







文章目录
1.问题概述
之前介绍了这个t检验的类型:
1)单样本t检验:
2)配对样本t检验:
3)独立样本t检验:
下面的三个题目分别对应上面的三个类型,可以简单的实践一下:因为之前的这个理论并不有利于我们的理解,在一个真实的案例里面,我们可以更加清楚的知道这个参数的具体含义,以及我们的这个检验方法的适用场景
2.单个样本t检验
2.1问题分析
t = x ˉ − μ 0 s / n t=\frac{\bar{x}-\mu _0}{{{s}\Bigg/{\sqrt{n}}}} t=s/nxˉ−μ0
1)上面的这个公式里面,分母就是我们的平均值减去这个已知的这个常数值;
2)s表示的就是我们的这个样本的标准差;
3)n表示的是我们的这个样本的数量;
我们的这个题目的目的就是比较我们的这个样本和这个题目上面已知的这个真实值之间是不是存在显著性差异
因此:我们做出下面的这个假设:
1)零假设:我们的这个样本的平均值等于我们的这个已知的真实值;
2)备选假设:我们的这个样本的平均值不等于我们的已知的真实值;
2.2matlab代码
% 第一题:单样本 t 检验
% 数据输入
hl = [20.99, 20.41, 20.10, 20.00, 20.91, 22.60, 20.99, 20.41, 20.00, 23.00, 22.00];
mu_0 = 20.7; % 真值
% 进行单样本 t 检验
[h, p, ci, stats] = ttest(hl, mu_0);
% 输出检验结果
fprintf('单样本 t 检验结果:\n');
fprintf('t 值: %.4f\n', stats.tstat);
fprintf('p 值: %.4f\n', p);
fprintf('自由度: %d\n', stats.df);
fprintf('95%% 置信区间: [%.4f, %.4f]\n', ci(1), ci(2));
fprintf('样本均值: %.4f\n\n', mean(hl));
下面的这个就是matlab的运行结果:

2.3结果分析
1)首先这个stats就是一个结构体类型的数据,因此这个里面我们可以从这个stat结构体里面获取很多的数据
2)p=0.3125表示我们的这个p大于这个显著性水平,因此这个是无法拒绝零假设的;
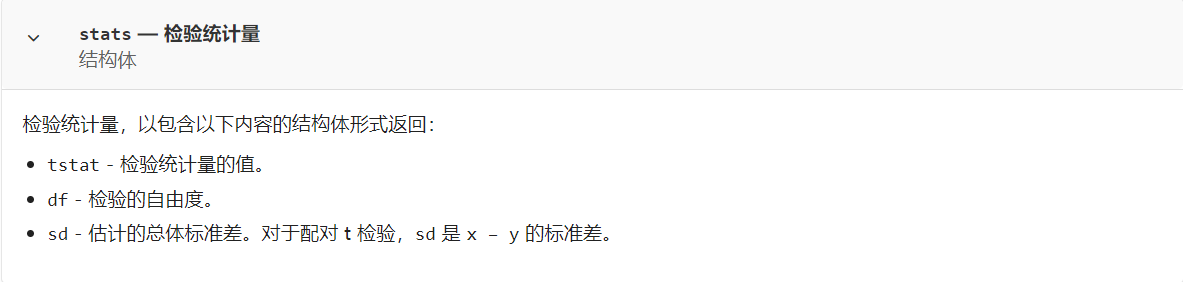
3)我们的这个理论值也是在这个置信区间里面的,因此进一步验证我们的这个真实值和我们的这个测量值之间的这个差异并不显著;
3.配对样本t检验
3.1问题分析
我们的这个题目就是想要比较这个不同处理下面的这个测试的结果,判断他们之间是不是存在显著性的差异;
我们根据这个题目的要求进行下面的这个假设:
1)零假设:两个方法的这个均值差异就是0;
2)备择假设:两个方法之间的这个均值差异不是0;
计算公式:
t
=
d
ˉ
S
d
/
n
t=\frac{\bar{\boldsymbol{d}}}{{{\boldsymbol{S}_{\boldsymbol{d}}}\Bigg/{\sqrt{\boldsymbol{n}}}}}
t=Sd/ndˉ
这个里面的这个参数的含义如下:
1)d把就是我们的这个样本的差值的平均值;
2)Sd就是我们的这个差值的标准差;
3)n表示的就是我们的这个配对样本的数量情况;
3.2代码求解
% 第二题:配对样本 t 检验
% 数据输入
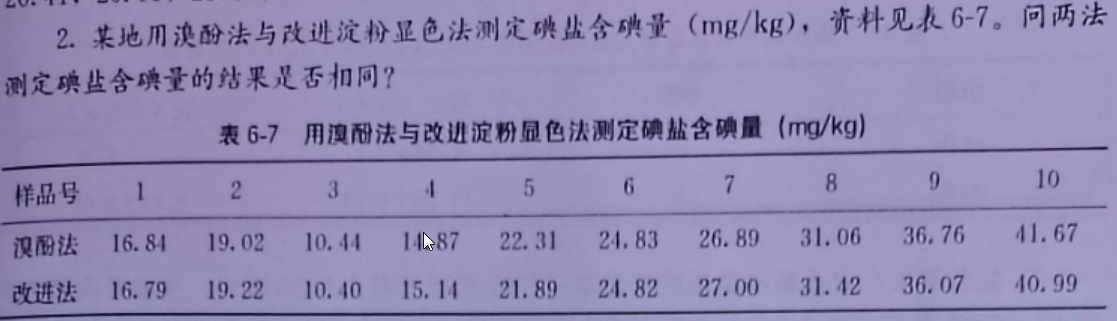
xf = [16.84, 19.02, 10.44, 14.87, 22.31, 24.83, 26.89, 31.06, 36.76, 41.67];
gj = [16.79, 19.22, 10.40, 15.14, 21.89, 24.82, 27.00, 31.42, 36.07, 40.99];
% 进行配对样本 t 检验
[h, p, ci, stats] = ttest(xf, gj);
% 输出检验结果
fprintf('配对样本 t 检验结果:\n');
fprintf('t 值: %.4f\n', stats.tstat);
fprintf('p 值: %.4f\n', p);
fprintf('自由度: %d\n', stats.df);
fprintf('95%% 置信区间: [%.4f, %.4f]\n', ci(1), ci(2));
fprintf('均值差: %.4f\n\n', mean(xf - gj));
求解结果如下:

3.3结果分析
我们的这个p大于这个显著性水平,因此这个是无法拒绝我们的零假设的,这个表名我们的常规方法和改进之后的这个方法之间不存在很显著的差异;
4.独立样本t检验
4.1问题分析
这个题目主要就是比较两个样本之间的平均值,判断我们的这个正常人和患者之间的这个水平差异;
1)零假设:两组之间的这个均值相等
2)备择假设:两组之间的这个均值不相等;
t统计量的计算公式:
1)分子表示的就是我们的两组样本之间的这个平均值;
2)分母里面的这个n表示的就是我们的样本的数量;
t
=
x
ˉ
1
−
x
ˉ
2
S
p
1
n
1
+
1
n
2
t=\frac{\bar{x}_1-\bar{x}_2}{S_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}
t=Spn11+n21xˉ1−xˉ2
下面的这个就是我们的Sp计算公式:表示的就是我们的合并标准差,s表示的是我们的各自样本的标准差
S
p
=
(
n
1
−
1
)
S
1
2
+
(
n
2
−
1
)
S
2
2
n
1
+
n
2
−
2
S_p=\sqrt{\frac{\left( n_1-1 \right) {S_1}^2+\left( n_2-1 \right) {S_2}^2}{n_1+n_2-2}}
Sp=n1+n2−2(n1−1)S12+(n2−1)S22
4.2代码求解
% 第三题:独立样本 t 检验
% 数据输入
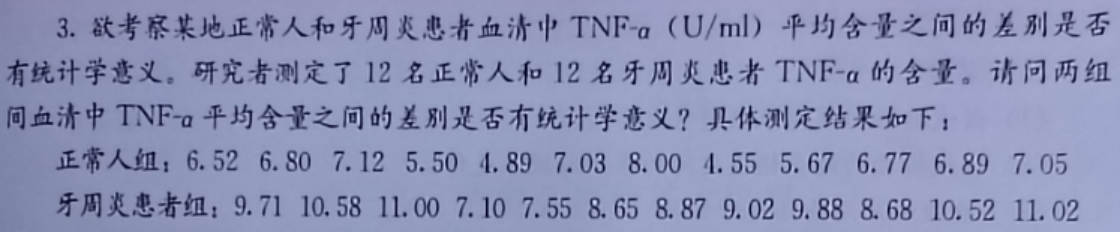
zc = [6.52, 6.80, 7.12, 5.50, 4.89, 7.03, 8.00, 4.55, 5.67, 6.77, 6.89, 7.05];
no_zc = [9.71, 10.58, 11.00, 7.10, 7.55, 8.65, 8.87, 9.02, 9.88, 8.68, 10.52, 11.02];
% 进行独立样本 t 检验(假设方差相等)
[h, p, ci, stats] = ttest2(zc, no_zc, 'Vartype', 'equal');
% 输出检验结果
fprintf('独立样本 t 检验结果:\n');
fprintf('t 值: %.4f\n', stats.tstat);
fprintf('p 值: %.4f\n', p);
fprintf('自由度: %d\n', stats.df);
fprintf('95%% 置信区间: [%.4f, %.4f]\n', ci(1), ci(2));
fprintf('正常人均值: %.4f\n', mean(zc));
fprintf('牙周炎患者均值: %.4f\n\n', mean(no_zc));
计算结果展示:

4.3结果分析
上面的这个结果表明:
1)p值比这个显著性水平低,因此我们拒绝零假设;
2)这个可以证明我们的这个正常人和患者之间的这个含量存在差别,且我们的这个患者的这个血清物质含量高于我们的正常人的标准2~4不等;
计算结果展示:

4.3结果分析
上面的这个结果表明:
1)p值比这个显著性水平低,因此我们拒绝零假设;
2)这个可以证明我们的这个正常人和患者之间的这个含量存在差别,且我们的这个患者的这个血清物质含量高于我们的正常人的标准2~4不等;

















 2351
2351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









