







L1正则:
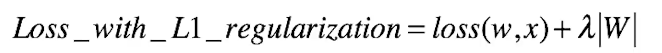
L2正则:
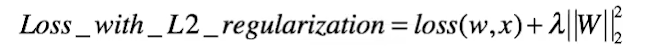
无论L1、L2正则化方法,本质上都是乘法参数W使其等于或者趋向于0;但有没有可能有一种正则化方法会使参数W趋向于非零值呢?
答案是:
可以这样做 将w约束到A附近。
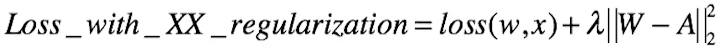
-
L1正则化法:对参数进行一次约束,会形成稀疏解
-
L2正则化的特性:参数W变小、但不为零,不会形成稀疏解
为什么会产生这样的结果呢?
可以从两种角度去解释:
解释1:
 直观感受(几何):
直观感受(几何):
黄色区域表示正则项限制,蓝色区域表示优化项的等高线,要满足在二者交点上的点才符合最优解w*。
故:当w的等高线逐步向正则限制条件区域扩散时,前者交点大多在非坐标轴上,后者在坐标轴上哪个形成稀疏解显而易见、
解释2:
理论角度:
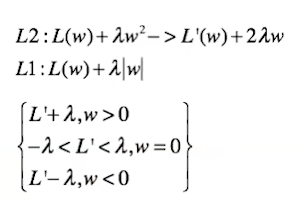
先看L2正则:为什么无法产生稀疏解,而只是将w各个参数压缩。
L(w)+λw² 其导数为:
L’(w)+2λw
当w=0时,导数值为L‘(0)。这和不带正则项的损失函数在w=0时的导数一致。
如果此时的导数值为0,则说明w=0点为极值点,说明模型得到最优解。
这也就说明不带正则项时的普通损失函数在w=0时模型也是最优解,正则项此时没有任何意义,则说明如果w=0时,如果模型取得最优解,则导数为零,取决于L’(0)本身,而非正则项,因为正则项当w=0时不产生任何作用。
而为什么L2正则可以压缩模型的w值呢?
回到最初的公式:
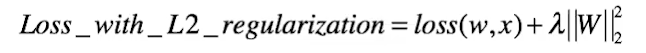 最小化损失函数,即最小化 loss(w,x)和λ||w||²
最小化损失函数,即最小化 loss(w,x)和λ||w||²
由于:
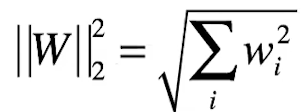
而其中最小化 λ||w||² 则是让w²的和最小,故可以使每个w都进行压缩。
再看L1正则:为什么就可以产生稀疏解呢?
L(w)+λ|w| 其导数由于|w|在0处不可导,则分情况讨论:
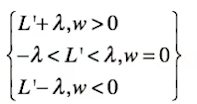
我们想找到最优解,则令导数等于0。
当w>0时,L’(w)=-λ
当w<0时,L‘(w)=λ
当w≠0时,只有当L’(w) = -λ 或者 λ 才可以使导数为0,概率极小;
而当w=0时,-λ< L’(w) < λ使得导数为零(利用次梯度方法),此时概率极大。
故L1范数可以产生稀疏解。
思考:为何沿着梯度方向就是最速下降,即函数的下降的速度最快?

泰勒展开:
以二阶导为例
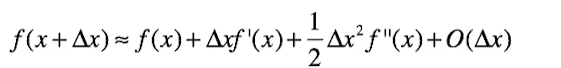

则f(x+V)-f(X)=df(x)V,则我们可以得出: df(x)V为函数值的变化量,注意的是df(x)和V均为向量,df(x)v也就是两个向量进行点积,而向量进行点积的最大值,也就是两者共线的时候,也就是说V的方向和df(x)方向相同的时候,点积值最大,这个点积值也代表了从A点到B点的上升量。
而df(x)正是代表函数值在x处的梯度。前面又说明了v的方向和df(x)方向相同的时候,点积值(变化值)最大,所以说明了梯度方向是函数局部上升最快的方向。也就证明了梯度的负方向是局部下降最快的方向。















 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









