






TSM(Temporal Shift Module)源码解析
论文名:TSM: Temporal Shift Module for Efficient Video Understanding
代码链接:https://github.com/mit-han-lab/temporal-shift-module
代码的主要结构如下:
| python file | function |
|---|---|
| mian.py | 主要的训练函数 |
| opts.py | 代码的参数配置 |
| ops/dataset.py | 数据集的载入部分,核心是__getitem__函数。 |
| ops/dataset_config.py | 用于配置不同的数据集 |
| ops/models.py | 组装模型 |
| ops/temporal_shift.py | 核心的temporal shift操作 |
1.opts.py是参数配置。除了路径、超参外,还有几个参数要注意(不同于TSN的点):
parser.add_argument('--shift', default=False, action="store_true", help='use shift for models')
parser.add_argument('--shift_div', default=8, type=int, help='number of div for shift (default: 8)')– modality 表示输入的类型,RGB/FLOW
–num_segments 表示每个视频采样frames数,一般是8或者16。
–shift 表示是否加入tsm模块。
–shift_div 表示shift的特征的比例,一般是8。表示2*1/8比例的特征会移动,其中1/8的特征做shift left, 另1/8的特征做shift right。
2.dataset_config.py是数据级的配置。
每个数据集实现一个return_xxx(modality)
返回数据集支持的子类名,train_list路径,val_list路径,数据集的根路径等信息。
3.dataset.py 是数据集的载入部分。
dataset.py的主要功能就是对数据集进行读取,并且对其稀疏采样,返回稀疏采样后得到的数据集。
dataset.py中实现了TSNDataSet类,处理原始数据,此类继承于torch.utils.data.dataset类。
其中首先定义了一个简单类:
3.1 VideoRecord,用于封装一个视频内容,包括图片的路径,frames的数量,标签信息。
class VideoRecord(object):
def __init__(self, row):
self._data = row
@property
def path(self):
return self._data[0]
@property
def num_frames(self):
return int(self._data[1])
@property
def label(self):
return int(self._data[2])3.2 TSNDataSet:
class TSNDataSet(data.Dataset):
def __init__(self, root_path, list_file,
num_segments=3, new_length=1, modality='RGB',
image_tmpl='img_{:05d}.jpg', transform=None,
random_shift=True, test_mode=False,
remove_missing=False, dense_sample=False, twice_sample=False):
self.root_path = root_path
self.list_file = list_file
self.num_segments = num_segments
self.new_length = new_length
self.modality = modality
self.image_tmpl = image_tmpl
self.transform = transform
self.random_shift = random_shift
self.test_mode = test_mode
self.remove_missing = remove_missing
self.dense_sample = dense_sample # using dense sample as I3D
self.twice_sample = twice_sample # twice sample for more validation
if self.dense_sample:
print('=> Using dense sample for the dataset...')
if self.twice_sample:
print('=> Using twice sample for the dataset...')
if self.modality == 'RGBDiff':
self.new_length += 1 # Diff needs one more image to calculate diff
self._parse_list()设置一些参数和参数默认值之后,调用了_parse_list()函数,tmq是一个长度为训练数据数量的列表。每个值都是VIDEORecord对象,包含一个列表和3个属性,列表长度为3,用空格键分割,分别为帧路径、该视频含有多少帧和帧标签。然后调用VideoRecord()函数,将内容写入到一个VideoRecord的list中去。
tmp = [x.strip().split(' ') for x in open(self.list_file)]self.video_list = [VideoRecord(item) for item in tmp]3.3 TSNDataSet需要实现核心函数__getitem()
首先我们需要获取视频对应的image和label,image的格式为[ n*t, c, h, w]
def __getitem__(self, index):
record = self.video_list[index]那么对于一个视频,如何获得num_segments个帧呢?
if not self.test_mode: # test_mode: False; random_shift: True;
segment_indices = self._sample_indices(record) if self.random_shift else self._get_val_indices(record)
else:
segment_indices = self._get_test_indices(record)
return self.get(record, segment_indices)有3种不同采样函数(针对于train、test、val):
其中,_sample_indice函数是针对于train的采样方式;默认情况下, _sample_indice函数会随机采取num_segments个index,有稠密采样(dense)和稀疏采样(normal)两种方式.
_get_test_indices会稀疏且固定地得到num_segments个index。
简单举个例子,num_frames=120, num_segments=3的时候,
_sample_indices中normal sample会随机返回:[ 4,44,84],[ 5,45,85], [ 11,51,91]。
_sample_indices中dense sample会随机返回:[15, 36, 57], [30, 51, 72], [44, 65, 86]。
_get_test_indices中dense_sample同理
_get_test_indices中twice_sample会随机返回:[11,31,51,1,21,41]
最终,每个视频都采样num_segments个帧,getitem返回维度为:[n * t, c, h, w] (frames), 1 (label)。
4.models.py
models.py的主要功能是对之后的训练模型做准备;首先使用一些经典的模型作为基础,如resnet50,针对不同的输入模态,对最后一层全连接层进行修改,得到我们TSN模型,而在其中又引入了是否加入TSM模块,从而得到我们所需要的TSM模型。
init函数设置一些参数和参数默认值,通过调用函数修改模型得到TSN模型,在调用TSM模块函数,从而得到TSM模型,其中init函数调用了
1 调用 _prepare_base_model(base_model)构建出基础的模型
2 调用_prepare_tsn(num_class),用于根据不同数据集的子类数,适配fc层大小
3 对于flow和rgbdiff的输入,调用_construct_flow_model和_construct_diff_model更改第一个卷积核的大小
4.1 _prepare_base_model()函数
而调用make_temporal_shit()函数加入tsm模块:
def _prepare_base_model(self, base_model):
print('=> base model: {}'.format(base_model))
if 'resnet' in base_model:
# torchvision.models.resnet50
self.base_model = getattr(torchvision.models, base_model)(True if self.pretrain == 'imagenet' else False)
if self.is_shift: # 默认false
print('Adding temporal shift...')
from ops.temporal_shift import make_temporal_shift
make_temporal_shift(self.base_model, self.num_segments,
n_div=self.shift_div, place=self.shift_place, temporal_pool=self.temporal_pool)
if self.non_local: # 默认False
print('Adding non-local module...')
from ops.non_local import make_non_local
make_non_local(self.base_model, self.num_segments)
self.base_model.last_layer_name = 'fc'
self.input_size = 224
self.input_mean = [0.485, 0.456, 0.406]
self.input_std = [0.229, 0.224, 0.225]
# 1代表输出特征图的大小;torch.Size([2, 32, 16, 16])----->torch.Size([2, 32, 1, 1])
self.base_model.avgpool = nn.AdaptiveAvgPool2d(1)
4.2 _prepare_tsn函数
_prepare_tsn函数的功能在于对已知的basemodel网络结构进行修改,微调最后一层(全连接层)的结构,成为适合该数据集输出的形式。
def _prepare_tsn(self, num_class):
# 获取模型最后一层输入层的维度
feature_dim = getattr(self.base_model, self.base_model.last_layer_name).in_features
# 如果dropout==0,直接添加新的全连接层,输出维度是num_class
if self.dropout == 0:
setattr(self.base_model, self.base_model.last_layer_name, nn.Linear(feature_dim, num_class))
self.new_fc = None
# 如果有dropout!=0,添加dropout层,然后再添加全连接层,输出维度是num_class
else:
setattr(self.base_model, self.base_model.last_layer_name, nn.Dropout(p=self.dropout))
self.new_fc = nn.Linear(feature_dim, num_class)
std = 0.001
if self.new_fc is None:
normal_(getattr(self.base_model, self.base_model.last_layer_name).weight, 0, std)
constant_(getattr(self.base_model, self.base_model.last_layer_name).bias, 0)
else:
if hasattr(self.new_fc, 'weight'):
normal_(self.new_fc.weight, 0, std)
constant_(self.new_fc.bias, 0)
return feature_dim
4.3 make_temporal_shift()函数 TSM模块的核心
make_temporal_shift(self.base_model, self.num_segments,
n_div=self.shift_div, place=self.shift_place, temporal_pool=self.temporal_pool)那么TemporalShift(b, n_segment=this_segment, n_div=n_div又是怎么实现的呢?
对于[n*t, c, h, w]的输入,t是segment的值,首先reshape成[n, t, c, h, w],
如果当前feature map的通道256,fold_div=8,那么有256/8的特征进行shift left,256/8的特征进行shift right。其他一部分的特征不动。
@staticmethod
def shift(x, n_segment, fold_div=3, inplace=False):
nt, c, h, w = x.size()
n_batch = nt // n_segment
x = x.view(n_batch, n_segment, c, h, w)
fold = c // fold_div
if inplace:
# Due to some out of order error when performing parallel computing.
# May need to write a CUDA kernel.
raise NotImplementedError
# out = InplaceShift.apply(x, fold)
else:
out = torch.zeros_like(x)
out[:, :-1, :fold] = x[:, 1:, :fold] # shift left
out[:, 1:, fold: 2 * fold] = x[:, :-1, fold: 2 * fold] # shift right
out[:, :, 2 * fold:] = x[:, :, 2 * fold:] # not shift
return out.view(nt, c, h, w)举个简单的例子:
当c = 8, num_segment=4, 2维度的特征表示如下:
0_xx代表第一帧的特征。1_xx代码第二帧的特征,每个特征有8个通道。原始特征如下:
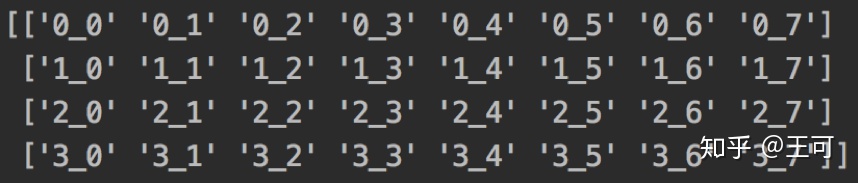
当fold_div = 8的时候,移动后如下:
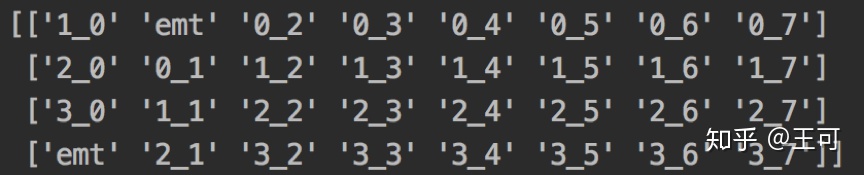
可见第一帧中融入了第二帧的特征,第二帧中融入了第三帧和第二帧的特征。
当fold_div=4的时候,移动的部分会更多,即当前帧的特征中会包含更多前一帧和后一帧的信息。
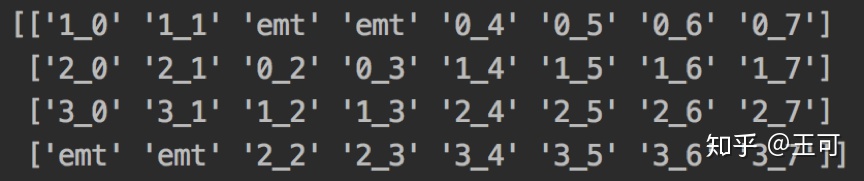
5.main.py 是训练主函数
最后我们来讲解训练主函数,将上述将的类和函数串联起来。
5.1 调用dataset_config.return_dataset中获得各个路径的信息
5.2 实例化好模型、优化器
5.3 载入好预训练模型或从训练中一般恢复
5.4 准备好数据train_loader,val_loader
5.5 然后开始每个epoch迭代,保存一个最新的模型和最好的模型
adjust_learning_rate,根据策略调整每个epoch的学习率。
for epoch in range(args.start_epoch, args.epochs):
# Sets the learning rate to the initial LR decayed by 10 every 30 epochs
adjust_learning_rate(optimizer, epoch, args.lr_type, args.lr_steps)
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch, log_training, tf_writer)
# evaluate on validation set
if (epoch + 1) % args.eval_freq == 0 or epoch == args.epochs - 1:
prec1 = validate(val_loader, model, criterion, epoch, log_training, tf_writer)
# remember best prec@1 and save checkpoint
is_best = prec1 > best_prec1
best_prec1 = max(prec1, best_prec1)
tf_writer.add_scalar('acc/test_top1_best', best_prec1, epoch)
output_best = 'Best Prec@1: %.3f\n' % (best_prec1)
print(output_best)
log_training.write(output_best + '\n')
log_training.flush() # 刷新缓冲区
save_checkpoint({
'epoch': epoch + 1,
'arch': args.arch,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
'best_prec1': best_prec1,
}, is_best)
train的核心函数如下:
def train(train_loader, model, criterion, optimizer, epoch, log, tf_writer):
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
if args.no_partialbn: # 默认false
model.module.partialBN(False)
else:
model.module.partialBN(True)
# switch to train mode
model.train()
end = time.time() # 返回当前时间戳
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
raise RuntimeError
input_var = torch.autograd.Variable(input)
target_var = torch.autograd.Variable(target)
# compute output
output = model(input_var)
loss = criterion(output, target_var)
# print('********************')
# print(loss)
# raise RuntimeError
# measure accuracy and record loss
prec1, prec5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1.item(), input.size(0))
top5.update(prec5.item(), input.size(0))
# compute gradient and do SGD step
loss.backward()
if args.clip_gradient is not None: # None
total_norm = clip_grad_norm_(model.parameters(), args.clip_gradient)
optimizer.step()
optimizer.zero_grad()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0: # print_freq = 20
output = ('Epoch: [{0}][{1}/{2}], lr: {lr:.5f}\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5, lr=optimizer.param_groups[-1]['lr'] * 0.1)) # TODO
print(output)
log.write(output + '\n')
log.flush()
tf_writer.add_scalar('loss/train', losses.avg, epoch)
tf_writer.add_scalar('acc/train_top1', top1.avg, epoch)
tf_writer.add_scalar('acc/train_top5', top5.avg, epoch)
tf_writer.add_scalar('lr', optimizer.param_groups[-1]['lr'], epoch)














 7377
7377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









