








论文地址:http://arxiv.org/abs/1906.05849
项目地址:http://github.com/HobbitLong/CMC
本文探究了一个经典假设:强大的表示是对视图不变因素建模的表示。
作者在多视图对比学习的框架下研究了这个假设,并去学习了一种小而有效的旨在最大化同一场景的不同视图之间的相互信息的表示。该方法可以扩展到任意数量的视图,并且与视图无关。
作者分析了使其奏效的关键属性,发现使用对比损失优于另一种基于交叉视图预测的流行方法,并且学习的视图越多,生成的表示就可以更好地捕捉潜在的场景语义。
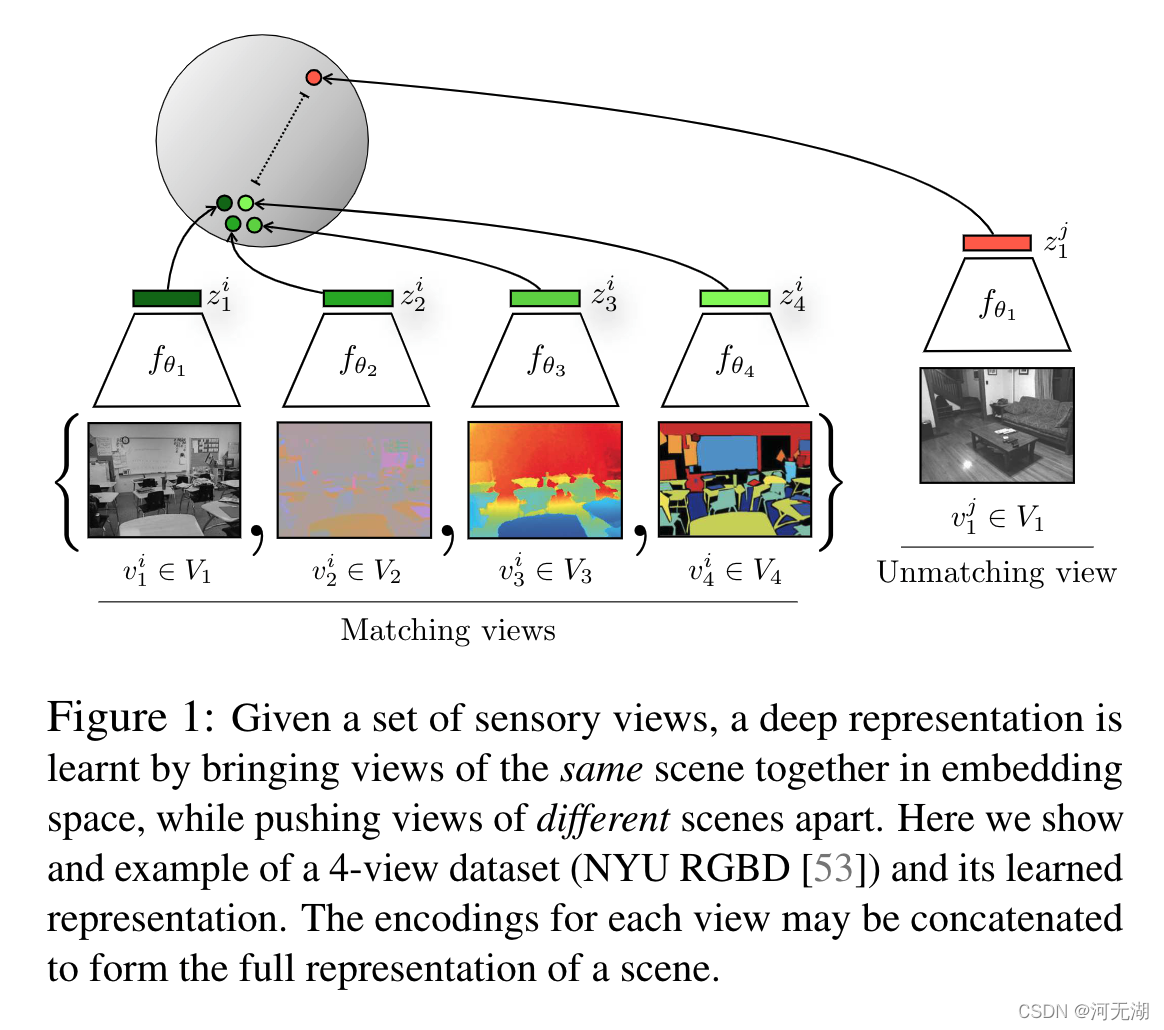
预测学习与对比学习
Figure 2 展示了预测学习(a)与对比学习(b)的区别。

- 图(a)中f和g分别代表编码器和解码器,训练的目标即使预测结果尽可能的与v2相同,常常使用 L1 或 L2 损失函数。
- 图(b)展示了两个视图的对比学习,判别函数hθ(·)被用于实现正样本对的高得分和负样本对的低得分,并通过训练此函数来正确选择出包含 k个负样本的集合中的单个正样本(见公式1)。在实际针对两个视图V1、V2的情况,只需固定一个视图作为anchor并从另一个视图中获得正样本(见公式2)。

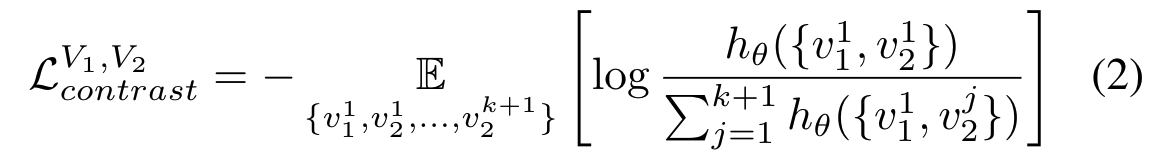
hθ(·) 由神经网络实现,并使用了两个编码器fθ1(·)和fθ2(·),分别具有参数θ1和θ2, 将两个编码器提取结果的余弦相似度计算为分数,并通过超参数τ调整其动态范围:
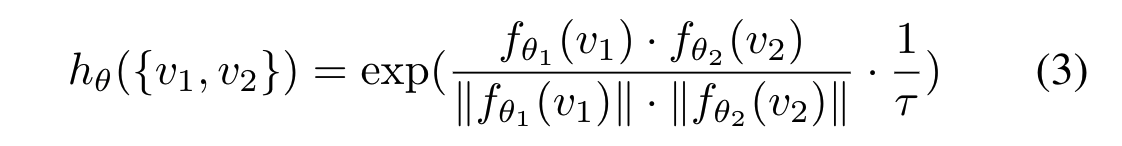
最后把分别将V1和V2作为anchor的两个损失相加作为two-view Loss:
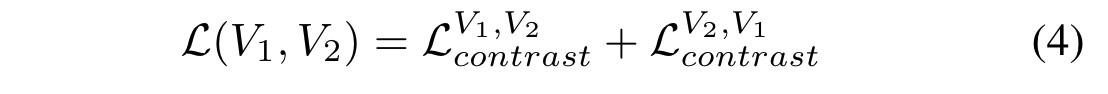
超过两个视图的对比学习
作者提出了更一般的方程式可以处理任意数量的视图,分别为“核心视图(Core View)”和“全图(Full Graph)”范式,在效率和有效性之间提供了不同的权衡(见Figure 3)。
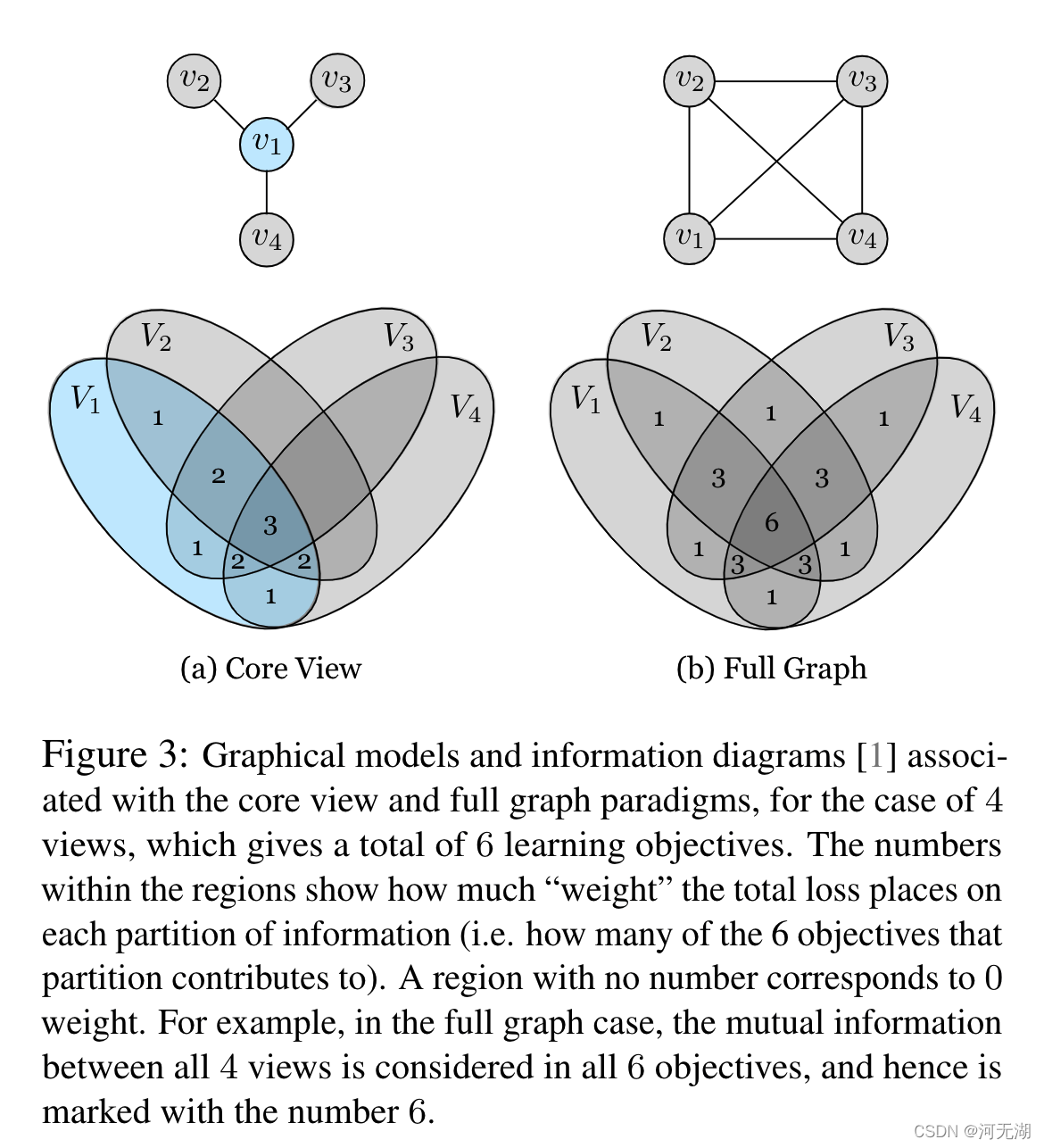
- “核心视图”公式将想要优化的一个视图作为中心,分别与其他视图建立成对的表示并优化所有成对目标的总和:
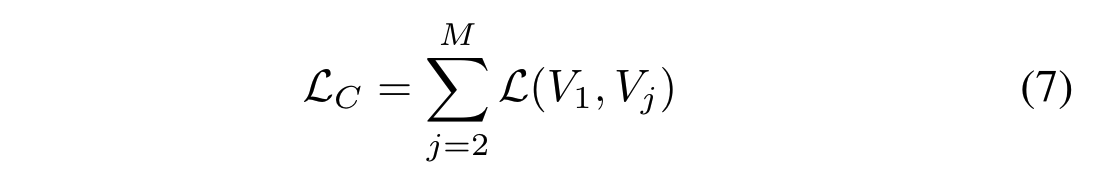
- “全图”公式则对所有成对视图组合的总合进行优化:
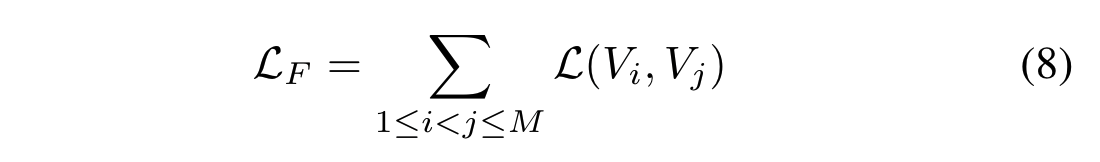
这两种公式都具有信息的优先级与共享该信息的视图数量成比例的特性。这使得在核心视图和全图目标下,所有视图共有的因素(公共部分)将会比影响较少视图的因素得到更多的权重。
不难看出,全图公式的计算成本与视图数量的组合数成正比,并且远高于核心视图,但是全图公式能够捕获不同视图之间的更多信息,这可能对下游任务是有用的。 另外全图公式还可以自然地处理缺失的信息。
对比损失的实现
通过使用较多的负样本可以学到更好的表示。在极端情况下,可以将每个数据样本都包含在公式2的分母中。
然而,对于像 ImageNet 这样的大型数据集,计算完整的 softmax 损失是非常昂贵的。可以使用噪声对比估计(Noise-Contrastive Estimation)减轻计算负载。但本文作者采用的另一种解决方案是随机采样 m 个负样本并进行简单的 (m+1) 路 softmax 分类。
同时,作者维护了一个 Memory Bank 来存储每个训练样本的潜在特征。因此可以有效地从内存缓冲区中检索负样本来与每个正样本配对而无需重新计算特征。 Memory Bank 使用动态计算的特征进行动态更新,其好处是可以与更多的负样本进行对比,但代价是特征略微陈旧。
个人总结
CMC提出的主要的创新点在于“核心视图(Core View)”和“全图(Full Graph)”两种多视图的对比方法,一个是低成本,一个是高信息量,各有各的优点,可以根据实际应用的场景做不同的选择,比如多个视角基本是平等的关系(比如一个场景的不同拍摄角度)选择全图模式,统一图像的不同通道这种有侧重的可以选择核心视图模式。

















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









