







1.SparkStreaming的架构

2.实例
一个实时计算的wordcount
object WordCount {
def main(args: Array[String]): Unit = {
//使用sparkstreaming来完成wordcount
//spark的配置对象
val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//实时分析的环境对象
//采集周期:以指定的时间为周期采集实时数据
val streamingContext = new StreamingContext(conf, Seconds(3))
//从指定的端口中采集数据
val socketLineDStream: ReceiverInputDStream[String] = streamingContext.socketTextStream("hadoop102", 9999)
//将采集的数据进行分解
val wordDStream = socketLineDStream.flatMap(line => line.split(" "))
//将数据进行结构的转变进行统计分析
val mapDStream = wordDStream.map((_, 1))
//将转换结构后的数据进行聚合处理
val wordToSumDStream = mapDStream.reduceByKey(_ + _)
//将结果打印
wordToSumDStream.print()
//结束,不需要stop(),因为是流式数据,需要一直采集下去。
//要完成采集器不停,整个程序不能停的效果
//启动采集器
streamingContext.start()
//Driver等待采集器的执行
streamingContext.awaitTermination()
}
}
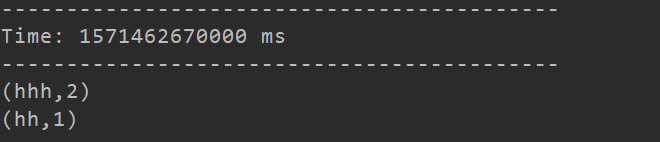
运行代码,在虚拟机上输入nc -lk 9999代表向9999号端口输入数据,来进行测试

会计算出每三秒中每个词出现的次数
 .
.
2.自定义Receiver
还是一样的例子,自定义实现一下
需要重写两个函数onStart()和onStop(),重写的两个函数本身实现比较简单,主要要实现的是onStart()函数中调用的receiver()方法
//自定义采集器
//1.继承Receiver
class MyReceiver(host:String,port:Int) extends Receiver[String](StorageLevel.MEMORY_ONLY){
var socket: java.net.Socket =null
def receive():Unit={
socket=new java.net.Socket(host,port)
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream,"UTF-8"))
var line:String=null
while ((line=reader.readLine())!=null){
//将采集的数据存储到采集器的内部进行转换
if("END".equals(line)){
return
}else{
this.store(line)
}
}
}
override def onStart(): Unit = {
new Thread(new Runnable {
override def run(): Unit = {
receive()
}
}).start()
}
override def onStop(): Unit = {
if(socket!=null){
socket.close()
socket=null
}
}
}
使用:
object Receiver {
def main(args: Array[String]): Unit = {
//使用sparkstreaming来完成wordcount
//spark的配置对象
val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//实时分析的环境对象
//采集周期:以指定的时间为周期采集实时数据
val streamingContext = new StreamingContext(conf, Seconds(3))
//在这里转换成自定义的采集器
val socketLineDStream: ReceiverInputDStream[String] = streamingContext.receiverStream(new MyReceiver("hadoop102",9999))
//将采集的数据进行分解
val wordDStream = socketLineDStream.flatMap(line => line.split(" "))
//将数据进行结构的转变进行统计分析
val mapDStream = wordDStream.map((_, 1))
//将转换结构后的数据进行聚合处理
val wordToSumDStream = mapDStream.reduceByKey(_ + _)
//将结果打印
wordToSumDStream.print()
//结束,不需要stop(),因为是流式数据,需要一直采集下去。
//要完成采集器不停,整个程序不能停的效果
//启动采集器
streamingContext.start()
//Driver等待采集器的执行
streamingContext.awaitTermination()
}
}















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









