







之前,有写了一篇博文,【深度学习入门】——亲手实现图像卷积操作介绍卷积的相应知识,但那篇文章更多的是以滤波器的角度去讲解卷积。但实际上是神经网络中该博文内容并不适应。
之前的文章为了便于演示,针对的是二维卷积,比如一张图片有 RGB 三个颜色通道,我的方式是每个通道单独卷积,然后将各个通道合成一张图片,再可视化出来。但真实工程不会是这样的,很多东西需要进一步说明白。
熟悉 TensorFlow 的同学大概对这个函数比较熟悉。
tf.nn.conv2d(
input,
filter,
strides,
padding,
use_cudnn_on_gpu=True,
data_format='NHWC',
dilations=[1, 1, 1, 1],
name=None
)
其中 input 自然是卷积的输入,而 filter 自然就是滤波器。
它们的格式说明如下:
input:
[batch, in_height, in_width, in_channels]
filter
[filter_height, filter_width, in_channels, out_channels]
input 的 4 个参数很好理解,分别是批数量、高、宽、通道数。
但是,我当时在学习时有一个疑惑不能理解,那就是为什么 filter 有 2 个通道相关的参数呢?
按照网络上的建议,我大概知道 input 的 in_channels 和 filter 的 in_channels 要对应起来,而 out_channels 是卷积后生成的 featuremap 的通道数量,但是其中的计算细节,我并不知道。
为什么颜色通道为 3 的图像,经过卷积后,它的通道数量可以变成 128 或者其它呢?这是我的疑问。
后来,我发现自己有这个疑问是因为对卷积的概念理解不清楚。
我误以为,卷积过程中滤波器是 2 维的,只有宽高,通道数为 1.
实际上,真实的情况是,卷积过程中,输入层有多少个通道,滤波器就要有多少个通道,但是滤波器的数量是任意的,滤波器的数量决定了卷积后 featuremap 的通道数。
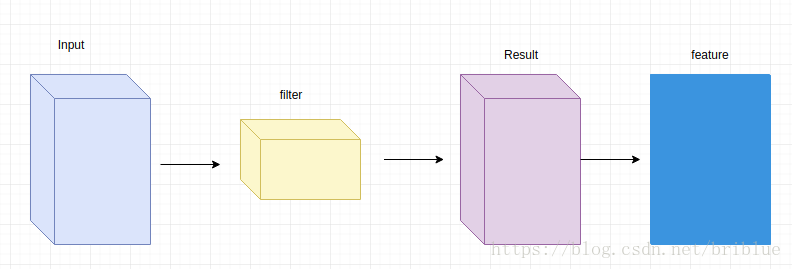
如果把输入当做一个立方体的话,那么 filter 也是一个立方体,它们卷积的结果也是一个立方体,并且上面中 input、filter、Result 的通道都是一致的。
但卷积过程的最后一步要包括生成 feature,很简单,将 Result 各个通道对应坐标的值相加就生成了 feature,相当于将多维的 Result 压缩成了 2 维的 feature。
可能有同学会问,为什么需要压缩 Result 到 2 维呢?
我们回顾,卷积的公式。
y ( n ) = ∑ i = − ∞ ∞ x ( i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











