







演示视频:【从堆的定义到优先队列、堆排序】 10分钟看懂必考的数据结构——堆_哔哩哔哩_bilibili
一.什么是堆?
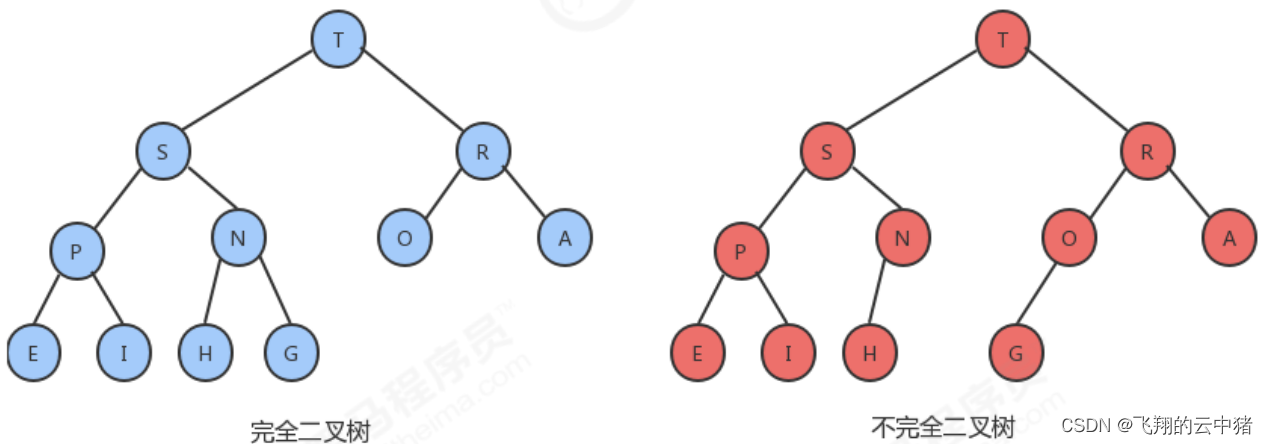
2.堆分为两类,大根堆和小根堆。
大根堆每个结点都大于等于它的两个子结点,这里要注意堆中仅仅规定了每个结点大于等于它的两个子结点,但这两个子结点的顺序并没有做规定,跟二叉查找树是有区别的。
小根堆则是小于等于它的两个子结点。
二.堆的实现
堆通常用数组来实现
具体方法就是讲二叉树的结点按照层级顺序放入数组中,根结点在位置1,它的子节点在位置2和3,而子节点的子节点则分别在位置4,5,6,7,以此类推。
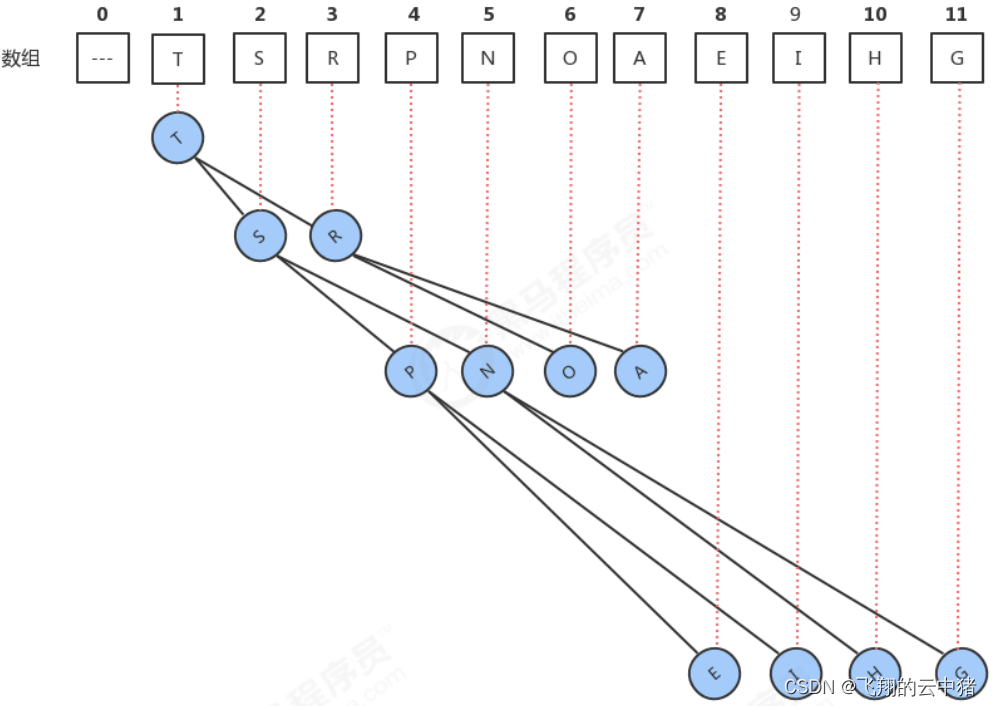
上面这张图是从1开始的,但是我习惯从0开始(因为数组的索引一般是从0开始)。
如果索引从1开始的话如果一个父结点的下标为i,则它的父结点的位置为i/2,而它左右子树的根结点为2i+1和2i+2。最后一个非叶子结点的值是n / 2。
如果索引从0开始的话父节点是(i-1)/2,最后一个非叶子结点的值是n/2-1。
这样在不适用指针的情况下,我们也可以通过计算数组的索引在堆中上下移动。
三.堆的基本操作【上滤,下滤,建堆】
1.下滤
只有树的根元素破坏了堆序性。
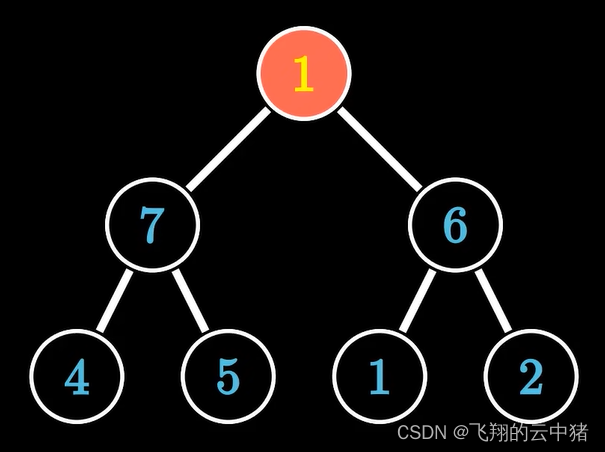
我们将破坏堆序性的元素与他的最大子结点比较,如果小于他的最大子结点,如果小于他的最大子结点,则与之交换,持续比较交换,直到该元素大于他的子节点为止,或者移动到底部为止,此时该树就成功地被调整成一个大根堆。我们把根结点向下调整的操作称为下滤,很容易看出复杂度为logN。
void heapify(vector<int>& arr, int n, int i) {
int largest = i; // 初始化根节点为最大值
int left = 2 * i + 1; // 左子节点
int right = 2 * i + 2; // 右子节点
// 如果左子节点比根节点大,更新最大值索引
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
// 如果右子节点比当前最大值大,更新最大值索引
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
// 如果最大值索引不是当前根节点,交换根节点和最大值节点
if (largest != i) {
std::swap(arr[i], arr[largest]);
// 递归地对交换后的子树进行堆化
heapify(arr, n, largest);
}
}
2.上滤
只有树的最后一个元素破坏了堆序性。
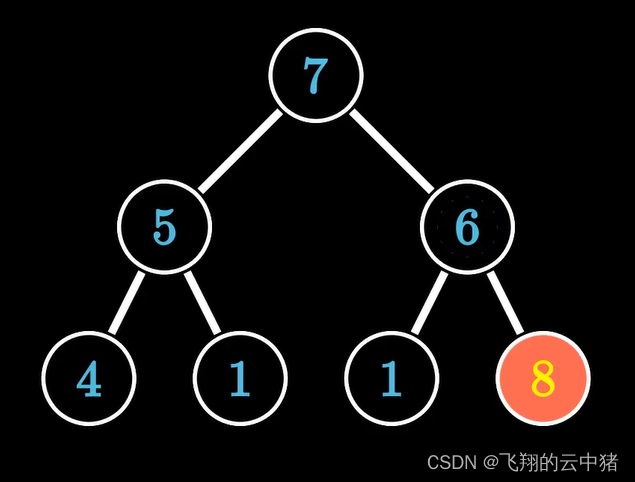
同理让它和它的父元素比较,若大于父节点则交换,直到无法上移为止。
这个操作主要用于插入新元素到堆中。复杂度也为logN。
3.建堆
如果有一个乱序的数组,怎么操作让它整理为堆呢?
有两种方法,一种方法为自顶向下建堆法,对应的操作为上滤。
【1】自顶向下建堆法--复杂度:O(nlogn)
方法:插入堆->上滤
【2】自下向上建堆法--复杂度:O(n)
方法:对每个父结点进行下滤
所以一般选择自下而上建堆法和下滤操作。下面是用自下而上建堆法构造大顶堆的代码:
将前面的下滤函数heapify比较改成小于号就变成构造小顶堆。
void buildHeap(vector<int>& arr) {
int n = arr.size();
// 从最后一个非叶子节点开始,依次进行堆化,最后一个叶子节点对应的索引是n/2-1
for (int i = n / 2 - 1; i >= 0; --i) {
heapify(arr, n, i);
}
}c++中的算法库中提供make_heap函数快速建堆。
四.堆排序及实现步骤
1. 构造堆(如果要从小到大则构造大顶堆,否则小顶堆)
2.得到堆顶元素,这个值就是最大值
3.交换堆顶元素和数组中的最后一个元素,此时所有元素中的最大元素已经放到了合适的位置
4.对堆顶的元素进行上滤操作,重新让除了最后一个元素的剩余元素中的最大值放到堆顶。
5.重复2-4步骤,直到堆中剩一个元素为止。
简单说就是先构造大顶堆产生最大值,将这个最大值移动到最后,然后剩下的元素再次构造大顶堆(即对最上面的元素进行上滤操作)产生最大值。
示例代码:将一个数组从小到大排序:
#include <iostream>
using namespace std;
// 调整大顶堆的函数
void heapify(int arr[], int n, int i) {
int largest = i; // 初始化最大元素为根节点
int left = 2 * i + 1;//左子树
int right = 2 * i + 2;//右子树
// 如果左子节点比根节点大,则更新最大元素的索引
if (left < n && arr[left] > arr[largest])
largest = left;
// 如果右子节点比当前最大元素大,则更新最大元素的索引
if (right < n && arr[right] > arr[largest])
largest = right;
// 如果最大元素不是根节点,则交换根节点和最大元素的位置
if (largest != i) {
swap(arr[i], arr[largest]);
// 继续调整以确保新的子树也满足大顶堆的性质
heapify(arr, n, largest);
}
}
// 堆排序函数
void heapSort(int arr[], int n) {
// 构建初始的大顶堆,从最后一个非叶子节点开始
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
// 依次将堆顶元素(最大值)与数组末尾元素交换,并重新调整堆
for (int i = n - 1; i > 0; i--) {
swap(arr[0], arr[i]); // 将当前最大值放到数组末尾
heapify(arr, i, 0); // 重新调整堆,排除已排序的部分
}
}
如果从大到小排序,只要将每次大顶堆产生的元素放在数组前面即可。或者修改heapify函数的符号构造小顶堆。
五.优先队列
1.什么是优先队列
首先优先队列是队列,但与普通队列不同的是,里面的元素是排序号的。
比如如果规定优先队列里面的元素从小到大排序,那么它弹出的元素就是最小元素。
2.优先队列的实现
那么优先队列是怎么实现的呢?
优先队列主要有两个操作,一种是将插入队列,另一种是弹出最小元素,采用小跟堆来进行实现。
因为小根堆的根结点本来就是最小元素,因此弹出根结点即可完成弹出操作。
弹出后要将剩下的元素调整成堆,方法也很简单,将最后一个元素放在根结点,然后下滤即可。
所以弹出的复杂度为logN。
插入操作不同多讲了,因为上滤操作本来就是插入堆的操作。直接使用即可,所以插入的复杂度也为logN。















 2795
2795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









