模块,每个专家专注于处理特定类型的任务或数据特征。在推理时,通过门控机制(Gating Mechanism)动态选择最合适的专家进行计算,从而实现资源的高效利用。
核心组件:
-
专家层(Expert Layers) :每个专家是一个独立的神经网络,负责处理特定任务或数据子集。例如,DeepSeek V3中包含27个路由化的MOE层,每个专家处理不同类型的输入。

-
门控网络(Gating Network) :用于决定每个输入应路由到哪些专家。门控网络通常是一个小型的前馈网络,输出一个概率分布,指示每个专家的激活程度。
-
共享机制:部分专家可以共享参数,减少冗余并提升模型效率。
2. 技术特点
动态路由机制:
MOE架构通过动态路由机制实现资源的高效分配。对于每个输入令牌(token),门控网络会计算其与各个专家的匹配度,并选择Top-k个最相关的专家进行计算。这种机制使得模型能够在不同任务之间灵活切换,避免了传统Transformer模型中全量参数协同工作的高计算成本。
稀疏激活:
MOE架构的一个显著特点是稀疏激活,即在推理时仅激活一小部分专家。例如,DeepSeek V3中每个令牌仅激活370个参数,大幅降低了计算量和存储需求。
多头潜在注意力(MLA):
DeepSeek V3引入了多头潜在注意力机制(Multi-head Latent Attention),通过低秩键值压缩和解耦键矩阵的方式,进一步优化了注意力计算的效率。这一机制不仅减少了内存占用,还提升了模型对长文本的处理能力。
3. 优势与挑战
优势:
- 高效计算:MOE架构通过动态激活专家模块,显著减少了计算资源的消耗。例如,DeepSeek V3在硬件资源有限的情况下,实现了接近OpenAI GPT-4的性能。
- 扩展性强:MOE架构支持大规模参数扩展,同时保持较高的灵活性和可扩展性。
- 成本效益:通过稀疏激活和共享机制,MOE架构大幅降低了训练和推理成本。例如,DeepSeek V2的训练成本比初代模型降低了42.5%。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











