







项目github地址:bitcarmanlee easy-algorithm-interview-and-practice
欢迎大家star,留言,一起学习进步
1.核函数把低维空间映射到高维空间
下面这张图位于第一、二象限内。我们关注红色的门,以及“北京四合院”这几个字下面的紫色的字母。我们把红色的门上的点看成是“+”数据,紫色字母上的点看成是“-”数据,它们的横、纵坐标是两个特征。显然,在这个二维空间内,“+”“-”两类数据不是线性可分的。

我们现在考虑核函数
K
(
v
1
,
v
2
)
=
<
v
1
,
v
2
>
2
K(v_1,v_2) = <v_1,v_2>^2
K(v1,v2)=<v1,v2>2,即“内积平方”。
这里面
v
1
=
(
x
1
,
y
1
)
v_1=(x_1,y_1)
v1=(x1,y1),
v
2
=
(
x
2
,
y
2
)
v_2=(x_2,y_2)
v2=(x2,y2)是二维空间中的两个点。
这个核函数对应着一个二维空间到三维空间的映射,它的表达式是:
P
(
x
,
y
)
=
(
x
2
,
2
x
y
,
y
2
)
P(x,y)=(x^2,\sqrt{2}xy,y^2)
P(x,y)=(x2,2xy,y2)
在P这个映射下,原来二维空间中的图在三维空间中的像是这个样子:
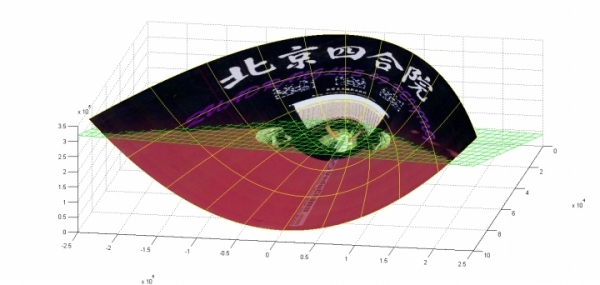
前后轴为x轴,左右轴为y轴,上下轴为z轴)
注意到绿色的平面可以完美地分割红色和紫色,也就是说,两类数据在三维空间中变成线性可分的了。
而三维中的这个判决边界,再映射回二维空间中是这样的:

这是一条双曲线,它不是线性的。
如上面的例子所说,核函数的作用就是隐含着一个从低维空间到高维空间的映射,而这个映射可以把低维空间中线性不可分的两类点变成线性可分的。当然,我举的这个具体例子强烈地依赖于数据在原始空间中的位置。事实中使用的核函数往往比这个例子复杂得多。它们对应的映射并不一定能够显式地表达出来;它们映射到的高维空间的维数也比我举的例子(三维)高得多,甚至是无穷维的。这样,就可以期待原来并不线性可分的两类点变成线性可分的了。
2.常见的核函数
在机器学习中常用的核函数,一般有这么几类,也就是LibSVM中自带的这几类:
- 线性: K ( v 1 , v 2 ) = < v 1 , v 2 > K(v_1,v_2)=<v_1,v_2> K(v1,v2)=<v1,v2>
- 多项式: K ( v 1 , v 2 ) = ( γ < v 1 , v 2 > + c ) n K(v_1,v_2)=(\gamma<v_1,v_2>+c)^n K(v1,v2)=(γ<v1,v2>+c)n
- Radial basis function: K ( v 1 , v 2 ) = exp ( − γ ∣ ∣ v 1 − v 2 ∣ ∣ 2 ) K(v_1,v_2)=\exp(-\gamma||v_1-v_2||^2) K(v1,v2)=exp(−γ∣∣v1−v2∣∣2)
- Sigmoid: K ( v 1 , v 2 ) = tanh ( γ < v 1 , v 2 > + c ) K(v_1,v_2)=\tanh(\gamma<v_1,v_2>+c) K(v1,v2)=tanh(γ<v1,v2>+c)
我举的例子是多项式核函数中 γ = 1 \gamma=1 γ=1, c = 0 c=0 c=0, n = 2 n=2 n=2的情况。
3.核函数的性质
核函数只是满足某些必要条件的函数,其作用要与具体的算法结合才能显示出来。
我来简明说一下SVM中核技巧(kernel trick)的作用,一句话概括的话,就是降低计算的复杂度,甚至把不可能的计算变为可能。
核函数有如下一个性质:
K
(
x
1
,
x
2
)
=
ϕ
(
x
1
)
∗
ϕ
(
x
2
)
K(x_1,x_2) = \phi (x_1)*\phi(x_2)
K(x1,x2)=ϕ(x1)∗ϕ(x2)
其中 ϕ ( x ) \phi(x) ϕ(x) 是对 x x x做变换的函数,有些变换会将样本映射到更高维的空间,如果这个高维空间内 x 1 x_1 x1与 x 2 x_2 x2是线性可分的,那么我们就做了一次成功的变换。核函数是二元函数,输入是变换之前的两个向量,其输出与两个向量变换之后的内积相等(这个性质非常重要)
4.核函数与SVM
求解SVM时,其原始形式(这里我们假设已经对原始的输入做了变换,即输入模型的样本变成了 ϕ ( x ) ) \phi(x)) ϕ(x))
1
2
w
T
w
+
C
∑
1
N
β
i
\frac{1}{2}w^{T}w + C\sum_{1}^{N}{\beta_i}
21wTw+C1∑Nβi s.t.
y
i
(
w
T
ϕ
(
x
i
)
+
b
)
≥
1
−
β
i
y_i(w^{T}\phi(x_i)+b) \geq 1 - \beta_i
yi(wTϕ(xi)+b)≥1−βi
β
i
≥
0
\beta_i \geq 0
βi≥0
i = 1 , 2… N(N为样本个数)
这是个二次规划,因为未知量的个数是参数w的维度,而w的维度与样本的维度相等,即等于变换后 ϕ ( x ) \phi(x) ϕ(x)的的维度,所以其求解复杂度与样本的维数正相关,这意味着,如果我们把原始样本从十维空间变换到一万维的空间,那么求解该问题的时间复杂度提升了1000倍或者更多,我们知道有些变换可以将样本换边到无穷维空间,那么这种变化之后直接是不可求解的。上面的问题可以使用对偶 + 核技巧的组合来解决。
我们也知道,SVM原始形式的对偶问题是:
∑ i = 1 N ∑ j = 1 N α i α j y i y j ϕ ( x i ) T ϕ ( x j ) − ∑ i = 1 N α i \sum_{i=1}^{N}\sum_{j=1}^{N}{\alpha_i\alpha_jy_iy_j\phi(x_i)^{T}\phi(x_j)} - \sum_{i=1}^{N}{\alpha_i} i=1∑Nj=1∑Nαiαjyiyjϕ(xi)Tϕ(xj)−i=1∑Nαi s.t.
0
≤
α
i
≤
C
0\leq\alpha_i\leq C
0≤αi≤C
∑
i
=
1
N
y
i
α
i
=
0
\sum_{i=1}^{N}{y_i\alpha_i} = 0
i=1∑Nyiαi=0
很明显,未知量 α \alpha α的个数与样本的个数是相等的,那么这个对偶问题计算的时间复杂度是与训练样本的个数正相关的(这也是为啥样本个数太多的时候不推荐使用带核技巧的SVM的原因)。
仅仅做对偶还没有解决问题,因为在$ \sum_{i=1}{N}\sum_{j=1}{N}{\alpha_i\alpha_jy_iy_j\phi(x_i)^{T}\phi(x_j)} - \sum_{i=1}^{N}{\alpha_i} $ 中还要求 ϕ ( x i ) T ϕ ( x j ) \phi(x_i)^{T}\phi(x_j) ϕ(xi)Tϕ(xj),这就需要将样本先变换到高维空间,然后再求在高维空间内的内积,这样的变换还是需要很多计算资源。等等,我们说过核函数的作用是“核函数是二元函数,输入是变换之前的两个向量,其输出与两个向量变换之后的内积相等”,所以我们可以用 K ( x i , x j ) K(x_i,x_j) K(xi,xj)来代替$\sum_{i=1}{N}\sum_{j=1}{N}{\alpha_i\alpha_jy_iy_j\phi(x_i)^{T}\phi(x_j)} - \sum_{i=1}^{N}{\alpha_i} 中 的 中的 中的\phi(x_i)^{T}\phi(x_j)$,避免了显式的特征变换。于是,使用对偶+核技巧,我们成功解决了问题。
5.相关视频地址
原文链接:https://www.zhihu.com/question/24627666
根据原文链接整理而来















 5176
5176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









