






前言:在做视频插帧方向时,RSNR和SSIM的值往往很高,但是图片的质量却不太佳。这里我先整理一些常用的损失函数,对损失函数进行改进想看看对性能有什么影响。
视频插帧各类损失函数汇总
FLAVR–FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation
这里的损失函数只用了L1损失,原文如下:
Loss Function We can now train the whole network end to end using a pixel level loss like L1 loss between the predicted and ground truth frames,
where {Iˆ(i) j } and {Ij(i)} are the j-th predicted and the j-th ground truth frame of the i-th training clip, k is the interpolation factor, and N is the size of the mini-batch used in training.

superslomo–Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation
损失函数由四项组成:
其中:
- 第一项:重建损失
Reconstruction loss lr,即L1损失,定义公式为:
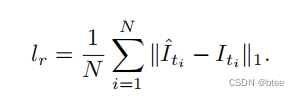
- 第二项:感知损失
Perceptual loss,防止预测中的模糊使预测保留更多的细节。
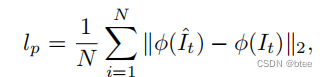
- 第三项:翘曲损失
Warping loss,约束光流
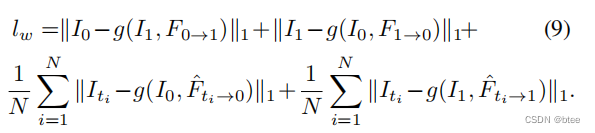
- 第四项:平滑损失
Smoothness loss,约束光流
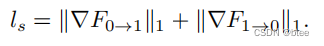
BMBC–BMBC:Bilateral Motion Estimation with Bilateral Cost Volume for Video Interpolation.
损失函数由两项组成: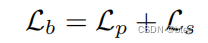
- 第一项:光度损失photometric loss
这一项类似于之前的翘曲损失,但是采用的不是L1损失,而是 Charbonnier function, 如下:
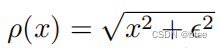
参数设置:αl= 0.01 × 2的l次方 ϵ = 10 的-6次方
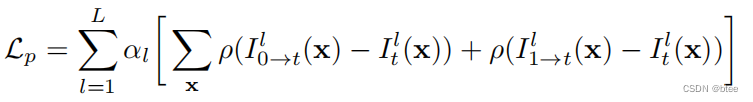
- 第二项:平滑损失
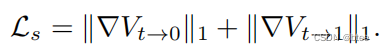
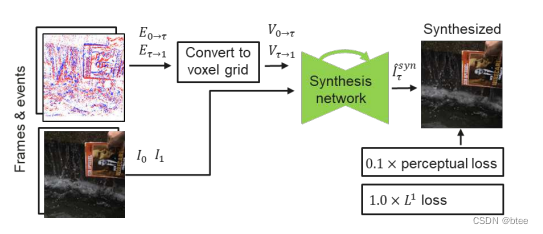
Timelens–Time Lens: Event-based Video Frame Interpolation
损失函数由感知损失和L1损失共同构成,每个训练模块的损失不太一致,下图是其一的训练模块的损失函数。
DAIN–Depth-Aware Video Frame Interpolation
损失函数采用了类似L1损失的Charbonnier function

AdaCoF–AdaCoF: Adaptive Collaboration of Flows for Video Frame Interpolation
损失函数由两部分组成:失真导向loss,distortion-oriented loss,和感知导向loss,perception-oriented loss
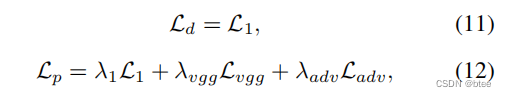
其中:感知损失原文如下
Perceptual Loss. Perceptual loss has been found to be effective in producing visually more realistic outputs. We add the perceptual loss with the feature extractor F from conv4 3 of ImageNet pretrained VGG16 network.
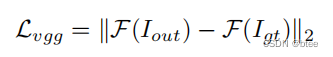
而对抗损失是该文章提出来的,公式如下
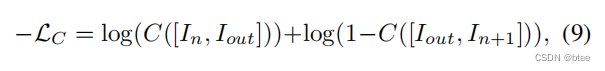
It is known that training the networks with adversarial loss can lead to results of higher quality and sharpness, instead of increasing mean squared error. This could be applied to video frame interpolation tasks. However, simply applying it to the single output frame does not consider the temporal consistency and leads to a disparate result compared to the input frames. What we want is to make the synthesized frame appear natural among the adjacent frames, not the other real images. Therefore, we concatenate the generated frame and one of the input frames in the temporal order and train the discriminator C to distinguish which of the two is the generated frame with the following loss.

















 576
576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









