









前言 :
这篇主要讲logistic回归,虽然名字上是回归,但很多时候我们都将他用于分类,由于这一章公式比较多,而且第一次遇到了最优化算法,所以本文大部分会放在相关数学公式的证明和理解上,代码实现部分之后再补充。
先解释一下什么是回归,我们经常会接触到一些数据点,希望拟合一条直线或者曲线去近似他,从而预测其他未知变量的值,而这个拟合过程就称作回归。而logistic回归解决分类问题的主要思想就是根据现有数据对分类边界建立回归公式,通过回归得到最优分类边界的参数,从而对到来的数据点实施分类。训练分类器的做法就是寻找最佳参数拟合,使用的是最优化算法,常见的优化算法有梯度上升和梯度下降法,牛顿法和拟牛顿法,共轭梯度法,启发式优化方法和拉格朗日乘数法,书中的Logistic回归分类方法中将采用梯度上升法实现最优化,下面就看一下书中的二值形输出分类器。
1.logistic回归
首先考虑一个二分类任务,其输出标记即为y=[0,1],而线性回归产生的预测值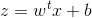
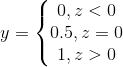
即若预测值大于零就判别为正例,小于零则判断为反例。
但是我们可以看到,单位跃阶函数并不连续,所以不能用作我们的映射f(),于是我们希望找到能在一定程度上近似单位跃阶函数的替代,并希望他单调可微,对数几率函数(logistic function)正是这样一个常用的替代函数:
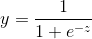
先动手看看这个函数长什么样~
import math
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(-12,12,0.1)
y = 1/(1+math.e**(-x))
plt.plot(x,y)
plt.show()
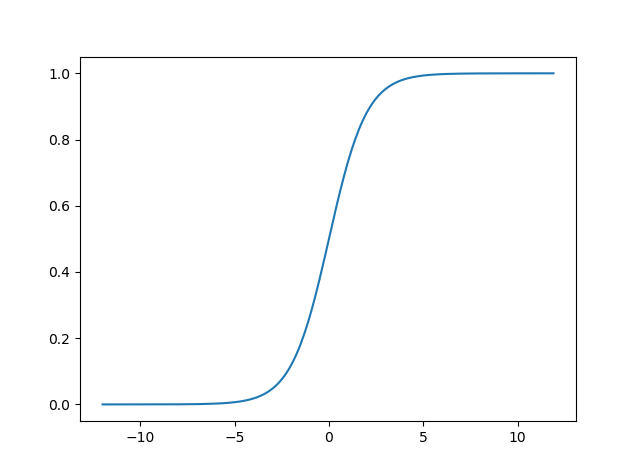
(对数几率函数)
这里说一下Sigmoid函数,Sigmoid函数即形似S形的函数,而对数几率函数是Sigmoid函数的重要代表,由上图可以看到,对数几率函数是一种Sigmoid函数,他将z值转化为接近0或1的值,并且其输出值在0附近变化很陡,将对数几率函数作为我们的映射f(),得到了:
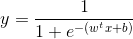
通过对数转化,我们可以得到:
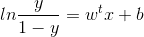
如果将 y 视为正例即 y=0 的可能性,则 1-y 是其反例 y=1 的可能性,两者的比值:
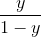
称为“几率”,反映了x作为正例的相对可能性,对几率取对数则得到“对数几率”,又叫logit:
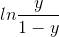
由此可以看出,式1.1 实际上是用线性回归模型的预测结果去逼近真实标记的对数几率,因此,其对应模型称为“对数几率回归”,也就是我们说的logistic回归。这种方法有很多优点,他可以直接对分类可能性建模,无需事先假设数据分布,从而避免了假设分布不准确造成的问题,而且不仅可以预测出类别,还能预测出近似概率,这对许多需要概率辅助决策的问题很有用,此外,对率函数是任意阶可导的凸函数,有很好的数学性质,可以用于求最优解。
2.梯度上升法
有了映射 f() ,下面我们捋一捋我们实现分类的步骤:
1)给定特征x,这里x不局限在1维,我们乘以回归系数得到
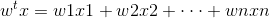
2)计算
3)f(z)> 0.5 正例,f(z)< 0.5 ,反例,实现分类
有了这个分类步骤,我们需要做的事就很清楚了,那就是找到一组最佳的权数w,使得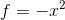
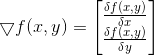
这是一个二维变量的梯度表示,表示要沿x的方向移动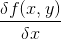
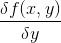
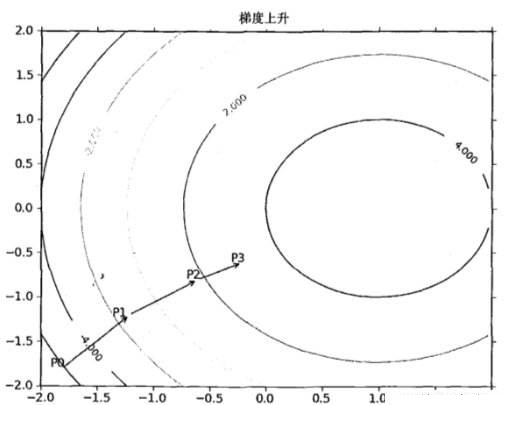
梯度上升法每达到一个点都会重新估计移动的方向,从P0开始,根据梯度移动到P1点,在P1点,再次重新计算梯度,并沿新的方向到达P2,如此迭代循环,直到满足停止条件(达到某一阈值,精度达到一定要求,或达到预定迭代次数)。迭代的过程中,梯度算子总是能找到最佳的移动方向。可以看到,梯度算子总是向函数值增长最快的地方,这里所说的是移动方向,而未提到移动量的大小,该量值称为步长,记作alpha,用向量表示的话,梯度上升法的迭代公式如下:
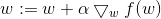
该公式将一直被迭代进行,直到达到停止条件,与之对应的便是梯度下降法,他的迭代公式如下:
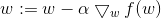
梯度上升法用于求函数的最大值,相应的,梯度下降法用于求函数的最小值。
下面我们用最简单的二次函数,分别用梯度上升法和梯度下降法求极大值点与极小值点:
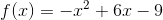
#梯度上升法
def f_grad(xt):#对函数求导
return -2 * xt + 6
def max_xt():#迭代求极值点
xt = 0#给定初值
xtplus = 5
alpha = 0.01#步长
presision = 0.00001#迭代停止精度
while abs(xtplus-xt) > presision:
xt = xtplus
xtplus = xt + alpha * f_grad(xt)#梯度上升法
return xtplus
xtplus = max_xt()
print(max_xt())
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-10,10)
y = -x*x+6*x-9
plt.plot(x,y)
plt.scatter(xtplus,-xtplus*xtplus+6*xtplus-9,color = 'red')
plt.show()3.000485482054297
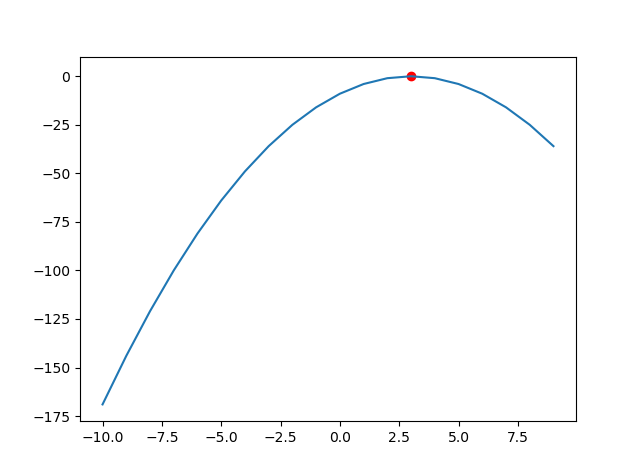
这里和我们正常解一元二次方程得到的解3.0很接近,如果设置精度更大,他可以更加逼近,不过效果我们已经看到了。
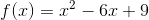
#梯度下降法
def f_grad(xt):#函数求导
return 2 * xt - 6
def min_xt():
xt = 0#设置初值
xtplus = 5
alpha = 0.01#设置步长
presision = 0.00001#迭代停止精度
while abs(xtplus-xt) > presision:
xt = xtplus
xtplus = xt - alpha * f_grad(xt)#梯度下降法,两个方法只是相差在一个正负号
return xtplus
xtplus = min_xt()
print(xtplus)
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-10,10)
y = x*x-6*x+9
plt.plot(x,y)
plt.scatter(xtplus,xtplus*xtplus-6*xtplus+9,color = 'red')
plt.show()
3.000485482054297
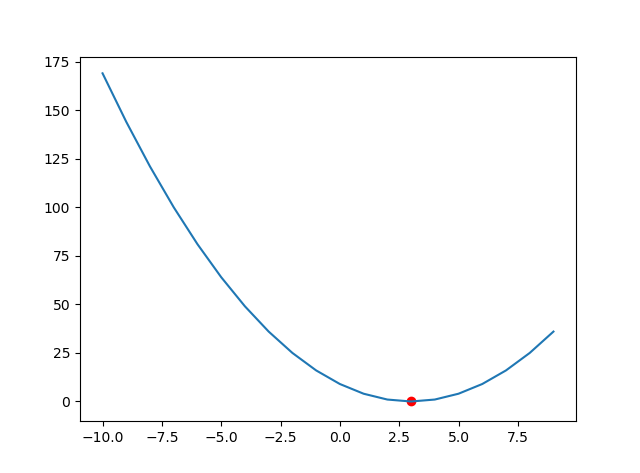
到这里,我们就大致了解了如何实现梯度上升法或梯度下降法了,就是简单的迭代,可以这么说,梯度决定了走的方向,步长定了每一步走的多远,就像沿着向量方向移动指定长度一样。
3.logistic回归与梯度优化
下面我们看一下《机器学习实战》中的梯度上升法优化:
1)Sigmoid函数求导
这里
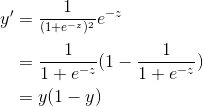
2)迭代更新公式
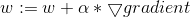
3)logistic回归
先看一下书中代码是如何实现logistic回归的:
def gradAscent(dataMatIn,classlabels):
dataMatrix = mat(dataMatIn)#转化为矩阵形式
labelMat = mat(classlabels).transpose()
#转化为矩阵形式 transpose为转置 100x1
m,n = shape(dataMatrix)#提取矩阵的行数,列数
alpha = 0.001#设置步长alpha
maxCycles = 500#设置迭代次数
weights = ones((n,1))#初始化w 均位1,长度与列数一致
for k in range(maxCycles):#执行梯度优化
h = sigmoid(dataMatrix*weights)
error = (labelMat-h)
weights = weights + alpha *dataMatrix.transpose()*error
return weights#返回迭代次数内的最优系数w代码实现关键就在error处,即用标签值减去预测的标签值,通过最小化误差寻找最优权数w。
h = sigmoid(dataMatrix*weights)
error = (labelMat-h)proof:
这里我们先规定logsitic函数的形式:
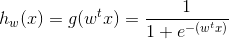
然后分析分类问题,y有两种取值0和1,根据这个概率p ( y=1 | x,w ) = h(x) , 所以p ( y=0 | x,w ) = 1-h(x),我们把两个概率结合起来,得到:
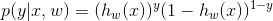
现在我们可以开始求Logistic回归系数了,因为logistic回归可以看做是一种概率模型,y发生的概率与w有关,因而我们可以对w使用极大似然估计(极大似然估计的知识推荐看《统计学完全教程》,讲的比较全面),使y发生的概率最大,此时的w便是我们寻找的最优回归参数,现根据概率密度写出极大似然函数:
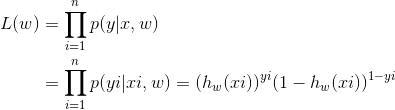
取对数得到对数极大似然函数:
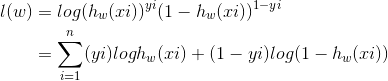
现在要使用梯度上升法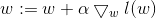
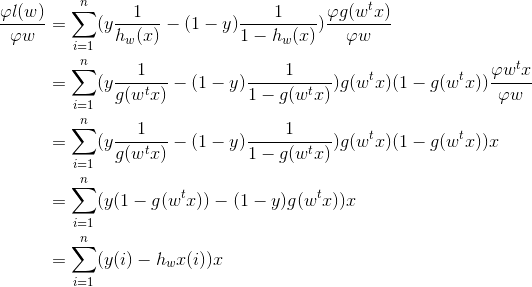
这里yi对应书中labelMat的标签值,h(xi)对应sigmoid函数的输出值,将梯度带入公式:
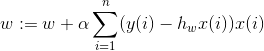
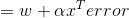
这就得到了书中梯度上升法的最后一步迭代,这里alpha是步长,决定梯度上升的快慢。
weights = weights + alpha *dataMatrix.transpose()*error总结:
终于把这一篇公式打完啦~主要开始看书时没有看懂error到gradient那一步,所以就翻书去寻找了logistic回归分类的证明,logistic回归分类的基本步骤就是首先搞清楚我们任务的目的(求最大值,梯度上升法,求最小值,梯度下降法),然后构建目标函数,对目标函数求梯度,然后设置适当的步长从而实现迭代,找到我们需要的最优解。下篇文章将重心放在代码实现上,相信有了理论基础的前提,编写代码一定会轻松很多,想了解更多logistic回归的内容,大家可以参考西瓜书,欢迎大家交流~
















 940
940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











