






 本文介绍了在无模型学习背景下,如何运用蒙特卡洛方法估计马尔可夫决策过程中的状态价值,包括时序差分和Sarsa、Q-learning算法的区别,以及如何处理策略提升中的探索与利用问题。
本文介绍了在无模型学习背景下,如何运用蒙特卡洛方法估计马尔可夫决策过程中的状态价值,包括时序差分和Sarsa、Q-learning算法的区别,以及如何处理策略提升中的探索与利用问题。
现在开始无模型的学习
老师这里是把时序差分和蒙特卡洛一起讲的,可惜我睡着了,来预习一下吧
蒙特卡洛
还是一样的,我们想知道每个状态的价值,这样我就可以往价值高的地方走
那如何用蒙特卡洛方法来估计,一个策略,在一个马尔可夫决策过程中的状态价值。回忆一下,一个状态的价值是它的期望回报, 那么一个很直观的想法就是用策略在 MDP 上采样很多条序列,计算从这个状态出发的回报再求其期望就可以了,公式如下:
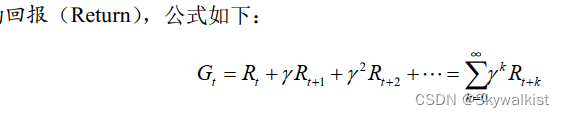
我想很多人已经忘了G是什么,Q,V,a,S,G,Π,记不牢就看不懂
在一条序列中,可能没有出现过这个状态,可能只出现过一次这个状态,也可能出现过很多次这个状态。我们介绍的蒙特卡洛价值估计方法会在该状态每一次出现时计算它的回报。还有一种选择是一条序列只计算一次回报,也就是在这条序列第一次出现该状态时计算后面的累积奖励,而后面再次出现该状态时,该状态就被忽略了。假设我们现在用策略Π从状态 s 开始采样序列,据此来计算状态价值。我们为每一个状态维护一个计数器和总回报,计算状态价值的具体过程如下所示。
我在这里最大的疑惑就是G怎么算,解析代码

先生成episode,然后沿着这条路反推,就知道到达每个S的G,解决
补一句增量更新:
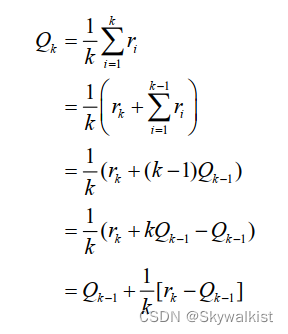
降低复杂度
回到时序差分
回顾一下蒙特卡洛方法对价值函数的增量更新方式:

这里我们将 3.5 节的 1/N(s)替换成 α, 表示对价值估计更新的步长。 可以将α 取为一个常数,此时更新方式不再像蒙特卡洛方法那样严格地取期望。
特卡洛方法必须要等整个序列采样结束之后才能计算得到这一次的回报Gt, 而时序差分算法只需要当前步结束即可进行计算。 具体来说, 时序差分算法用当前获得的奖励加上下一个状态的价值估计来作为在当前状态会获得的回报, 即
![]()
Sarsa
用时序差分算法来估计动作价值函数Q :
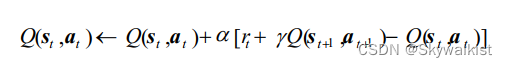
然后我们用贪婪算法来选取在某个状态下动作价值最大的那个动作, 即arg max_a Q(s ,a ) 。 这样似乎已经形成了一个完整的强化学习算法: 用贪婪算法根据动作价值选取动作来和环境交互, 再根据得到的数据用时序差分算法更新动作价值估计。
需要进一步考虑的问题
如果在策略提升中一直根据贪婪算法得到一个确定性策略, 可能会导致某些状态动作对( s, a) 永远没有在序列中出现, 以至于无法对其动作价值进行估计, 进而无法保证策略提升后的策略比之前的好。
简单常用的解决方案是不再一味使用贪婪算法, 而是采用一个 -贪婪策略: 有1- 的概率采用动作价值最大的那个动作, 另外有 的概率从动作空间中随机采取一个动作, 其公式表示为:


Q-learning 算法
除了 Sarsa,还有一种非常著名的基于时序差分算法的强化学习算法Q-learning。 Q-learning 和 Sarsa 的最大区别在于Q-learning 的时序差分更新方式为
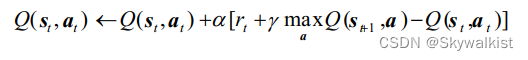


非常非常像价值迭代有没有!
动作价值函数的贝尔曼最优方程为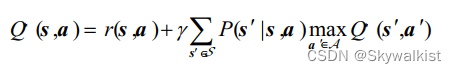
而Sarsa 估计当前 -贪婪策略的动作价值函数。 需要强调的是, Q-learning的更新并非必须使用当前贪婪策略arg max aQ( s, a)采样得到的数据, 因为给定任意 (s ,a , r,s′ )都可以直接根据更新公式来更新 Q , 为了探索, 我们通常使用一个 -贪婪策略来与环境交互。 Sarsa 必须使用当前 -贪婪策略采样得到的数据, 因为它的更新中用到的Q(s′,a′)中的 a′ 是当前策略在s′ 下的动作。 我们称 Sarsa 为在线策略(on-policy) 算法, 称Q-learning为离线策略( off-policy)算法,这两个概念在强化学习中非常重要















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









