







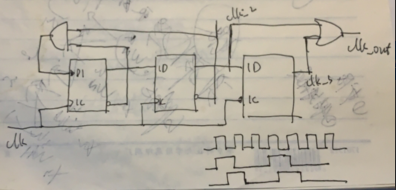
仅仅给出下面一个电路图,让你画出Q1,Q2以及Q3的波形,并描述电路功能

第一个触发器的输入是第二个以及第三个触发器的输出的反馈,是Q1与Q2的或非;实际上就是同步三分频电路;
只要触发器复位有初值即可,一般触发器复位初值为0,这里也默认为0,那么输入值在复位时应该为1.
那么当正常运行(复位无效)时,q0的第一个值为复位值延迟一拍并持续一个时钟,之后q1、q2就简单了。
module test(
input rst_n,
input clk,
output out2
);
wire in1;
reg q0, q1, q2;
always@(posedge clk or negedge rst_n) begin
if(!rst_n) begin
q0 <= 1'b0;
q1 <= 1'b0;
q2 <= 1'b0;
end
else begin
q0 <= in1;
q1 <= q0;
q2 <= q1;
end
end
assign in1 = !q0 & !q1;
assign out2 = q2;
endmodule上面的三分频电路,占空比为1/3 ,为了实现50%的占空比,需要在第二个触发器后面加上一个下降沿触发的触发器,将第二个触发器生成的三分频与延迟一拍输出的三分频相或即可,电路图如下:
module div3(clk,rst_n,dout);
input clik,rst_n;
output dout;
reg q0,q1,q2;
wire d1;
//上升沿触发的三分频,占空比为1/3
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
begin
q0 <= 1'd0;
q1 <= 1'd0;
end
else
begin
//移位
q0 <= d1;
q1 <= q1;
end
end
assign d1=~q0 & ~q1;
//将上升沿触发的三分频延时半个周期
always @(negedge clk or negedge rst_n)
begin
if(~rst_n)
q2 <= 1'd0;
else
q2 <= q1;
end
assign dout=q2 | q1;//相或得出1/2占空比
endmodule对于奇数倍分频,以N=3为例:首先使用上升沿触发生成一个1/3占空比的时钟,再用下降沿触发生成一个1/3占空比的时钟(或者将前面的时钟采用下降沿触发的FF打一拍),两者相或就可以得到一个三分频且占空比为1/2的时钟;
由D触发器构成其他的触发器

//实现JK触发器
module jk_ff(clk,rst_n,j,k,q);
input clk,rst_n;
input j,k;
output reg q;
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
q <= 1'd0;
else
q <= d;
end
assign d=(j && ~q) | (~k && q);
endmodule
//实现T触发器
module t_ff(clk,rst_n,t,q);
input clk,rst_n;
input t;
output reg q;
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
q <= 1'd0;
else
q <= d;
end
assign d=t^q;
endmodule
//实现T‘触发器
module t1_ff(clk,rst_n,q);
input clk,rst_n;
output reg q;
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
q <= 1'd0;
else
q <= d;
end
assign d=~q;
endmodule
常见的分频电路原理图:


实质上就是一个4位的计数器,由Q0输出为二分频,由Q1输出为4分频,由Q2输出为8分频,由Q3输出为16分频;
一般的FPGA中触发器主要是D触发器,D触发器与T触发器之间的转换关系如下:

所以用D触发器来构成上面的计数器,电路图如下:

//计数器其实就是分频器
module div_2(clk,rst_n,q0,q1,q2,q3);
input clk,rst_n;
output reg q0,q1,q2,q3;
wire d0,d1,d2,d3;
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
{q3,q2,q1,q0} <= 4'd0;
else
{q3,q2,q1,q0} <= {d3,d2,d1,d0};
end
assign d0=1'd1^q0;
assign d1=q1^q0;
assign d2=(q1&q0)^q2;
assign d3=(q2&q1&q0)^q3;
//q0输出为2分频,q1输出为4分频,q2输出为8分频,q3输出为16分频,且占空比都是50%
//{q3,q2,q1,q0}为模16计数器
endmodule任意分频,实现任意占空比
module div(clk,rst_n,clk_o);
input clk,rst_n;
output reg clk_o;
parameter M,N;
reg [3:0] count;
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
begin
clk_o <= 1;
count <= 0;
end
else if(count == M)//占空比为M+1/N
begin
count <= count + 1'd1;
clk_o <= ~clk_o;
end
else if(count == N-1)
begin
count <= 4'd0;
clk_o <= ~clk_o;
end
else
count <= count + 1'd1;
end
endmodule
下面是异步4位计数器,不推荐使用:

这种设计每个触发器都有一定的延时,会出问题的!!慎用
什么是Clock Jitter和Clock Skew,这两者有什么区别?
时钟抖动(Clock Jitter):指芯片的某一个给定点上时钟周期发生暂时性变化,使得时钟周期在不同的周期上可能加长或缩短。
时钟偏移(Clock Skew):是由于布线长度及负载不同引起的,导致同一个时钟信号到达相邻两个时序单元的时间不一致。
区别:Jitter是在时钟发生器内部产生的,和晶振或者PLL内部电路有关,布线对其没有影响。Skew是由不同布线长度导致的不同路径的时钟上升沿到来的延时不同;
什么是冒险和竞争,如何消除?
下面这个电路,使用了两个逻辑门,一个非门和一个与门,本来在理想情况下F的输出应该是一直稳定的0输出,但是实际上每个门电路从输入到输出是一定会有时间延迟的,这个时间通常叫做电路的开关延迟。而且制作工艺、门的种类甚至制造时微小的工艺偏差,都会引起这个开关延迟时间的变化


实际上如果算上逻辑门的延迟的话,那么F最后就会产生毛刺。信号由于经由不同路径传输达到某一汇合点的时间有先有后的现象,就称之为竞争,由于竞争现象所引起的电路输出发生瞬间错误的现象,就称之为冒险,FPGA设计中最简单的避免方法是尽量使用时序逻辑同步输入输出;
-
加滤波电容,消除毛刺的影响
-
加选通信号,避开毛刺
-
增加冗余项,消除逻辑冒险
用verilog实现两路数据的乘法运算,要求只使用1个乘法器;
input clk ;
input rst_n ;
input sel_x ;
input [ 7:0] da_x ;
input [ 7:0] da_y ;
input [ 7:0] db_x ;
input [ 7:0] db_y ;
output reg [15:0] dout_x_y ; module test(
input clk,
input rst_n,
input sel_x,
input [ 7:0] da_x,
input [ 7:0] da_y,
input [ 7:0] db_x,
input [ 7:0] db_y,
output reg [15:0] dout_x_y
);
wire [ 7:0] da;
wire [ 7:0] db;
wire [15:0] dout;
assign da = sel_x ? da_x : da_y;
assign db = sel_x ? db_y : db_x;
assign dout = da * db ;
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
dout_x_y <= 16'd0;
end else begin
dout_x_y <= dout;
end
end
endmodule用verilog实现串并转换
1) lsb优先 2) msb优先
input clk;
rst_n, data_i;
output [7:0] data_o;module test(
input clk, rst_n, data_i,
output [7:0] data_o
);
reg [7:0] data_r;
reg [2:0] cnt;
//lsb
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
data_r <= 8'd0;
cnt <= 3'b0;
end else begin
data_r <= {data_r[6:0],data_i};
cnt <= cnt + 1'b1;
end
end
//msb
/* always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
data_r <= 8'd0;
cnt <= 3'b0;
end else begin
data_r <= {data_i,data_r[7:1]};
cnt <= cnt + 1'b1;
end
end */
assign data_o = (cnt == 3'd7) ? data_r : data_o;
endmodule用verilog实现乘法y = a * b ,a和b都是8bit,考虑三种情况:
1) 都是无符号数
2) 都是有符号数
3) a是有符号数,b是无符号数
1)module test19(
input [ 7:0] i_a ,
input [ 7:0] i_b ,
output [15:0] o_y
);
assign o_y = i_a * i_b;
endmodule2)module test19(
input signed [ 7:0] i_a ,
input signed [ 7:0] i_b ,
output signed [14:0] o_y
);
assign o_y = i_a * i_b;//7+7+1
endmodule3)module test19(
input signed [ 7:0] i_a ,//加上signed后,将数看做二进制补码
input [ 7:0] i_b ,//无符号数,也就是正数
output signed [15:0] o_y
);
wire signed [8:0] b_r;
assign b_r = {1'b0,i_b};//加0不会出错,因为正数的补码与原码相同
assign o_y = i_a * b_r;//7+8+1
endmodule用Verilog实现 z = abs(x - y)
1) x和y是8bit无符号数
2) x和y是8bit有符号数(2补码)
1)module abs(
input [7:0] i_x,
input [7:0] i_y,
output [7:0] o_z
);
assign o_z= (i_x > i_y) ? (i_x - i_y) : (i_y - i_x);
endmodule2)考虑溢出问题,结果应该为9bit:
module abs(
input signed [7:0] i_x,
input signed [7:0] i_y,
output [8:0] o_z
);
wire signed [8:0] z_r;
assign z_r = (i_x > i_y) ? (i_x - i_y) : (i_y - i_x);
assign o_z = z_r;
endmodule用Verilog实现 y(n) = 0.75x(n) + 0.25y(n-1),x和y是8bit无符号数
module Cal_Formula(
input clk,
input rst_n,
input [7:0] din,
output reg [7:0] dout
);
// y(n) = 0.75x(n) + 0.25y(n-1)
//0.75*4 = 3,0.25*4 = 1
reg [7:0] dout_r1=0;
reg [9:0] dout_r2;
always @(posedge clk or negedge rst_n)begin
if(!rst_n)
dout_r1 <= 0;
else
dout_r1 <= dout;//将输出作为下一个输入
end
always @(posedge clk or negedge rst_n)begin
if(rst_n == 1'b0)begin
dout_r2 <= 0;
end
else begin
dout_r2 <= 3 * din + dout_r1;
end
end
assign dout = dout_r2 >> 2; //除4
endmodule画出SRAM bit cell结构图
SRAM存储的原理就是基于双稳态电路,将两个反相器的输入与输出分别交叉连接,然后再利用两个MOS管作为字线进行选通,总共需要6个MOS管



D锁存器和D触发器的原理图


状态机练习,序列检测

//检测1101
module detect1101(clk,rst_n,din,mealy_out,moore_out);
input clk,rst_n;
input din;
output reg mealy_out,moore_out;
parameter s0=3'b000,s1=3'b001,s2=3'b010,s3=3'b011,s4=3'b100;
//时序逻辑描述状态转移
reg [2:0] cs,ns;
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
begin
cs <= s0;
end
else
begin
cs <= ns;
end
end
//组合逻辑描述下一个状态
always @(*)
begin
if(~rst_n)
begin
ns = s0;
end
else
begin
ns = s0;//默认状态
case(cs)
s0: ns = (din == 1'b1)? s1:s0;
s1: ns = (din == 1'b1)? s2:s0;
s2: ns = (din == 1'b1)? s2:s3;
s3: ns = (din == 1'b1)? s4:s0;
s4: ns = (din == 1'b1)? s1:s0;
endcase
end
end
//打一拍作为输出
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
begin
moore_out <= 1'd0;
mealy_out <= 1'd0;
end
else
begin
moore_out <= (cs == s4)? 1'd1:1'd0;//moore机的输出只与当前状态有关
mealy_out <= (cs == s3 && din == 1'd1)?1'd1:1'd0;//mealy机的输出与当前状态和输入有关
//moore机总是比mealy机慢一拍输出
end
end
endmodule在clk a时钟域的一个单周期脉冲信号,如何正确的传递到clk b时钟域? 要考虑clk a和b的各种不同频率/相位的场景
//慢时钟域到快时钟域,两级寄存器同步,也就是打两拍
reg signal_in;
reg [1:0] signal_r;
always @(posedge clk_a or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_in <= 0;
end
else begin
signal_in <= datain;
end
end
//-------------------------------------------------------
always @(posedge clk_b or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_r <= 2'b00;
end
else begin
signal_r <= {signal_r[0], signal_in};
end
end
assign signal_out = signal_r[1];//快时钟域到慢时钟域
//Synchronous
module Sync_Pulse(
input clka,
input clkb,
input rst_n,
input pulse_ina,
output pulse_outb,
output signal_outb
);
//-------------------------------------------------------
reg signal_a;
reg signal_b;
reg [1:0] signal_b_r;
reg [1:0] signal_a_r;
//-------------------------------------------------------
//在clka下,生成展宽信号signal_a
always @(posedge clka or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_a <= 1'b0;
end
else if(pulse_ina == 1'b1)begin
signal_a <= 1'b1;
end
else if(signal_a_r[1] == 1'b1)
signal_a <= 1'b0;
else
signal_a <= signal_a;//将信号pulse_ina展宽
end
//-------------------------------------------------------
//在clkb下同步signal_a
always @(posedge clkb or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_b <= 1'b0;
end
else begin
signal_b <= signal_a;//0 0 0 ... 1 1 1
end
end
//-------------------------------------------------------
//在clkb下生成脉冲信号和输出信号
always @(posedge clkb or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_b_r <= 2'b00;
end
else begin
signal_b_r <= {signal_b_r[0], signal_b};
end
end
assign pulse_outb = ~signal_b_r[1] & signal_b_r[0];
assign signal_outb = signal_b_r[1];//0 0 0 1......
//-------------------------------------------------------
//在clka下采集signal_b[1],生成signal_a_r[1]用于反馈拉低signal_a
always @(posedge clka or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_a_r <= 2'b00;
end
else begin
signal_a_r <= {signal_a_r[0], signal_b_r[1]};//反馈,防止脉冲继续展宽
end
end
endmodule要将一个信号从快时钟域传递到慢时钟域,首先要在快时钟域展宽脉冲,然后将展宽的脉冲传递到慢时钟域,如果在慢时钟域检测到脉冲后就可以给快时钟域一个反馈以阻止脉冲的继续展宽;
用verilog实现1bit信号边沿检测功能,输出一个周期宽度的脉冲信号
要实现边缘检测,采样时钟的频率必须在信号频率的两倍以上,否则就很可能出现漏采样,代码如下:
module edge_detect(clk,rst,signal,pos_edge,neg_edge,both_edge);
input clk;
input rst;
input signal;
output pos_edge;
output neg_edge;
output both_edge;
reg sig_r0,sig_r1;//状态寄存器
always @(posedge clk)
begin
if(rst)
begin
sig_r0 <= 1'b0;
sig_r1 <= 1'b0;
end
else
begin
sig_r0 <= signal;
sig_r1 <= sig_r0;
end
end
assign pos_edge = ~sig_r1 & sig_r0;//上升沿
assign neg_edge = sig_r1 & ~sig_r0;//下降沿
assign both_edge = sig_r0 ^ sig_r1;//双边沿检测
endmodule用Verilog实现取整函数(ceil、floor、round)。以5bit为例,小数部分1位,取整后保留4bit
wire [4:0] data;
wire [3:0] data_ceil;
wire [3:0] data_floor;
wire [3:0] data_round;
基础知识:
floor(x),表示不超过x的整数中最大的一个,朝负无穷方向取整;
ceil(x),表示不小于x的整数中最小的一个,朝正无穷方向取整;
round(x)四舍五入到最近的整数
思路:data为有符号数(2补码),只有1bit的小数位,精度有限,所以假设data都是小数,例如整数部分是7,则data只能表示大于7.5或小于7.5的小数,不表示整数7;
floor——非负取整即可,负数取整减一;
ceil——正数,取整+1,非正数取整即可;
round——小数位为1,取整+1;小数位为0,取整即可 ;
module quzheng(
input [4:0] data ,
output [3:0] data_ceil ,
output [3:0] data_floor,
output [3:0] data_round
);
assign data_ceil = (data[4] == 1'b0) ? {1'b0,data[3:1]+1'b1} : data[4:1];//先判断符号位,向正无穷取整
assign data_floor = (data[4] == 1'b0) ? data[4:1] : data[4:1]-1'b1;//先判断符号位,向负无穷取整
assign data_round = (data[0] == 1'b0) ? data[4:1] : data[4:1]+1'b1;
endmodule异步fifo的设计
异步fifo主要分为:双端口RAM、空满标志位判断逻辑、跨时钟域指针传输模块
(1)双端口RAM用于接收空满判断逻辑模块传送过来的读写地址进行读写操作;
(2)空满标志位判断逻辑用于判断full、empty,同时输出读写地址指针以及对应的格雷码;
(3)跨时钟域传输主要是对地址指针进行打两拍操作,将读地址指针传输到写时钟域用于判断full,将写地址指针传输到读时钟域用于判断empty;
module sync_r2w //将读地址传输到写时钟域
#(parameter ADDRSIZE = 4)
(
output reg [ADDRSIZE:0] wq2_rptr,
input [ADDRSIZE:0] rptr,//输入的读地址为格雷码
input wclk, wrst_n
);
reg [ADDRSIZE:0] wq1_rptr;
always @(posedge wclk or negedge wrst_n)
if (!wrst_n)
{wq2_rptr,wq1_rptr} <= 0;
else
{wq2_rptr,wq1_rptr} <= {wq1_rptr,rptr};
endmodulemodule rptr_empty //在读时钟域判断是否empty
#(parameter ADDRSIZE = 4)
(
output reg rempty,
output [ADDRSIZE-1:0] raddr,
output reg [ADDRSIZE :0] rptr,
input [ADDRSIZE :0] rq2_wptr,//输入的写地址为格雷码
input rinc, rclk, rrst_n);//rinc为读使能
reg [ADDRSIZE:0] rbin;
wire [ADDRSIZE:0] rgraynext, rbinnext;
wire rempty_val;
//-------------------
// GRAYSTYLE2 pointer: gray码读地址指针
//-------------------
always @(posedge rclk or negedge rrst_n)
if (!rrst_n)
begin
rbin <= 0;
rptr <= 0;
end
else
begin
rbin <= rbinnext ;
rptr <= rgraynext;//下一个读地址的格雷码
end
// gray码计数逻辑
assign rbinnext = !rempty ? (rbin + rinc) : rbin;//若不为空,则读地址加1作为下一个读地址
assign rgraynext = (rbinnext>>1) ^ rbinnext; //二进制到gray码的转换,将右移一位的结果与原来的数异或
assign raddr = rbin[ADDRSIZE-1:0];//下一个读地址作为输出
//---------------------------------------------------------------
// FIFO empty when the next rptr == synchronized wptr or on reset
//---------------------------------------------------------------
/*
* 读指针是一个n位的gray码计数器,比FIFO寻址所需的位宽大一位
* 当读指针和同步过来的写指针完全相等时(包括MSB),说明二者折回次数一致,FIFO为空
*
*/
assign rempty_val = (rgraynext == rq2_wptr);//比较读写指针的格雷码
always @(posedge rclk or negedge rrst_n)
if (!rrst_n)
rempty <= 1'b1;//若复位,则空信号置1
else
rempty <= rempty_val;
endmodule这里要注意,对于读写指针的位宽通过会比fifo深度所需位宽多出一位,用于判断是否满;如果两个地址指针完全相同,包括最高位也相同,那么empty;如果两个指针除了最高位都相同,则full;

同步fifo的设计
module fifo(clk,rst,w_en,r_en,data_in,data_out,empty,full);
input clk,rst;
input w_en,r_en;
input [7:0] datain;
output reg [7:0] data_out;
output empty,full;
reg [7:0] ram [15:0];//双端口RAM
reg [3:0] w_pt,r_pt;
reg [3:0] count;
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
begin
w_pt <= 'd0;
r_pt <= 'd0;
count <= 'd0;
count <= 'd0;
end
else
begin
case({w_en,r_en})
2'b00: count <= count;
2'b01:begin//读
data_out <= ram[r_pt];
count <= count - 1'd1;
r_pt=(r_pt== 4'd15)?0:r_pt+1'd1;
end
2'b10:begin//写
ram[r_pt] <= data_in;
count <= count + 1'd1;
w_pt=(w_pt== 4'd15)?0:w_pt+1'd1;
end
2'b11:begin//写读
ram[r_pt] <= data_in;
//count <= count + 1'd1;
w_pt=(w_pt== 4'd15)?0:w_pt+1'd1;
data_out <= ram[r_pt];
//count <= count - 1'd1;
r_pt=(r_pt== 4'd15)?0:r_pt+1'd1;
end
endcase
end
end
assign full=(count == 4'd15)? 1:0;
assign empty=(count == 4'd0)? 1:0;
endmodule用16bit加法器IP核实现8bit乘法运算
乘法器最通用的实现方式就是使用移位相加来实现,如下:
module mul8bits(
input clk,
input rst_n,
input [7:0] a,
input [7:0] b,
output reg [15:0] result
);
reg [15:0] areg;
reg [15:0] temp;
reg [3:0] cnt;
always@(posedge clk or negedge rst_n)begin
if(~rst_n) begin
areg <= {8{1'b0}, a};
temp <= 16'd0;//用来保存移位相加的结果
cnt <= 4'd0;
result <= 16'd0;
end
else if(cnt <= 7)
begin
if(b[cnt]) begin//判断b的8个bit是否为1,如果为1则加上相应的移位结果
temp <= temp + areg;
else //如果为0则加0
temp <= temp;
end
cnt <= cnt + 1;
areg <= areg <<1;
end
else begin
cnt <= cnt;
areg <= {8{1'b0},a};
result <= temp;
end
end
endmodule将上面移位相加的操作采用16bit的加法器来实现,如下:
module mul8bits(
input clk,
input rst_n,
input [7:0] a,
input [7:0] b,
output reg [15:0] result
);
reg [15:0] areg;
reg [15:0] temp;
reg [3:0] cnt;
always@(posedge clk or negedge rst_n)begin
if(~rst_n) begin
areg <= {8{1'b0}, a};
temp <= 16'd0;
cnt <= 4'd0;
result <= 16'd0;
end
else if(cnt <= 7) begin
cnt <= cnt + 1;
areg <= areg <<1;
if(b[cnt]) temp <= temp_w; //调用IP核
else temp <= temp;
end
else begin
cnt <= cnt;
areg <= {8{1'b0},a};
result <= temp;
end
end
wire [15:0] temp_w;
add16 inst_add16(
.in1(temp),
.in2(areg),
.sout(temp_w),
.cout(1'd0)
);
endmodule在Verilog中设计模块以满足以下要求:
(1)频率为100MHz的时钟
(2)对时钟敏感的4位宽信号,限制该信号在8到15的范围内随机化16次
`timescale 1ns/1ps
module random1();
reg clk;
reg [3:0] out_rand;
initial begin
clk = 0;
forever
#5 clk = ~clk;
end
integer i;
initial begin
for(i = 0;i < 16; i = i + 1) begin
@(posedge clk) begin
out_rand = 4'b1000+ {$random}%8;
end
end
end
endmodule反相器的速度与哪些因素有关?什么是转换时间(Transition Time)和传播延迟(Propagation Delay)?
反相器的速度与哪些因素有关: 1. 电容(负载电容、自载电容、连线电容)较小,漏端扩散区的面积应尽可能小。输入电容要考虑: (1)Cgs 随栅压而变化(2)密勒效应(3)自举效应 2. 加大晶体管的尺寸(驱动能力),使晶体管的等效导通电阻(输出电阻)较小。但这同时加大自载电容和负载电容(下一级晶体管的输入电容)。 3. 提高电源电压,提高电源电压可以降低延时,即用功耗换取性能但超过一定程度后改善有限。电压过高会引起可靠性问题(氧化层击穿、热电子等)。
Transition Time(转换时间):上升时间:从10%Vdd上升到90%Vdd的时间,下降时间L从90%Vdd下降到10%dd的时间。上升时间和下降时间统称为Transition Time,也有定义为20%到80%。 Propagation Delay(传播延时):在输入信号变化到50%Vdd到输出信号变化到50%Vdd之间的时间


相同面积的cmos与非门和或非门哪个更快?
电子迁移率是空穴的2.5倍(在硅基CMOS工艺中),运算就是用这些大大小小的MOS管驱动后一级的负载电容,翻转速度和负载大小一级前级驱动能力相关。为了上升延迟和下降延迟相同,PMOS需要做成NMOS两倍多大小;
载流子的迁移率,对PMOS而言,载流子是空穴;对NMOS而言,载流子是电子;
PMOS采用空穴导电,NMOS采用电子导电,由于PMOS的载流子的迁移率比NMOS的迁移率小,所以,同样尺寸条件下,PMOS的充电时间要大于NMOS的充电时间长,在互补CMOS电路中,与非门是PMOS管并联,NMOS管串联,而或非门正好相反,所以,同样尺寸条件下,与非门的速度快,所以,在互补CMOS电路中,优先选择与非门;
FPGA与ASIC设计流程的区别
首先我们要清楚FPGA的基本单元是LUT,而ASIC的基本单元是寄存器;
对于FPGA:首先要进行模块划分,然后编写RTL代码,进行RTL仿真,综合后将生成的网表文件在FPGA上实现,也就是布局布线,该步骤完成后进行STA,没有问题的话就生成bit流文件,将bit流文件烧录到FPGA开发板上进行板级调试;
对于ASIC:模块划分、RTL设计、验证、综合、STA、形式验证、布局规划、DRC设计规则检查、时钟树综合、生成GDSII文件;
C语言实现冒泡排序
#include <stdio.h>//头文件
int main(void)
{
int a[] = {900, 2, 3, -58, 34, 76, 32, 43, 56, -70, 35, -234, 532, 543, 2500};
int n; //存放数组a中元素的个数
int i; //比较的轮数
int j; //每轮比较的次数
int buf; //交换数据时用于存放中间数据
n = sizeof(a) / sizeof(a[0]); /*a[0]是int型, 占4字节, 所以总的字节数除以4等于元素的个数*/
for(i=0;i<n-1;i++)//比较n-1轮
{
for(j=0;j<n-i-1;j++)
{
if(a[j]>a[j+1])
{
buf=a[j];
a[j]=a[j+1];
a[j+1]=buf;
}
}
}
for(i=0;i<n;i++)
{
printf("%d\n",a[i]);
}
return 0;//注意加上
}已知一个数据的数值范围为1~43,运算并输出其除3的余数;
input [5:0] a;//被除数
input [5:0] b;//除数
output reg [5:0] y_shang;
output reg [5:0] y_yu;//商和余数
reg [11:0] tempa;
reg [11:0] tempb;
integer i;
always @(*)
begin
tempa={6'd0,a};
tempb={b,6'd0};
for(i=0;i<6;i++)
begin
tempa=tempa << 1;//每次左移1位
tempa=(tempa[11:6]>=tempb[11:6])?(tempa - tempb + 1'b1):tempa;
end
y_yu=tempa[11:6];
y_shang=tempa[5:0];
end
//改用时序逻辑,分为13个周期
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
begin
y_shang <= 'd0;
y_yu <= 'd0;
end
else if(enable)
begin
y_yu <=tempa[11:6];
y_shang <=tempa[5:0];
end
else
begin
y_shang <= 'd0;
y_yu <= 'd0;
end
end
reg [3:0] count;
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
count <= 'd0;
else if(count == 4'd12)
count <= 'd0;
else
count <= count + 1'd1;
end
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
begin
tempa <= 'd0;
tempb <= 'd0;
end
else if(count == 'd0)
begin
tempa <= {6'd0,a};
tempb <= {b,6'd0}
end
else if(count[0] == 1'b1)
tempa <= tempa << 1;
else
tempa <= (tempa[11:6] >= tempb[11:6])? (tempa - tempb + 1'b1):tempa;
end
reg enable;
always @(posedge clk or negedge rst_n)
begin
if(~rst_n)
enable <= 1'd0;
//else if(count == 0)
// enable <= 1'd0;
else if(count == 4'd12)
enable <= 1'd1;
else
enable <= 1'd0;
end以前看到二进制序列检测一般都使用状态机实现,今天突然想到可以使用移位寄存器实现,移位寄存器就好像一个窗口,把从窗口里截取的数据接到一个比较器上,这样比较不同序列时只要换一下比较器另一个输入端的数据就可以实现,需要改变的只是寄存器和比较器的位宽;
module seq_det(iBit,CLK,RSTn,iKEY,Q);
input iBit;
input[4:0] iKEY;
input CLK;
input RSTn;
output Q;
reg[4:0] shift_reg;
always@(posedge CLK or negedge RSTn)
begin
if(RSTn==0)
shift_reg <= 0;
else
shift_reg <= {shift_reg[3:0],iBit};
end
assign Q =(shift_reg==iKEY)?1:0;
endmodule定义一个随机数,并约束其范围为4~100,并建仓
rand bit [6:0] a;
constraint value_a{a>4;
a<100;}
covergroup ag @(posedge clk)
coverpoint : a {bins a1[]={[4:100]};}
endgroup

将两个乘法器减少为1个,同时数据选择器多用了1个;






fir滤波器的设计
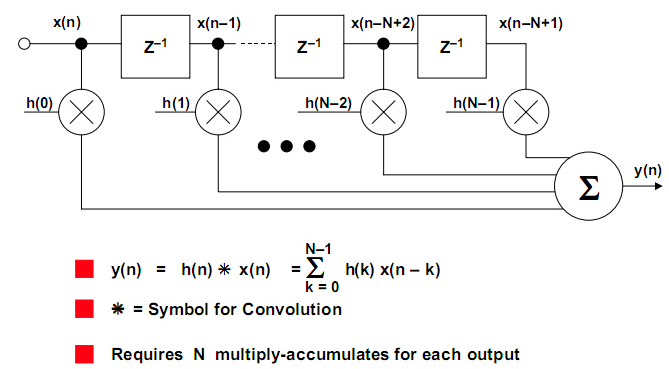
module fir(clk,rst,din,dout,ordy);
input clk;
input rst;
input [7:0] din;
output [15:0] dout;
output ordy;
//matlab fir生成系数 * 256 该滤波器采样率为100Hz,截止频率为10Hz
parameter coeff1=8'd5,coeff2=8'd17,coeff3=8'd43,coeff4=8'd63,coeff5=8'd63,coeff6=8'd43,coeff7=8'd17,coeff8=8'd5;
//8个寄存器
reg signed [7:0] sample_1;
reg signed [7:0] sample_2;
reg signed [7:0] sample_3;
reg signed [7:0] sample_4;
reg signed [7:0] sample_5;
reg signed [7:0] sample_6;
reg signed [7:0] sample_7;
reg signed [7:0] sample_8;
reg [18:0] dout;
reg ordy;
//输入数据,移位寄存
always @(posedge clk )
begin
if(rst)
begin
sample_1 <= 8'd0;
sample_2 <= 8'd0;
sample_3 <= 8'd0;
sample_4 <= 8'd0;
sample_5 <= 8'd0;
sample_6 <= 8'd0;
sample_7 <= 8'd0;
sample_8 <= 8'd0;
end
else
begin
sample_1 <= din;
sample_2 <= sample_1;
sample_3 <= sample_2;
sample_4 <= sample_3;
sample_5 <= sample_4;
sample_6 <= sample_5;
sample_7 <= sample_6;
sample_8 <= sample_7;//8个周期完成移位,完成滞后
end
end
//调用ip,执行乘法
wire [15:0] p[8:1];
mult_8 u1 (
.CLK(clk), // input wire CLK
.A(sample_1), // input wire [7 : 0] A
.B(coeff1), // input wire [7 : 0] B
.P(p[1]) // output wire [15 : 0] P 设置pipline stage 为3,表示3级延时
);
mult_8 u2 (
.CLK(clk), // input wire CLK
.A(sample_2), // input wire [7 : 0] A
.B(coeff2), // input wire [7 : 0] B
.P(p[2]) // output wire [15 : 0] P
);
mult_8 u3 (
.CLK(clk), // input wire CLK
.A(sample_3), // input wire [7 : 0] A
.B(coeff3), // input wire [7 : 0] B
.P(p[3]) // output wire [15 : 0] P
);
mult_8 u4 (
.CLK(clk), // input wire CLK
.A(sample_4), // input wire [7 : 0] A
.B(coeff1), // input wire [7 : 0] B
.P(p[4]) // output wire [15 : 0] P
);
mult_8 u5 (
.CLK(clk), // input wire CLK
.A(sample_5), // input wire [7 : 0] A
.B(coeff5), // input wire [7 : 0] B
.P(p[5]) // output wire [15 : 0] P
);
mult_8 u6 (
.CLK(clk), // input wire CLK
.A(sample_6), // input wire [7 : 0] A
.B(coeff6), // input wire [7 : 0] B
.P(p[6]) // output wire [15 : 0] P
);
mult_8 u7 (
.CLK(clk), // input wire CLK
.A(sample_7), // input wire [7 : 0] A
.B(coeff7), // input wire [7 : 0] B
.P(p[7]) // output wire [15 : 0] P
);
mult_8 u8 (
.CLK(clk), // input wire CLK
.A(sample_8), // input wire [7 : 0] A
.B(coeff8), // input wire [7 : 0] B
.P(p[8]) // output wire [15 : 0] P
);
//加法第一级
wire [16:0] s1 [4:1];//加法器的延时为2
add_16 a1 (
.A(p[1]), // input wire [15 : 0] A
.B(p[2]), // input wire [15 : 0] B
.CLK(clk), // input wire CLK
.S(s1[1]) // output wire [16 : 0] S
);
add_16 a2 (
.A(p[3]), // input wire [15 : 0] A
.B(p[4]), // input wire [15 : 0] B
.CLK(clk), // input wire CLK
.S(s1[2]) // output wire [16 : 0] S
);
add_16 a3 (
.A(p[5]), // input wire [15 : 0] A
.B(p[6]), // input wire [15 : 0] B
.CLK(clk), // input wire CLK
.S(s1[3]) // output wire [16 : 0] S
);
add_16 a4 (
.A(p[7]), // input wire [15 : 0] A
.B(p[8]), // input wire [15 : 0] B
.CLK(clk), // input wire CLK
.S(s1[4]) // output wire [16 : 0] S
);
//加法第二级
wire [17:0] s2 [2:1];
add_17 a21 (
.A(s1[1]), // input wire [16 : 0] A
.B(s1[2]), // input wire [16 : 0] B
.CLK(clk), // input wire CLK
.S(s2[1]) // output wire [17 : 0] S
);
add_17 a22 (
.A(s1[3]), // input wire [16 : 0] A
.B(s1[4]), // input wire [16 : 0] B
.CLK(clk), // input wire CLK
.S(s2[2]) // output wire [17 : 0] S
);
//加法第三级
wire [18:0] s3;
add_18 a31 (
.A(s2[1]), // input wire [17 : 0] A
.B(s2[2]), // input wire [17 : 0] B
.CLK(clk), // input wire CLK
.S(s3) // output wire [18 : 0] S
);
//计数
reg [4:0] counter;
always @(posedge clk)
begin
if(rst)
begin
counter <= 5'd0;
dout <= 19'd0;
ordy <= 1'b0;
end
else if(counter == 17)
begin
dout <= s3;
ordy <= 1'b1;
end
else
begin
dout <= 19'd0;
counter <= counter + 1'b1;
end
end
endmodule
#include <stdio.h>
int main()
{
char *str=(char *)malloc(100);
strcpy(str,"hello");
printf("%s\n",str);
free(str);//释放了str所指向地址中的内容,并没有释放指针
printf("%d\n",&str);
printf("%s\n",str);
if(str != NULL)
{
strcpy(str,"world");
printf("%s\n",str);
}
}

在测试文件里,always是一个循环,就像我们写生成时钟一样,有种写法就是:
initial clk = 0;
always begin
#2 clk = ~clk;
end那这里的always同样也是循环语句的作用,内部是阻塞赋值,@(A)以及@(B)相当于触发条件,#2其实也属于这一类,过了2ns执行下面的语句,这里就是A变化了就触发,题目中说A在15ns以及25ns各触发一次,当A在15ns触发一次后,count = 2,然后等待@(B),可是B一直为X态,没有触发,所以就一直阻塞到这里了,再多的时间也没用。所以只能最后count = 2.
设计一个可预置初值的7进制循环计数器
module counter7(clk,rst,load,data,cout);
input clk,rst,load;
input [2:0] data;
output reg [2:0] cout;
always@(posedge clk)
begin
if(!rst)
cout<=3’d0;
else if(load)
cout<=data;
else if(cout>=3’d6)
cout<=3’d0;
else
cout<=cout+3’d1;//不同位宽的数相加会自动补齐
end
endmodule
用verilog实现冒泡排序
module sort(clk,rst,datain,dataout,over);
parameter length=8; // the bits number of data
parameter weikuan=256; // the length of the memory
input clk,rst;
input[length-1:0] datain;
output[length-1:0] dataout;
output over;
reg over;
reg [length-1:0] dataout;
reg [length-1:0] memo[weikuan-1:0];
integer i,j,m;
//**************数据交换任务模块************//
task exchange;
inout[length-1:0] x,y;
reg[length-1:0] temp;
begin
if(x<y)
begin
temp=x;
x=y;
y=temp;
end
end
endtask
//***********************************************
always@(negedge clk or posedge rst)
if(!rst)
begin
i=0;
j=0;
m=0;
over=0;
end
else
if(m==weikuan-1) //the memory is full
begin
m=weikuan-1;
if(i==weikuan) //arrangement is over, set over to be "1"
begin
i=weikuan;
over=1;
end
if(i<weikuan)
for(i=0;i<weikuan;i=i+1) //then put the datas in order
begin
for(j=0;j<weikuan-1-i;j=j+1) //note the range of 'j'
exchange(memo[j+1],memo[j]); //if 'memo[j+1]<memo[j]', exchange them.
end
end
else //input the data first
begin
memo[m]=datain;
m=m+1;
end
endmodule
奉上代码:
module clk_mul(
input wire clk
, input wire rst_n
, output wire clk_out
);
//
// variable declaration
reg temp_mul ;
//
// logic
always @(posedge clk_out or negedge rst_n) begin
if(~rst_n) temp_mul <= 1'b0 ;
else temp_mul <= #2 ~temp_mul ;
end
assign clk_out = ~(clk ^ ~temp_mul) ;
endmodule // CREATED by poiu_elab@1207
这个东西很简单的,但是要注意,它的核心是第16行的#2,这里的延时(占空比)可以通过电路的Tco和经过反相器的时间来搞定(其中可以插入一些buffer来调节时间),testbench这么来写(很简单,但是便于下面解释延时对占空比的影响还是附上):
`define CLK_CYCLE 20
module tb();
///
// variable declaration
reg clk ;
reg rst_n ;
wire clk_out ;
///
// stimulation generation
initial forever #(`CLK_CYCLE/2) clk = ~clk;
initial begin
rst_n = 1'b0 ;
clk = 1'b1 ;
#500;
rst_n = 1'b1 ;
#5000;
$stop;
end
///
// module instaniation
clk_mul u_clk_mul(
.clk ( clk )
, .rst_n ( rst_n )
, .clk_out ( clk_out )
);
///
endmodule
下面给出仿真图,当#2的时候,是这样的,其中你要关心的其实是~temp_mul & clk, 当你要是q端经过反相器的信号与接入的clk信号相同的时候你的clk_out就会起来,之后你的q端翻转了的话,你的clk_out就会落下来,这时候在下一个clk翻转的时候,你的~temp_mul & clk就会又要把clk_out拉起来,q端又翻转,以此类推,就可以继续在每个clk的跳变沿出现你的clk_out的高电平,调整你的Tco和反相器延时就可以调整你的高电平时间,由于周期又是固定的,这样就可以调整你的占空比;

而当#5的时候,是这样的

看出什么端倪了没,当你的延时,正好是时钟周期的1/4的时候,你就可以得到一个占空比是50%的2倍频时钟;
要求:一个握手的模块。输入信号分别为en,ack,all_done;输出信号是req,done;要求例如以下en高电平有效时能够输出req信号。然后等待ack信号,收到ack信号后会发出done信号,模块的数量不定。当全部模块done信号军发送完成后会接收到all_done信号,仅仅有接收到aLL_done信号才干够发送下一次req信号
module handshake(input clk, rst_n,en,all_done,ack,
output reg req, done);
reg flag,r_all;
always @(posedge clk or negedge rest_n)
if(!rst_n)begin
flag<=1'b1;//推断是否为第一次发送,flag为标志位
r_all<=1'b0; //是否接收到all_done信号
end
else if(all_done) begin
r_all<=1'b1;//已接收到all_done信号置位
end
else if(done) begin
r_all<=1'b0;//以完毕发送,all_done信号清零
flag<=1'b0;//完毕第一次发送后即永久性清零。
end
always @(posedge clk or negedge rest_n)
if(!rst_n)begin
req<=1'b0;
done<=1'b0;
end
else begin
if((en&flag) || (en&all_done) || (en &r_all))
req<=1'b1;
else req<=1'b0;
if(ack)
done<=1'b1;
else done<=1'b0;
end
endmodule一个1bit的信号,脉冲宽度为一个源时钟周期,需要传送到到频率低得多的目的时钟域,比方说源时钟频率是目的时钟频率的三倍,不能采用握手,不能在信源对信号展宽,怎样在目的时钟域识别到这个信号的脉冲?fifo等存储器手段也不能用,而且没有随行的同步时钟信号
边沿检测同步器适用情况为:异步输入信号的脉冲宽度小于时钟周期时的同步电路(高速时钟域→低速时钟域)




上图中包括3条路径,对于路径1/2/3的数据路径分别为:



寄存器前门访问和后门访问的区别
前门访问通过总线来访问寄存器需要消耗仿真时间;而后门访问通过UVM DPI关联硬件寄存器路径,直接读取或修改硬件,不需要消耗仿真时间;
前门访问一般只能按字(word)进行读写,无法直接访问寄存器域;后门可以对寄存器或寄存器域进行读写;
实现1+2+3+4+.......
module Sum_n(input clk,rst_n,
input en,//单脉冲有效信号;
input [10:0]data_in,
output reg [29:0]sum_n,
output reg D_en//高电平表示和有效;
);
reg [10:0]data_buf;//data_1,
reg [1:0]state;
parameter Wait_signal = 2'b00,
judge_data = 2'b01,
data_sub = 2'b11,
clr_en = 2'b10;
always@( posedge clk )
begin
if( !rst_n )
begin
sum_n <= 0;
D_en <= 0;
state <= Wait_signal;
end
else
begin
case ( state )
Wait_signal : begin//默认态
if( en )
begin
data_buf <= data_in;
state <= judge_data;
end
else
state <= Wait_signal;
end
judge_data : begin//判决相加态
if( data_buf >= 1'b1 )
begin
sum_n <= sum_n + data_buf;
state <= data_sub;
end
else
begin
//sum_n <= 0;
D_en <= 1;
state <= clr_en;
end
end
data_sub : begin//减1态
data_buf <= data_buf - 1'b1;
state <= judge_data;
end
clr_en : begin//清零态
D_en <= 0;
state <= Wait_signal;
end
endcase
end
end
endmodule异步跨时钟域处理
对于单bit数据,可以采用打两拍的方式,但是这种方式只能适用于从慢时钟到快时钟;对于从快到慢的跨时钟域处理,需要用到脉冲同步器,如下所示:

module edge_detect(
input sclk_1,//100M
input sclk_2,//50M
input p_in,
output p_out
);
reg p_in_reg=0;
reg dly1,dly2,dly3;
wire mux_2;
//组合逻辑产生毛刺,p_in没有和sclk_1 同步
assign mux_2 = (p_in==1'b1)? (~p_in_reg):p_in_reg;
always @(posedge sclk_1)
p_in_reg <= mux_2;
always @(posedge sclk_2)
{dly3,dly2,dly1} <= {dly2,dly1,p_in_reg};//流水移位赋值
assign p_out = dly3 ^ dly2;
endmodule对于多bit数据,一般采用异步fifo来实现,也可以使用握手协议,但是握手效率低,适用于低速的情况;
采用握手机制:发送域现将数据锁存在总线上,随后发送一个req信号给接受域;接受域在检测到req信号后,锁存总线数据,并送回一个有效的ack信号表示读取完成应答;检测到应答信号ack后,撤销req信号,接受域在检测到req撤销后也相应撤销ack信号,完成一次正常的握手信号;
module handshake(
input clk, //50MHZ时钟
input rst_n, //复位信号
input req, //数据发送请求信号
input [15:0]data_in, //数据输入
output reg ack, //应答信号
output [15:0]data_out
);
reg req1,req2,req3; //req输入同步信号
reg [15:0]data_in_r; //输入数据寄存器
wire pos_req1,pos_req2;
//---------通过三级寄存器同步异步输入信号req--------
always@(posedge clk or negedge rst_n)begin
if(!rst_n)begin
req1 <= 1'b0;
req2 <= 1'b0;
req3 <= 1'b0;
end
else begin
req1 <= req;
req2 <= req1;
req3 <= req2;
end
end
//--------------检测req1、req2的上升沿---------------
assign pos_req1 = req1 && ~req2;
assign pos_req2 = req2 && ~req3;
//----------在检测到pos_req1上升沿时,锁存数据-------
always@(posedge clk or negedge rst_n)begin
if(!rst_n)begin
data_in_r <= 16'd0;
end
else begin
if(pos_req1)begin//检测到上升沿,发送数据
data_in_r <= data_in;
end
end
end
assign data_out = data_in_r;
//----------在检测到pos_req2上升沿时,发出ack应答信号,表示数据已经锁存-------
//----------检测req信号,如果req信号取消,则ack也取消-----------------------
always@(posedge clk or negedge rst_n)begin
if(!rst_n)begin
ack <= 1'b0;
end
else begin
if(pos_req2)begin
ack <= 1'b1;
end
else if(!req)begin
ack <= 1'b0;
end
end
end
endmoduleparameter与define的区别
parameter声明和作用于模块内部,可以在调用模块时进行参数传递;
define是全局作用,从编译器读到这条指令开始到编译结束都有效,或者遇到`undef命令使之失效;
如何验证一个异步FIFO?
验证分为验证场景和验证平台。验证场景如表所示:
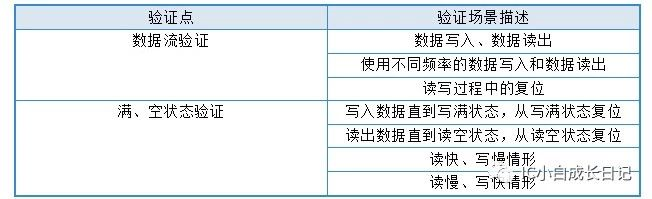

注:在验证复位场景时,完整的复位验证应当包含以下情形的复位:
初始复位:在验证激励施加之前对读、写指针的复位,可以在driver中完成。
写复位:在FIFO写入过程中对写时钟域信号复位;在FIFO读出过程中对写时钟域信号复位。
读复位:在FIFO读出过程中对读时钟域信号复位;在FIFO写入过程中对读时钟域信号复位。
随机复位:任意情形下的随机复位。
在完成验证平台和验证场景的设计后,还需添加断言用于检查部分时序,所构建的断言应当包括以下点:
(1)检查复位时所有指针和满/空信号是否都处于低电平状态。
(2)当fifo读计数为0时,检查fifo_empty是否被置位。
(3)当fifo写计数大于FIFO宽度时,检查fifo_full是否被置位。
(4)检查如果fifo已满,并且尝试写入时写入指针不会更改。
(5)检查如果fifo已空,并且尝试读出时读指针不会更改。
(6)有一个属性会在尝试fifo写满时发出警告。
(7)有一个属性会在尝试fifo读空时发出警告。
(8)确保在WRITE模式下,写输入指针处于已定义状态(0或1),它不应为X态.同样适用于READ模式。
什么是线与逻辑?
线与是指两个输出信号相连可以实现与的功能;在硬件上需要用OC门来实现,由于OC门可能使灌电流过大而烧坏逻辑门,需要在输出端口加上一个上拉电阻;
看下面代码复位为什么会失败?
reg rst_n;
reg f0_rst_n;
reg f1_rst_n;
wire rst_n_out;
always @(posedge clk)
begin
f0_rst_n <= rst_n;
f1_rst_n <= f0_rst_n;
end
rst_n_out = rst_n | f0_rst_n | f1_rst_n;f0_rst_n,f1_rst_n在被赋值以前都是x态,该代码的本意是将复位信号展宽,但是由于X态的存在会将或门的复位信号变为X态从而导致复位失败;



int fibo1(int n)
{
if (n == 1 || n==2)
{
return 1;
}
return fibo1(n-2)+fibo1(n - 1);
}















 1758
1758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









