







 参考:深度学习中Dropout原理解析https://blog.csdn.net/program_developer/article/details/80737724目录1为什么要用 Dropout?2 什么是 Dropout?步骤:(1)训练阶段:(2)在测试模型阶段3. Dropout为什么可以解决过拟合?4 Dropout注意事项?4.1 缩放...
参考:深度学习中Dropout原理解析https://blog.csdn.net/program_developer/article/details/80737724目录1为什么要用 Dropout?2 什么是 Dropout?步骤:(1)训练阶段:(2)在测试模型阶段3. Dropout为什么可以解决过拟合?4 Dropout注意事项?4.1 缩放...
参考:
深度学习中Dropout原理解析 https://blog.csdn.net/program_developer/article/details/80737724
目录
(2)F.Dropout(x, p=0.5, training=self.training)
(3) Dropout 在 Keras 和 Pytorch 中的实现
1 为什么要用 Dropout?
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。
在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:
模型在训练数据上损失函数较小,预测准确率较高;
但是在测试数据上损失函数比较大,预测准确率较低。
为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout 可以针对这两个问题,比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
2 什么是 Dropout?
当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。Dropout 可以通过阻止特征检测器的共同作用,缓解过拟合,来提高神经网络的性能。
过程:在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如下图:
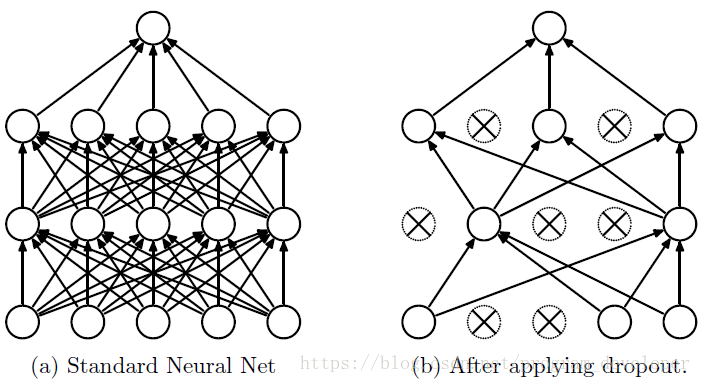
步骤:
(1)训练阶段:

- . 没有Dropout的网络计算公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3182
3182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









