






项目github地址:bitcarmanlee easy-algorithm-interview-and-practice
欢迎大家star,留言,一起学习进步
1.spark官网上transformation api
spark transformation的所有操作如下图所示。

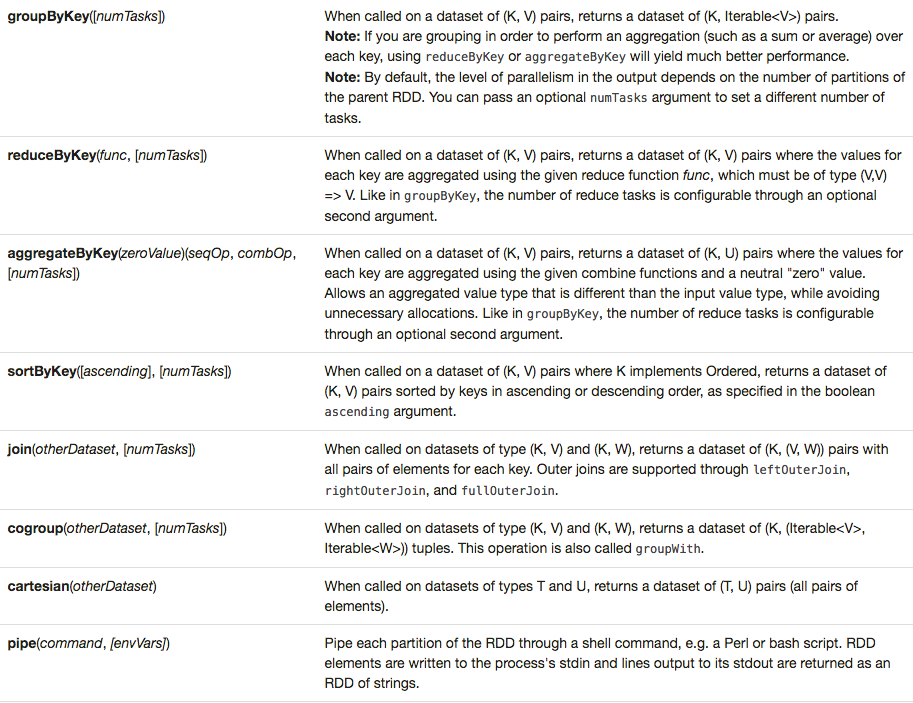

图片在页面中看不太清楚,同学们可以右键在新标签页中查看清晰版本。
针对api中常用的一些方法进行说明,以下的代码均在spark-shell中测试通过,spark版本为1.6。
1.map(func)
map无疑是最重要也是最基本的操作了。map将一个rdd的每个数据项通过map中的func映射成一个新的元素。
scala> val mapped = sc.parallelize(1 to 10).map(x => x * 2).collect
mapped: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
2.filter(func)
filter也是一个很常用也很重要的操作。filter返回一个新的数据集,由经过func函数后返回值为true的原元素组成。
scala> val filtered = sc.parallelize(1 to 10).filter( x => x%2 == 0).collect
filtered: Array[Int] = Array(2, 4, 6, 8, 10)
3.flatMap(func)
flatMap类似于map,但是比map多了一个flat动作。每一个输入元素,会被映射为0到多个输出元素。而且func函数的返回值是一个Seq,不能是单一元素。
看两个例子
scala> val flatted = sc.parallelize(Seq("hello world","hello spark","hello hive","hello hadoop")).flatMap(x => x.split(" ")).collect
flatted: Array[String] = Array(hello, world, hello, spark, hello, hive, hello, hadoop)
可以看出,flatMap可以用来切分字段
再来一个例子
scala> val res = sc.parallelize(1 to 3).flatMap(x => 1 to x).collect
res: Array[Int] = Array(1, 1, 2, 1, 2, 3)
对原RDD中的每个元素x产生一共x个元素,元素分别为1到x。
4.distinct([numTasks])
只要是搞数据或者接触过数据库的童鞋们对distinct肯定不陌生,甚至可以说是刻骨铭心,日常工作中最常见的需求就是去重排序了。去重,自然就是distinct做的事情。
distinct返回的是原数据集合中不重复的元素构成的一个新数据集。跟前面的几个方法不一样的地方在于,前面几个方法需要接收一个func的参数,而distinct只有一个可选参数为numTasks。
scala> val rdd = sc.parallelize(Array(1,1,2,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:27
scala> val distincted = rdd.distinct.collect
distincted: Array[Int] = Array(1, 2, 3, 4, 5)
5.union(otherDataset)
union在数据库中也是非常常见的操作。在spark中,union操作返回一个新的数据集,新的数据集由原来的数据集与传入的数据集联合产生。
scala> val rdd1 = sc.parallelize(1 to 3)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:27
scala> val rdd2 = sc.parallelize(1 to 10)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at parallelize at <console>:27
scala> val unioned = rdd1.union(rdd2).collect
unioned: Array[Int] = Array(1, 2, 3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
6.intersection(otherDataset)
与union类似,intersection返回的是两个rdd的交集。
scala> val rdd1 = sc.parallelize(1 to 3)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:27
scala> val rdd2 = sc.parallelize(1 to 10)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at parallelize at <console>:27
scala> val unioned = rdd1.intersection(rdd2).collect
unioned: Array[Int] = Array(1, 2, 3)
7.reduceByKey(func,[numTasks])
顾名思义,reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行reduce。相同的key对应的多个元素会被reduce为一个值,然后与原来的key组成一个新的kv对。
scala> val rdd = sc.parallelize(List((1,2),(3,4),(3,5)))
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[1] at parallelize at <console>:27
scala> rdd.reduceByKey((x,y) => x+y).collect
res0: Array[(Int, Int)] = Array((1,2), (3,9))
上面的这个例子是对相同的key对应的value做相加的操作,最后返回的是key与对应的value的和。
再来看一个例子
scala> val rdd = sc.parallelize(List((1,2),(3,4),(3,5)))
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[1] at parallelize at <console>:27
scala> rdd.reduceByKey((x,y) => x+y).collect
res0: Array[(Int, Int)] = Array((1,2), (3,9))
这个例子返回的是key与对应的value的最大值
8.groupByKey([numTasks])
这个函数用于将RDD[K,V]中每个K对应的V值,合并到一个集合Iterable[V]。
看个例子就明白了:
scala> val rdd = sc.parallelize(List((1,2),(1,4),(3,4),(3,5)))
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[6] at parallelize at <console>:27
scala> rdd.groupByKey().collect
res3: Array[(Int, Iterable[Int])] = Array((1,CompactBuffer(2, 4)), (3,CompactBuffer(4, 5)))
9.sortByKey([ascending],[numTasks])
这个函数的输入源RDD包含元素类型 (K, V) 对,其中K可排序,则返回新的RDD包含 (K, V) 对,并按照 K 排序,默认为升序。
scala> val rdd = sc.parallelize(List((1,5),(2,4),(4,6),(1,3),(4,5)))
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[24] at parallelize at <console>:27
scala> rdd.sortByKey().collect
res9: Array[(Int, Int)] = Array((1,5), (1,3), (2,4), (4,6), (4,5))
10.join(otherDataset,[numTasks])
join是关系型数据库中最牛逼的操作,没有之一。作为一个牛逼闪闪的数据框架,自然也支持join操作。某一个rdd[k,v]与另外一个rdd[k,w]去join,返回一个rdd[k,(v,w)]。
scala> var rdd1 = sc.makeRDD(Array(("A","1"),("B","2"),("C","3")))
rdd1: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[31] at makeRDD at <console>:27
scala> var rdd2 = sc.makeRDD(Array(("A","a"),("C","c"),("D","d")))
rdd2: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[32] at makeRDD at <console>:27
scala> rdd1.join(rdd2).collect
res10: Array[(String, (String, String))] = Array((A,(1,a)), (C,(3,c)))
















 1885
1885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









