







 文章探讨了在图神经网络学习中对抗性攻击的挑战,包括如何在离散图结构中寻找扰动,以及如何设计不被察觉的扰动以影响节点分类。研究还提出了针对单个节点的攻击方法,强调了结构和特征攻击的重要性,以及在实际场景中如何通过限制更改数量和保持固有属性来检测和生成对抗图。
文章探讨了在图神经网络学习中对抗性攻击的挑战,包括如何在离散图结构中寻找扰动,以及如何设计不被察觉的扰动以影响节点分类。研究还提出了针对单个节点的攻击方法,强调了结构和特征攻击的重要性,以及在实际场景中如何通过限制更改数量和保持固有属性来检测和生成对抗图。
Adversarial Attacks on Graph Neural Networks: Perturbations and their Patterns

1 Challenges
- 和由连续特征组成的图像不同,图结构(通常还有节点的特征)是离散的(discrete)。因此,基于梯度的方法不适合寻找扰动。如何设计能够在离散域中找到对抗样本的有效算法?
- 对抗性扰动的目的是不被(人类)注意到。对于图像,通常会强制执行,例如,每像素值的最大偏差。如何捕捉(二进制和属性)图中“不可察觉的变化”的概念?
- 节点分类通常在转导(
transductive)学习设置中执行。这里,在对特定测试数据执行预测之前,训练数据和测试数据被联合用于学习新的分类模型。这意味着主要执行的规避攻击evasion attack——其中分类模型的参数被假设为静态的——是不现实的。模型必须在操纵的数据上进行(重新)训练。因此,在转换环境中基于图的学习本质上与具有挑战性的中毒/因果攻击有关(具体来说,模型的训练阶段在攻击之后执行)。
2 Adversarial Attacks when Learning with Graphs
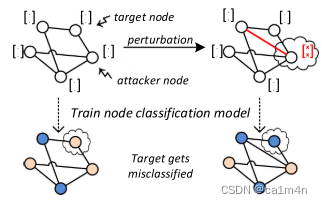
图结构和节点特征的小扰动会导致目标的错误分类☝️。(牵一发而动全身)
这项工作是针对单个节点的有针对性的攻击,目标是对图 G ( 0 ) = ( A ( 0 ) , X ( 0 ) ) G^{(0)}=(\textbf{A}^{(0)}, \textbf{X}^{(0)}) G(0)=(A(0),X(0))执行小扰动,从而得到 G ′ = ( A ′ , X ′ ) G^{'}=(\textbf{A}^{'}, \textbf{X}^{'}) G′=(A′,X′),使得分类性能下降。对 A ( 0 ) \textbf{A}^{(0)} A(0) 的改变称为结构攻击,而对 X ( 0 ) \textbf{X}^{(0)} X(0)的改变称为特征攻击。
因为non-i.i.d.数据的性质,节点的预测结果不仅取决于节点本身。所以,攻击也不限于扰动目标节点,可以通过改变其他节点来实现攻击目标。事实上,这更好地反映了真实的世界场景,因为攻击者可能只能访问几个节点,而不能访问整个数据或目标节点本身。
为了确保攻击者不能完全修改图,通过预算
Δ
\Delta
Δ来限制允许的更改数量:
∑
u
∑
i
∣
x
u
i
(
0
)
−
x
u
i
′
∣
+
∑
u
<
v
∣
a
u
v
(
0
)
−
a
u
v
′
∣
≤
Δ
\sum_{u}\sum_{i}\left|x_{ui}^{(0)}-x_{ui}^{\prime}\right|+\sum_{u<v}\left|a_{uv}^{(0)}-a_{uv}^{\prime}\right|\leq\Delta
u∑i∑
xui(0)−xui′
+u<v∑
auv(0)−auv′
≤Δ
问题定义:
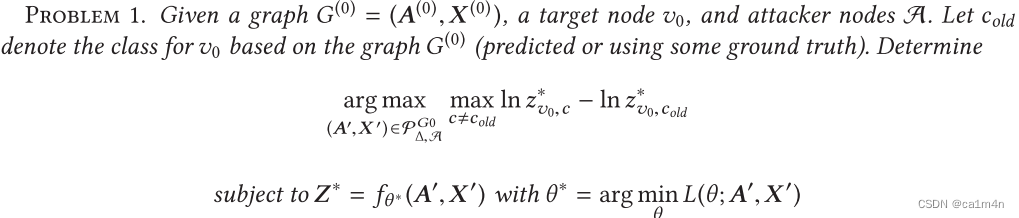
3 Unnoticeable Perturbations
在图上,通过修改输入数据但又不容易被发现是更加困难的,因为:
(1)图结构是离散的,无法使用无穷小的微小变化;
(2)足够大的图不适合视觉检查。
只考虑预算
Δ
\Delta
Δ是不够的,特别是如果由于复杂的数据而需要大的预算,我们仍然希望逼真地观察扰动图
G
′
G^{'}
G′.
本研究的核心思想只允许那些保留输入图特定固有属性的扰动.
3.1 保持图结构的扰动
图结构最显著特征是其度分布。如果两个网络显示出截然不同的度分布,就很容易将它们区分开来
因此,我们的目标是生成与输入相似的幂律(power-law )行为的扰动。
参考双样本检验统计,即使用似然比检验来估计
G
0
G^{0}
G0和
G
′
G^{'}
G′的两个度分布是来自同一个分布还是不同分布
首先估计幂律分布
p
(
x
)
∝
x
−
α
p(x) \propto x ^{-\alpha}
p(x)∝x−α的缩放参数
α
\alpha
α,该参数指的是𝐺(0)的度分布(等同于𝐺 ′的度分布)。虽然在离散数据的情况下,没有精确的闭式解来估计
α
\alpha
α,但有文献推导出了一个近似表达式,对于我们的图 𝐺 来说,它可以转化为:

3.2 保持扰动的特征统计
虽然上述原则也可应用于节点特征(例如,保留特征出现的分布),但我们认为这样的程序局限性太大。尤其是,这样的测试不能很好地反映不同特征的相关性/共同性: 如果两个特征在𝐺 (0) 中从未同时出现,但在𝐺 ′ 中出现了一次,那么特征出现的分布仍然会非常相似。然而,这种变化很容易察觉。例如,两个词从来没有在一起使用过,但突然在 𝐺 ′ 中使用了。因此,我们称之为基于特征共现的检验。
在这方面,将特征设置为 0 是非关键性的,因为它不会引入新的co-occurences。问题是:节点𝑢 的哪些特征可以设为 1 以被视为不可忽略?为了回答这个问题,我们考虑在𝐺 (0) 的特征共现图 𝐶 = (F, 𝐸)上使用random walker,即 F 是特征集,𝐸 ⊆ F × F 表示迄今为止哪些特征一起出现过。我们认为,如果random walker从节点 𝑢 最初出现的特征开始,走一步到达一个特征 𝑖 的概率非常大,那么增加一个特征就不会被注意到。
形式上,让 𝑆𝑢 = { 𝑗 | 𝑋𝑢𝑗 ≠ 0} 是节点 𝑢 最初存在的所有特征的集合。我们认为在节点 𝑢 上添加特征 𝑖 ∉ 𝑆 𝑢 是不可察觉的,如果
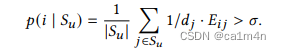 其中,𝑑𝑗 表示共现图 𝐶 中的度数。也就是说,如果概率walker从任意特征𝑗 ∈ 𝑆𝑢 开始,那么在走完一步后,它将至少以𝜎 的概率到达特征𝑖。在我们的实验中,我们只需将𝜎选为最大可能达到概率的一半。
其中,𝑑𝑗 表示共现图 𝐶 中的度数。也就是说,如果概率walker从任意特征𝑗 ∈ 𝑆𝑢 开始,那么在走完一步后,它将至少以𝜎 的概率到达特征𝑖。在我们的实验中,我们只需将𝜎选为最大可能达到概率的一半。

4 生成对抗图
我们提出了一种顺序方法,即首先攻击一个代理模型(surrogate model),从而得到一个攻击图(attacked graph)。
这个图随后被用来训练最终模型。事实上,这种方法可以直接视为transferability检查,因为我们并不特别关注所使用的模型,而只是关注代理模型。
对GCN进行线性化处理,使用一个简单的线性激活函数来替代非线性的𝜎(·),得到代理模型:
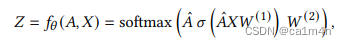
👇简化版GCN
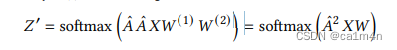
攻击代理模型,使得原本的分类概率尽可能的小
…
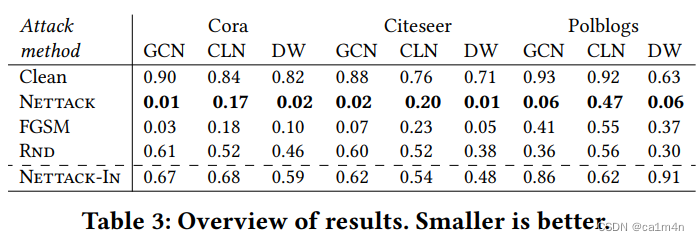
灰盒攻击,攻击者不能得到被攻击模型的结构和参数,只能得到训练的数据。灰盒攻击通常不是直接攻击给定的模型,而是首先利用训练数据训练一个代理模型,然后攻击这个代理模型。


















 6751
6751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











