







1 Sarsa(0)
Sarsa算法和TD类似,只不过TD是更新状态的奖励函数V,这里是更新Q函数强化学习笔记:Q-learning :temporal difference 方法_UQI-LIUWJ的博客-CSDN博客
| TD |  |
| Sarsa |  |
该算法由于每次更新值函数需要知道当前的状态(state)、当前的动作(action)、奖励(reward)、下一步的状态(state)、下一步的动作(action),即 (St,At,Rt+1,St+1,At+1) 这几个值 ,由此得名 Sarsa 算法。
1.1 表格形式的SARSA
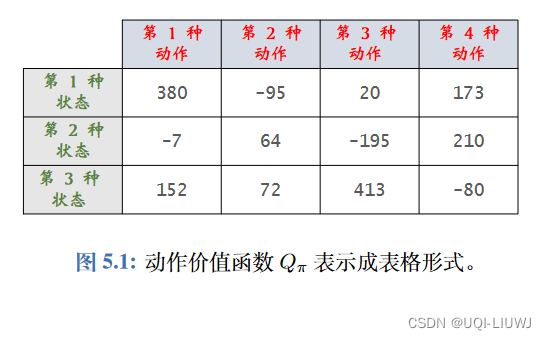
- SARSA算法由如下的贝尔曼方程推导出
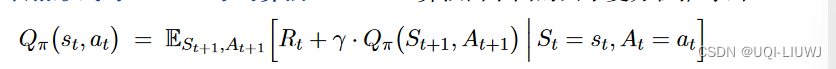
其中:


2 n-step Sarsa

3 与环境交互

右边是环境,左边是 agent 。
我们每次跟环境交互一次之后呢,就可以 learn 一下,向环境输出 action,然后从环境当中拿到 state 和 reward。
Agent 主要实现两个方法:
- 一个就是根据 Q 表格去选择动作,输出 action。
- 另外一个就是拿到 (St,At,Rt+1,St+1,At+1) 这几个值去更新我们的 Q 表格。
4 Sarsa on-policy
Sarsa 是一种 on-policy 策略。
Sarsa 优化的是它实际执行的策略,它直接拿下一步会执行的 action (At+1) 来去优化 Q 表格,所以 on-policy 在学习的过程中,只存在一种确定的策略,它用这种确定的策略去做 action 的选取,也用一种这种确定的策略去做优化。
5 和Q-learning的区别
| Q-learning | SARSA | |
| 表格形式 | ||
| 表格形式中每一个单元的意义 | 最优动作价值函数Q*
| 某种策略
|
| 贝尔曼方程 | 【对于t+1时刻的action,Q-learning选择Q最大的那个】 | 【对于t+1时刻的action,SARSA根据 |
| q的更新 |
|
|
| 贝尔曼放是关于什么的期望 | 方程右边的期望是关于下一时刻状态 | 方程右边的期望是关于下一时刻状态 ——>相比于Q-learning,SARSA依赖于具体的策略! |
| 异策略(Off policy) 【因为Q-learning的目标是学习Q*,这个与具体的策略无关(换句话说,Q-learning t+1步之后的策略就是每次选择Q最大的action】 | 同策略(On policy) | |
| 是否允许经验回放 | 可以使用经验回放 | 不可以使用经验回放 |
| 神经网络形式 | ||
| 神经网络的训练流程 |
【Q(s,a;w)是用来估算Q*(s,a)的】 |
【Q(s,a;w)是用来估算Q |
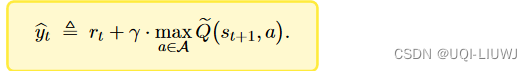
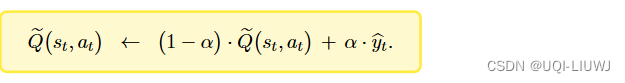
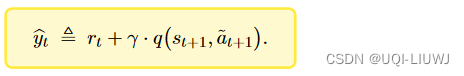
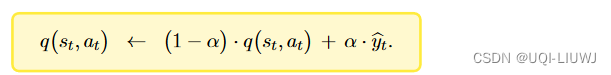
6 关于经验回放的一个疑问(欢迎讨论)
在学习了DPG确定策略梯度后,有一个小问题想和大家探讨一下:就是像SARSA这样的同策略,就算是用了经验回放,会有很大的影响嘛?
因为我更新sarsa的五元组里面,受到策略
影响的就是
,
是已知,
是和环境交互的结果,与策略
关系不大。
策略输出的是基于
的action的一个概率分布。换句话说,不管 策略
的参数是什么,某一个动作a都能取到,只不过是取到的概率的不同。
那么这样的话,我agent实时交互得到动作和使用过去的经验
,有什么区别嘛?(因为 策略
参数的变动,影响的也只是取到 动作
的概率,不代表
参数更新后,
取不到啊。。。)
那这样的话,我像SARSA这样的同策略模型,也不是不可以使用经验回放?
















 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











