








论文地址:https://papers.nips.cc/paper/2021/file/950a4152c2b4aa3ad78bdd6b366cc179-Paper.pdf
项目地址:https://github.com/facebookresearch/MaskFormer
现在的方法通常将语义分割制定为per-pixel classification任务,而实例分割则使用mask classification来处理。
本文作者的观点是:mask classification完全可以通用,即可以使用完全相同的模型、损失和训练程序以统一的方式解决语义和实例级别的分割任务。
据此本文提出了一个简单的mask classification模型——MaskFormer,预测一组二进制掩码,每个掩码都与单个全局类标签预测相关联,并且可以将任何现有的per-pixel classification模型无缝转换为mask classification。
MaskFormer 的性能优于SOTA的语义分割模型(ADE20K 上的 55.6 mIoU)和全景分割模型(COCO 上的 52.7 PQ),特别是类别数量很大时。
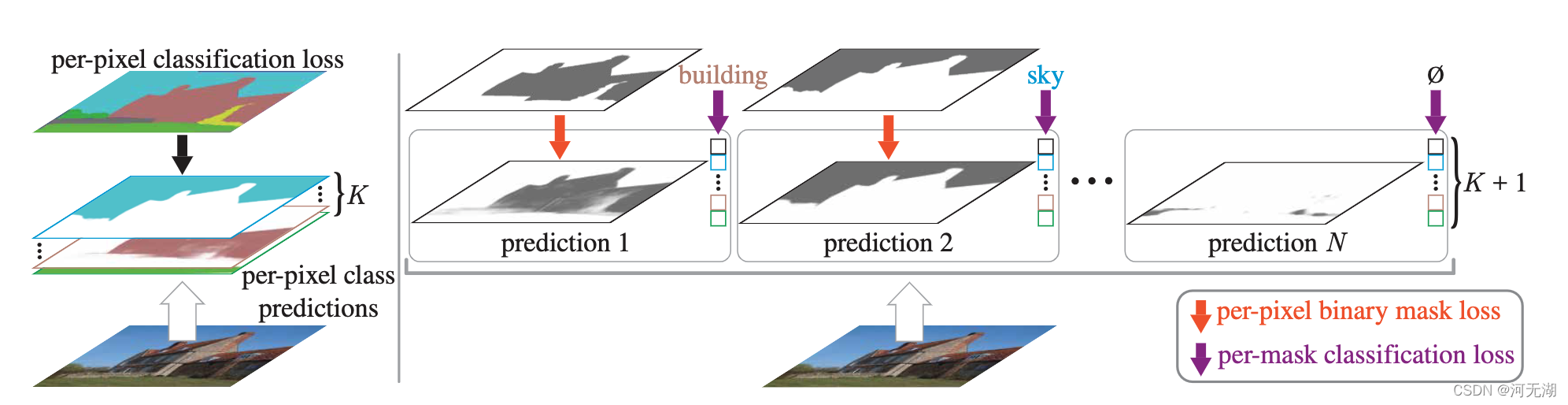
Mask classification formulation
掩码分类将分割任务拆分为
1)将图像划分/分组为N个区域(N不需要等于K),用二值掩码表示;
2)将每个区域作为一个整体与 K 个类别的分布相关联。
为了执行掩码分类,将期望的输出 z 定义为一组 N 个概率-掩码对:

与per-pixel类别概率预测不同,掩码分类概率分布除了 K 个类别标签之外还包含一个辅助的**“无对象”标签——∅**,表示不对应于 K 个类别中的任何一个的掩码。掩码分类允许具有对应于同一标签的多个掩码预测,使其适用于语义和实例级分割任务。
为了训练掩码分类模型,需要预测集合和真实分割集合之间的匹配 σ。由于预测集的大小通常比真实集大,因此用“无对象”标记 ∅ 扩充真实集以允许一对一匹配.对于语义分割,如果预测的数量 N 与类别标签的数量 K 匹配,则可以进行简单的固定匹配。在这种情况下,第 i 个预测与具有类别标签 i 的地面实况区域匹配,如果具有类别标签 i 的区域不存在于真实集中,则与 ∅ 匹配。
在本文的实验中,作者发现基于二分匹配(bipartite matching-based)的分配比固定匹配(fixed matching)表现出更好的结果。
与DETR使用边界框计算预测和标记之间的对齐损失来处理匹配不同,本文主要的掩码分类损失由类概率交叉熵分类损失和每个预测分割的二值掩码损失组成:
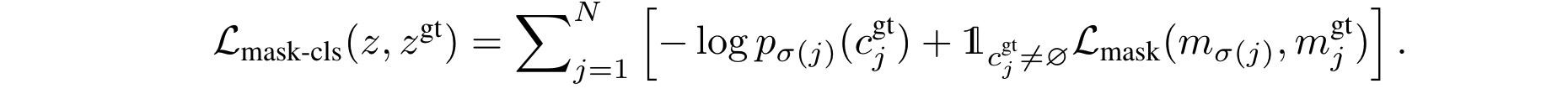
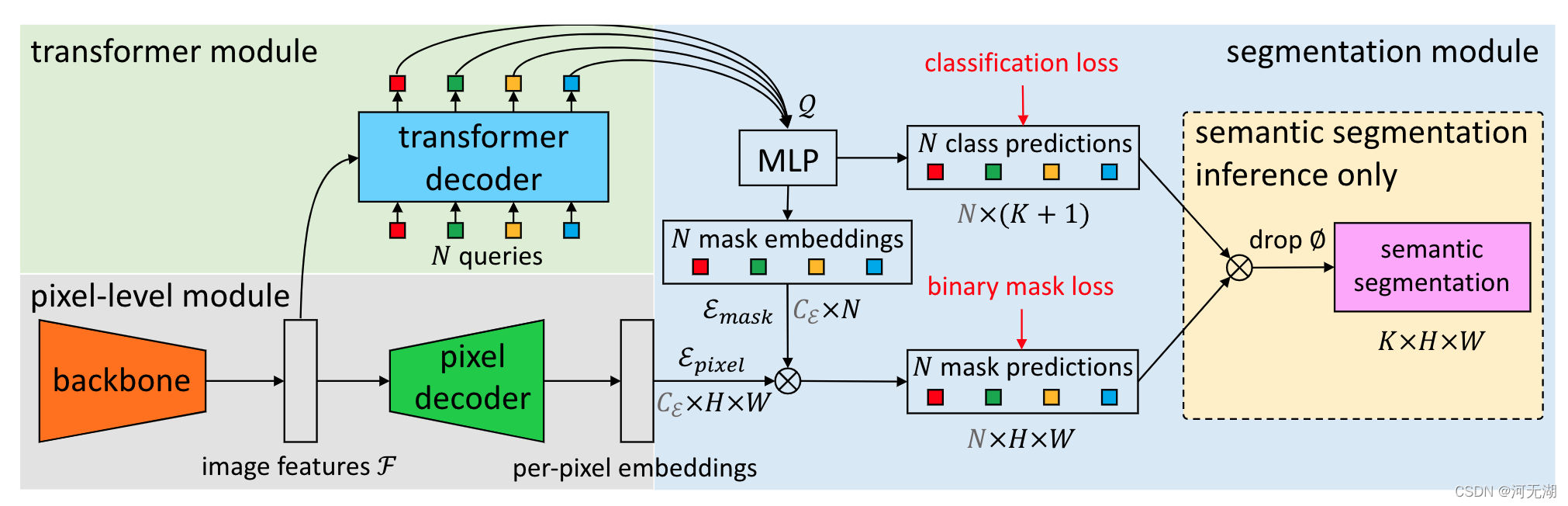
MaskFormer
MaskFormer包含三个模块:
1)像素级模块:用于提取图像特征的backbone和用于生成per-pixel嵌入的像素级解码器;
2)Transformer模块:使用堆叠的Transformer解码器层计算N个per-segment嵌入;
3)分割模块:从上述两个embeddings生成预测结果的概率-掩码对。
像素级模块
输入H×W的图像,
- backbone生成低分辨率图像特征图F;
- 像素解码器逐步对特征进行上采样以生成per-pixel嵌入Epixel。
任何基于per-pixel分类的分割模型都适合像素级模块设计,MaskFormer可以将此类模型无缝转换为Mask分类,本文中使用的backbone为ResNet backbones和Swin-Transformer backbones。
像素解码器基于流行的 FPN 架构的轻量级像素解码器。 在 FPN 之后,对解码器中的低分辨率特征图进行 2× 上采样,并将其与来自主干的相应分辨率的投影特征图(投影是为了与特征图维度匹配,通过1×1 卷积层+GroupNorm实现)相加。 接下来,通过一个额外的 3×3 卷积层+GN+ReLU将串联特征融合。 重复这个过程,直到获得最终特征图。最后,应用单个 1×1 卷积层来获得peri-pixel嵌入。
Transformer 模块
使用标准 Transformer 解码器(与 DETR 相同) 从图像特征 F 和 N 个可学习的位置嵌入(即查询)计算输出N 个per-segments嵌入 Q ,它编码了 MaskFormer 预测的每个段的全局信息。 与 DETR 类似,解码器并行生成所有预测。
N 个查询嵌入初始化为零向量且各与一个可学习的位置编码相关联。
本文使用 6 个 Transformer 解码器层和 100 个查询,并且在每个解码器之后应用 DETR 相同的损失。
在实验中,作者观察到 MaskFormer 在使用单个解码器层进行语义分割也相当有竞争力,但在实例分割中多个层对于从最终预测中删除重复项是必要的。
分割模块
使用一个带softmax 激活的线性分类器,在per-segments嵌入 Q 上产生类概率预测。且预测一个额外的“无对象”类别 (∅) 来防止嵌入不对应任何区域。
对于Mask预测,使用包含 2 个隐藏层的多层感知器 (MLP) 将per-segments嵌入 Q 转换为 N 个Mask嵌入 Emask。
最后,通过计算的第 i 个Mask嵌入和per-pixel嵌入之间的点积获得对应的二值掩码预测 mi(点积后使用 sigmoid 激活)
作者发现通过使用 softmax 激活使得掩码预测非强制性地相互排斥是有益的。
在训练期间,Lmask-cls损失组合了交叉熵分类损失和每个预测段的二元掩码损失 Lmask。 为简单起见,本文作者用与DETR 相同的 Lmask ,即焦点损失(focal loss) 和骰子损失( dice loss)的线性组合。
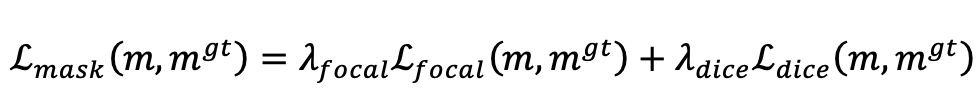
Mask-classification inference
我们注意到,推理策略的具体选择在很大程度上取决于评估指标而不是任务。
通用推理
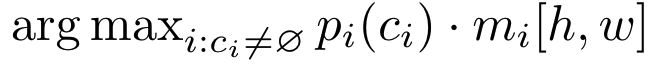
通用推理通过上式将每个像素 [h,w] 分配给 N 个预测的概率-掩码对之一,从而将图像划分为多个segments。
直观来看,这个过程将[h,w] 处的像素分配给概率-掩码对 i 仅当最可能的类别概率 pi(ci) 和掩码预测概率 mi[h,w] 都很高时。
分配给相同概率-掩码对的像素形成一个segment ,其中每个像素都用 ci 标记.。
- 对于语义分割,共享相同类别标签的片段被合并;
- 对于实例分割,概率-掩码对的索引有助于区分同一类的不同实例。
- 为了减少全景分割中的误报率,在推理之前过滤掉低置信度的预测,并删除大部分二元掩码 (mi>0.5) 被其他预测遮挡的预测片段。
语义推理
语义推理通过简单的矩阵乘法完成。作者发现,对概率-掩码对进行**边缘化(marginalization)**相较于通用推理策略中将像素硬性分配给的概率掩码对能产生更好的结果。
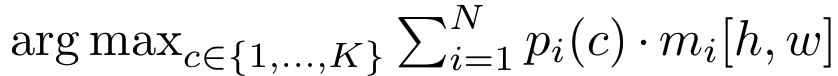
argmax 不包括“无对象”类别(∅),因为标准语义分割要求每个输出像素取一个标签。注意,此策略返回per-pixel类别概率。然而,我们观察到直接最大化per-pixel类可能性(likelihood)会导致性能不佳。

















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









