







论文地址:https://www.aaai.org/AAAI21Papers/AAAI-1352.LiY.pdf
相关博客:
【自然语言处理】【聚类】基于神经网络的聚类算法DEC
【自然语言处理】【聚类】基于对比学习的聚类算法SCCL
【自然语言处理】【聚类】DCSC:利用基于对比学习的半监督聚类算法进行意图挖掘
【自然语言处理】【聚类】DeepAligned:使用深度对齐聚类发现新意图
【自然语言处理】【聚类】CDAC+:通过深度自适应聚类发现新意图
【计算机视觉】【聚类】DeepCluster:用于视觉特征无监督学习的深度聚类算法
【计算机视觉】【聚类】SwAV:基于对比簇分配的无监督视觉特征学习
【计算机视觉】【聚类】CC:对比聚类
【计算机视觉】【聚类】SeLa:同时进行聚类和表示学习的自标注算法
【自然语言处理】【聚类】ECIC:通过迭代分类增强短文本聚类
【自然语言处理】【聚类】TELL:可解释神经聚类
一、简介
聚类作为最基础的无监督学习算法之一,其能在不使用任何标签的情况下将样本分组到不同的簇。由于无法获得充分的向量表示,大多数的聚类算法无法在复杂数据集上取得理想的效果。为了解决表示不充分的问题,研究人员通过深度聚类算法来从图像中抽取表示信息,并促进下游的聚类任务。近期,社区将注意力放在如何以端到端的方式学习向量表示和进行聚类。例如, JULE \text{JULE} JULE逐步合并样本,然后利用聚类的结果作为监督信号来使神经网络学习到更具区分度的向量表示。 DeepCluster \text{DeepCluster} DeepCluster迭代地使用 K-Means \text{K-Means} K-Means进行聚类后,再更新神经网络的参数。这种表示学习和聚类交替的方式会导致误差的累计,只能得到次优解。此外,先前的聚类算法仅能在离线场景中应用,即在整个数据集上进行聚类,这限制了在大规模数据集上进行聚类。
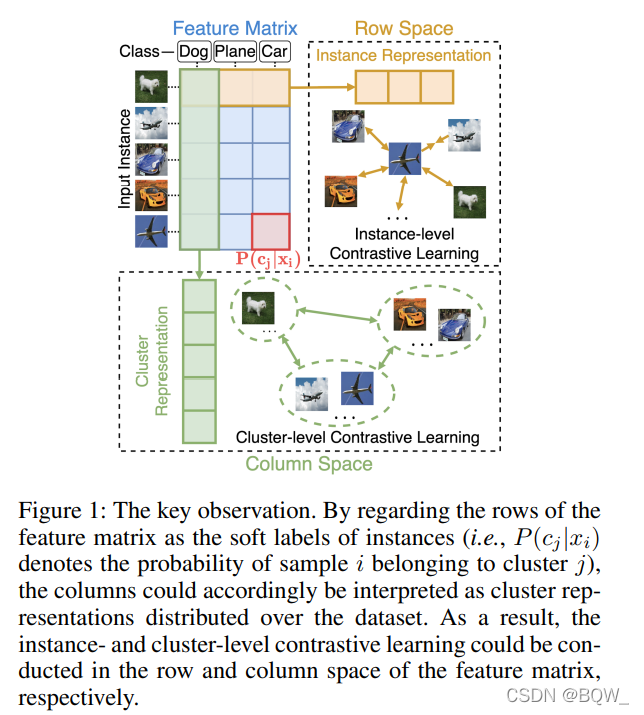
为了克服上述的限制,本文提出了一种单阶段的对比聚类算法( Contrastive Clustering,CC \text{Contrastive Clustering,CC} Contrastive Clustering,CC)。本文的主要想法来源于图1中的观察。深度神经网络在给定数据集上学习到特征矩阵,该矩阵的行和列分别可以看作是实例和簇的表示。从某种意义上说,特征矩阵的行可以看作是簇分配的概率,列则看作是实体在该簇上的分布。基于观察 label as representation \text{label as representation} label as representation,聚类任务可以重新定义为一种独立于实体的特殊表示学习任务。因此,聚类可以被在线执行。
基于上面的观察,本文提出了一种新颖的对偶对比学习框架,用于学习实例和簇的表示。具体来说, CC \text{CC} CC通过数据增强构造的"数据对"来学习特征矩阵,然后在特征矩阵的行和列空间上分别执行实例级(Instance-level)和簇级(cluster-level)的对比学习。 CC \text{CC} CC能够以单阶段、端到端的在线聚类方式学习到具有区分度的特征。总的来说,贡献如下:
- 本文揭示了特征矩阵的行和列本质上对应着实例和簇的表示。基于此,深度聚类能够优雅的统一至表示学习;
- 本文提出的方法不仅在实例上执行对比学习,也在簇级执行对比学习。这样的对偶学习框架能够产生有益于聚类的表示;
- 本文提出的方法是单阶段、端到端的方式,仅需要基于batch进行优化就能够应用在大规模数据集上。此外,该方法不需要访问整个数据集就能及时预测每个新数据的聚类分配,非常适合在线场景。
二、方法
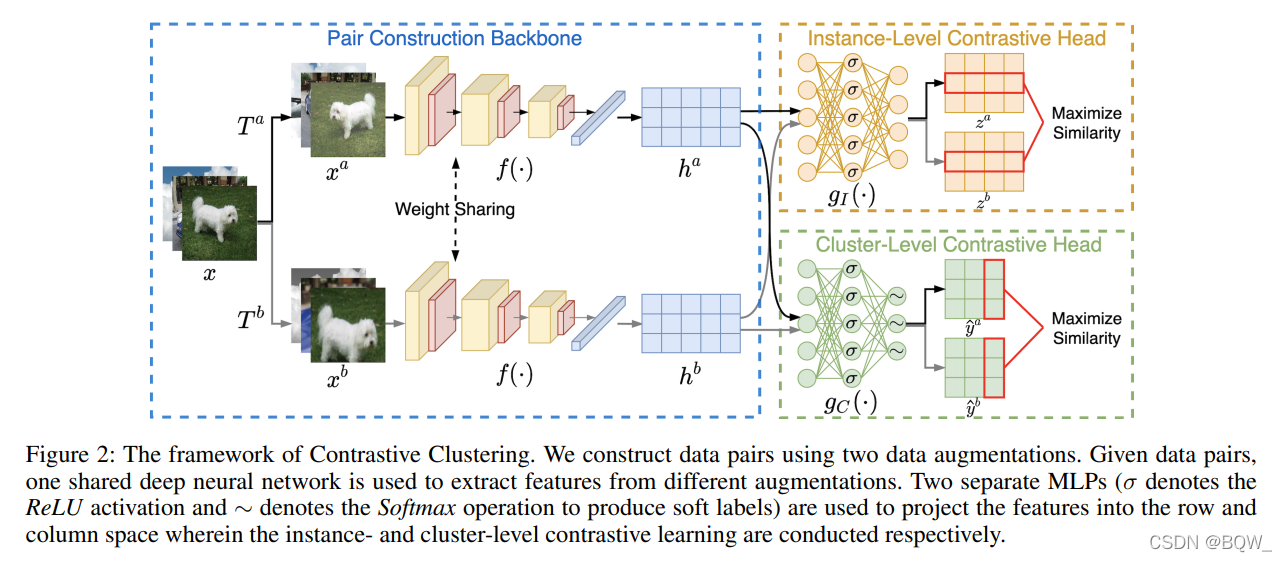
如上图所示,本文的方法由三个学习组件构成:一个样本对构建模块 PCB \text{PCB} PCB、一个实例级对比头 ICH \text{ICH} ICH和一个簇级对比头 CCH \text{CCH} CCH。简单来说, PCB \text{PCB} PCB通过数据增强构造样本对并抽取特征, ICH \text{ICH} ICH和 CCH \text{CCH} CCH则分别在特征矩阵的行和列空间上执行对比学习。训练完成后,通过 CCH \text{CCH} CCH预测的软标签能够获得簇分配。实验发现,通过将实例级和簇级的对比学习分解到两个独立的空间,能够改善聚类算法的表现。
1. 成对样本构建模块 PCB \text{PCB} PCB
CC \text{CC} CC使用数据增强来构建样本对。具体来说,给定一个数据实例 x i x_i xi后,从数据增强集合 T \mathcal{T} T中随机采样两种数据变换 T a T^a Ta和 T b T^b Tb。将两个变换应用在样本上,获得表示 x i a = T a ( x i ) x_i^a=T^a(x_i) xia=Ta(xi)和 x i b = T b ( x i ) x_i^b=T^b(x_i) xib=Tb(xi)。先前的研究已经表明,选择合适的增强策略对于提高下游任务的表现至关重要。因此,本文选择了5中类型的数据增强,分别是: ResizedCrop \text{ResizedCrop} ResizedCrop、 ColorJitter \text{ColorJitter} ColorJitter、 Grayscale \text{Grayscale} Grayscale、 HorizontalFlip \text{HorizontalFlip} HorizontalFlip和 GaussianBlur \text{GaussianBlur} GaussianBlur。对于给定的图像, 每种数据增强都以固定的概率应用在该图像上。具体来说, ResizedCrop \text{ResizedCrop} ResizedCrop会随机裁剪图像的尺寸,并将裁剪后的图像重新缩放至原始尺寸。 ColorJitter \text{ColorJitter} ColorJitter改变图像的亮度、对比度和饱和度。 Grayscale \text{Grayscale} Grayscale会转换一个图像为灰度图。 HorizontalFlip \text{HorizontalFlip} HorizontalFlip会水平翻转图像。 GaussianBlur \text{GaussianBlur} GaussianBlur则会使用高斯函数来模糊图像。
一个共享的深度神经网络 f ( ⋅ ) f(\cdot) f(⋅)用例从增强样本中抽取特征,即 h i a = f ( x i a ) h_i^a=f(x_i^a) hia=f(xia)和 h i b = f ( x i b ) h_i^b=f(x_i^b) hib=f(xib)。理论上,本文的方法并不依赖具体的网络结构。但是为了公平比较,本文采用 ResNet34 \text{ResNet34} ResNet34作为主干网络。
2. 实例级对比头 ICH \text{ICH} ICH
对比学习的目标是,最大化正样本对相似度的同时,最小化负样本对。样本对的特性可以用不同的标准来定义。例如,可以定义类内样本对为正例,其余为负例。在本文中,由于聚类任务并没有先验的标签可以使用,因此实例级别对比学习的正、负样本就通过数据增强产生的伪标签来构建。具体来说,相同实例的不同增强样本构建正样本对,其余为负样本对。
正式来说,给定一个大小为
N
N
N的batch,
CC
\text{CC}
CC在每个实例
x
i
x_i
xi上执行两种类型的数据增强,产生
2
N
2N
2N个数据样本
{
x
1
a
,
…
,
x
N
a
,
x
1
b
,
…
,
x
N
b
}
\{x_1^a,\dots,x_N^a,x_1^b,\dots,x_N^b\}
{x1a,…,xNa,x1b,…,xNb}。具体到样本
x
i
a
x_i^a
xia,其能构造
2
N
−
1
2N-1
2N−1个样本对,选择其对应的增强样本
x
i
b
x_i^b
xib来形成正样本对
{
x
i
a
,
x
i
b
}
\{x_i^a,x_i^b\}
{xia,xib},其余
2
N
−
2
2N-2
2N−2个负样本对。直接在特征矩阵上执行对比损失函数会导致信息丢失。因此,使用非线性
MLP g
I
(
⋅
)
\text{MLP g}_I(\cdot)
MLP gI(⋅)将特征映射至子空间,即
z
i
a
=
g
I
(
h
i
a
)
z_i^a=g_I(h_i^a)
zia=gI(hia)。然后在映射后的子空间上执行对比学习。样本对的相似度通过
cosine
\text{cosine}
cosine相似度来衡量
s
(
z
i
k
1
,
z
j
k
2
)
=
(
z
i
k
1
)
(
z
j
k
2
)
⊤
∥
z
i
k
1
∥
∥
z
j
k
2
∥
(1)
s(z_i^{k_1},z_{j}^{k_2})=\frac{(z_i^{k_1})(z_j^{k_2})^\top}{\parallel z_i^{k_1} \parallel\parallel z_j^{k_2} \parallel} \tag{1}
s(zik1,zjk2)=∥zik1∥∥zjk2∥(zik1)(zjk2)⊤(1)
其中,
k
1
,
k
2
∈
{
a
,
b
}
k_1,k_2\in\{a,b\}
k1,k2∈{a,b}且
i
,
j
∈
[
1
,
N
]
i,j\in[1,N]
i,j∈[1,N]。不失一般性的,给定样本
x
i
a
x_i^a
xia的相似度优化损失函数为
l
i
a
=
−
log
exp
(
s
(
z
i
a
,
z
i
b
)
/
τ
I
)
∑
j
=
1
N
[
exp
(
s
(
z
i
a
,
z
j
a
)
/
τ
I
)
+
exp
(
s
(
z
i
a
,
z
j
b
)
/
τ
I
)
]
(2)
l_i^a=-\text{log}\frac{\text{exp}(s(z_i^a,z_i^b)/\tau_I)}{\sum_{j=1}^N[\text{exp}(s(z_i^a,z_j^a)/\tau_I)+\text{exp}(s(z_i^a,z_j^b)/\tau_I)]} \tag{2}
lia=−log∑j=1N[exp(s(zia,zja)/τI)+exp(s(zia,zjb)/τI)]exp(s(zia,zib)/τI)(2)
其中,
τ
I
\tau_I
τI是实例级temperature参数。
实例级对比学习在整个数据集上的损失函数为
L
i
n
s
=
1
2
N
∑
i
=
1
N
(
l
i
a
+
l
i
b
)
(3)
\mathcal{L}_{ins}=\frac{1}{2N}\sum_{i=1}^N(l_i^a+l_i^b) \tag{3}
Lins=2N1i=1∑N(lia+lib)(3)
3. 簇基本对比头 CCH \text{CCH} CCH
基于观察 “label as representation” \text{“label as representation”} “label as representation”,当将一个样本投影至维度等于簇数量的空间中时,投影特征的第 i i i个元素可以看作是该样本属于第 i i i个簇的概率,而整个特征向量表示其簇分配的软标签。
正式来说,对于mini-batch中第一个增强样本, CCH \text{CCH} CCH的输出表示为 Y a ∈ R N × M Y^a\in\mathcal{R}^{N\times M} Ya∈RN×M;第二个增强样本的输出为 Y b Y^b Yb,其中 N N N是batch size, M M M等于簇的数量。 Y n , m a Y_{n,m}^a Yn,ma可以看作是样本 n n n被分配到簇 m m m上的概率。由于每个样本都仅属于一个簇,因此理想情况下 Y a Y^a Ya的行倾向于one-hot编码。从这个意义上来看, Y a Y^a Ya的第 i i i个列可以看作是第 i i i个簇的向量表示,且所有的列都应该彼此不同。
类似于实例级对比中的
g
I
(
⋅
)
g_I(\cdot)
gI(⋅),这里也使用全链接网络
g
C
(
⋅
)
g_C(\cdot)
gC(⋅)将特征投影至
M
M
M维空间。即
y
i
a
=
g
C
(
h
i
a
)
y_i^a=g_C(h_i^a)
yia=gC(hia),
y
i
a
y_i^a
yia表示样本
x
i
a
x_i^a
xia的软标签,也就是
Y
a
Y^a
Ya的第
i
i
i行。为了方便,令
y
^
i
a
\hat{y}_i^a
y^ia为
Y
a
Y^a
Ya的第
i
i
i列。合并
y
^
i
a
\hat{y}_i^a
y^ia和
y
^
i
b
\hat{y}_i^b
y^ib来构成簇级的正样本对
{
y
^
i
a
,
y
^
i
b
}
\{\hat{y}_i^a,\hat{y}_i^b\}
{y^ia,y^ib},其余的
2
M
−
2
2M-2
2M−2个构成负样本对。同样使用
cosine
\text{cosine}
cosine距离来衡量簇间的相似度
s
(
y
^
i
k
1
,
y
^
j
k
2
)
=
(
y
^
i
k
1
)
⊤
(
y
^
j
k
2
)
∥
y
^
i
k
1
∥
∥
y
^
j
k
2
∥
(4)
s(\hat{y}_i^{k_1},\hat{y}_j^{k_2})=\frac{(\hat{y}_i^{k_1})^\top(\hat{y}_j^{k_2})}{\parallel\hat{y}_i^{k_1}\parallel\parallel\hat{y}_j^{k_2}\parallel} \tag{4}
s(y^ik1,y^jk2)=∥y^ik1∥∥y^jk2∥(y^ik1)⊤(y^jk2)(4)
其中,
k
1
,
k
2
∈
{
a
,
b
}
k_1,k_2\in\{a,b\}
k1,k2∈{a,b}且
i
,
j
∈
[
1
,
M
]
i,j\in[1,M]
i,j∈[1,M]。簇对比损失函数为
l
^
i
a
=
−
log
exp
(
s
(
y
^
i
a
,
y
^
i
b
)
/
τ
C
)
∑
j
=
1
M
[
exp
(
s
(
y
^
i
a
,
y
^
j
a
)
/
τ
C
)
]
+
exp
(
s
(
y
^
i
a
,
y
^
j
b
)
/
τ
C
)
(5)
\hat{l}_i^a=-\text{log}\frac{\text{exp}(s(\hat{y}_i^a,\hat{y}_i^b)/\tau_C)}{\sum_{j=1}^M[\text{exp}(s(\hat{y}_i^a,\hat{y}_j^a)/\tau_C)]+\text{exp}(s(\hat{y}_i^a,\hat{y}_j^b)/\tau_C)} \tag{5}
l^ia=−log∑j=1M[exp(s(y^ia,y^ja)/τC)]+exp(s(y^ia,y^jb)/τC)exp(s(y^ia,y^ib)/τC)(5)
其中,
τ
C
\tau_C
τC是簇级temperature参数。所有簇的对比损失函数为
L
c
l
u
=
1
2
M
∑
i
=
1
M
(
l
^
i
a
+
l
^
i
b
)
−
H
(
Y
)
(6)
\mathcal{L}_{clu}=\frac{1}{2M}\sum_{i=1}^M(\hat{l}_i^a+\hat{l}_i^b)-H(Y)\tag{6}
Lclu=2M1i=1∑M(l^ia+l^ib)−H(Y)(6)
4. 目标函数
ICH
\text{ICH}
ICH和
CCH
\text{CCH}
CCH是单阶段、端到端的优化。整个目标函数由实例级和簇级对比损失函数组成
L
=
L
i
n
s
+
L
c
l
u
(7)
\mathcal{L}=\mathcal{L}_{ins}+\mathcal{L}_{clu}\tag{7}
L=Lins+Lclu(7)
其中,
H
(
Y
)
=
−
∑
i
=
1
M
[
P
(
y
^
i
a
)
log
P
(
y
^
i
a
)
+
P
(
y
^
i
b
)
log
P
(
y
^
i
b
)
]
H(Y)=-\sum_{i=1}^M[P(\hat{y}_i^a)\text{log}P(\hat{y}_i^a)+P(\hat{y}_i^b)\text{log}P(\hat{y}_i^b)]
H(Y)=−∑i=1M[P(y^ia)logP(y^ia)+P(y^ib)logP(y^ib)]是簇分配概率
P
(
y
^
i
k
)
P(\hat{y}_i^k)
P(y^ik)的熵。每个mini-batch下的簇分配概率为
P
(
y
^
i
k
)
=
∑
t
=
1
N
Y
t
i
k
/
∥
Y
k
∥
1
,
k
∈
{
a
,
b
}
P(\hat{y}_i^k)=\sum_{t=1}^NY_{ti}^k/\parallel Y^k\parallel_1,k\in\{a,b\}
P(y^ik)=∑t=1NYtik/∥Yk∥1,k∈{a,b}。这个项用于避免将大多数实例分配至相同簇的平凡解问题。
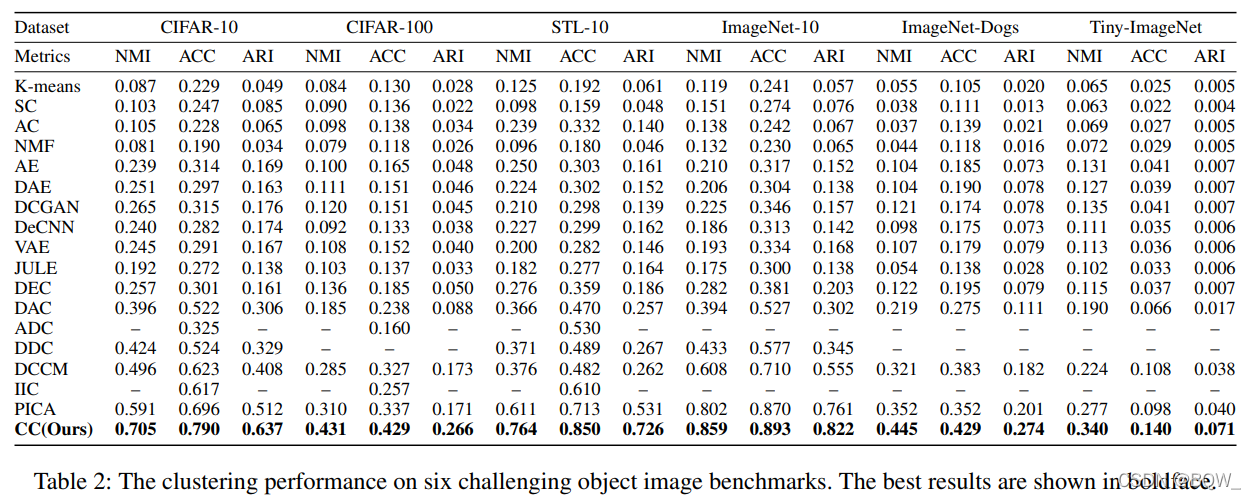
三、实验
四、总结
- 将特征矩阵的列看作是聚类中簇的向量表示,从而进行优化;
- 将聚类问题转换为纯表示学习;


















 1961
1961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











