










[论文笔记 CVPR2020]Adaptive Dilated Network with Self-Correction Supervision for Counting
论文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Bai_Adaptive_Dilated_Network_With_Self-Correction_Supervision_for_Counting_CVPR_2020_paper.pdf
概述摘要 Abstract
计数问题旨在估计图片中的目标物体的个数。由于图片中目标物体的尺度剧烈变化或者是由标注误差引起的估计不准确问题,使得计数问题仍然是一个有挑战性的任务。现如今,基于静态密度图监督学习的框架被广泛使用,即使用高斯核去生成密度图作为学习目标,然后使用欧几里得距离(L2距离)来优化模型。然而这种框架对于标注误差是不能容忍的,会影响估计精度,同时也不能反映出尺度的变化。
因此,本文提出一种自适应空洞卷积和自校正监督学习框架(self-correction supervision)。在自校正阶段(利用EM算法思想),会利用模型的输出迭代地区纠正标注,同时应用SC loss来优化模型;在特征提取阶段,提出自适应空洞卷积来对每一个位置预测一个连续的空洞率值,相比于固定离散的空洞率值能更好地使用尺度变化。
挑战与动机 Challenges & Motivation
- How to effectively supervise the learning process?
- How to effectively address the large scale variation problem?

Three limitations in this supervised method
- the labeling deviation makes the target density map not accurate.
- the variance of the Gaussian density map does not match the scale of the target.
- L2 loss is sensitive to the deviation of position and the change of variance.
贡献 Contributions
- 提出了一种新的监督学习框架,有效地利用模型的输出结果去循环迭代校正标注误差(利用EM算法的思想)。同时SC loss能够对图像的全局和局部进行同时一致优化。
- 提出了一种自适应空洞卷积,能够在图像中的不同位置去学习一个连续的空洞率(具体的值)从而有效地能够match不同位置的尺度变化。此外,这种方法要比多尺度特征融合和多列网络效果要好,计算量要小。
- 在4个数据集上做了实验,SOTA performance。
模型总体结构 Model Architecture

该文章所提出的模型的总体结构主要是对之前大家常用的人群计数的pipeline进行改进,提出adaptive dilated convolution对特征图进行上采样得到人群密度图,然后使用EM算法对该密度图进行自校正估计从而消除由于标注误差所带来的预测精度上的影响。
Adaptive Dilated Convolution
作者介绍了他们提出的adaptive dialted convolution,使用双线性插值计算出空洞之后的卷积值。
具体层数结构如图所示。

为什么不使用Deformable Convolution呢?
很容易想到既然是想让其感受野连续变化而并非离散,那为什么不使用deformable convolution呢?作者指出可变形卷积在采样网格的每个位置都引入了不对称偏移,导致提取的特征存在空间偏差。在目标检测中,对估计的boundingbox进行回归校正,以减轻偏差。但是,计数问题是位置敏感的任务,每个位置的密度和特征需要很强的一致性。存在空间偏差的特征会导致错误的学习,因此自适应空洞卷积在计数问题上比变形卷积更合理。此外,与预测每个核重的偏移量相比,仅预测一个空洞率值计算量更小,网络更轻量。
自校正监督框架 Self-correction Supervised Framework
使用EM方法来对模型进行估计从而优化校正标注,可以有效地消除标注误差带来的影响。我们将密度图看作是一个高斯混合模型,包含了K个二维的高斯分布,K是图片中人的个数。在这样的设置中,点标注被用于初始化这个高斯混合模型。
- E步用于校正和估计每个位置和对应高斯分布的一个对应的依赖关系。也就是当前的这个人有多大的概率是属于哪一个高斯分布。
- M步通过最大化complete data likelihood用来更新高斯混合模型的参数(包括mean,covariance,mixing coefficient)。
- 然后E步和M步如此循环迭代,依次执行。(后续实验结果说明迭代2次效果在数据集上表现最好)
对于loss function,不使用L2 loss来优化我们的模型,使用自校正损失self-correction loss来优化。对于全局,我们生成了一张新的带重估计参数的density map作为GT;对于局部,我们向每个高斯的mixing coefficient引入监督信息。
S
C
L
o
s
s
=
λ
1
L
d
e
n
s
i
t
y
m
a
p
+
λ
2
L
c
o
e
f
f
i
c
i
e
n
t
SC\ Loss = \lambda_1 L_{density\ map} + \lambda_2 L_{coefficient}
SC Loss=λ1Ldensity map+λ2Lcoefficient
L
d
e
n
s
i
t
y
m
a
p
=
1
N
∑
n
=
1
N
∣
D
e
s
t
(
x
n
)
−
D
g
t
(
t
)
(
x
n
)
∣
L_{density\ map} = \frac{1}{N} \sum_{n=1}^{N}|D_{est}(x_n) - D_{gt}^{(t)}(x_n)|
Ldensity map=N1n=1∑N∣Dest(xn)−Dgt(t)(xn)∣
L
c
o
e
f
f
i
c
i
e
n
t
=
∑
k
=
1
K
∣
π
~
k
(
t
)
−
1
K
∣
L_{coefficient} = \sum_{k=1}^{K}|\widetilde{\pi}_k^{(t)} - \frac{1}{K}|
Lcoefficient=k=1∑K∣π
k(t)−K1∣
其中,在论文中这里取
λ
1
\lambda_1
λ1和
λ
2
\lambda_2
λ2为1。
进一步,不同区域位置应该使用不同的感受野以能使得模型能够容易区分。
Responsibility Estimation
使用后验概率来估计第
n
n
n个位置和第
k
k
k个高斯分布之间的responsibility。
用如下公式进行计算和估计。
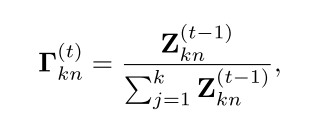
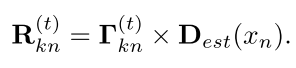
Likelihood Maximizaiton
在Responsibility Estimation中计算得到的
R
k
(
t
)
R_k^{(t)}
Rk(t),然后根据如下公式进行计算出均值和协方差矩阵以及
π
k
\pi_k
πk。

消融实验及实验结果
-
不同的迭代次数对模型性能的影响,实验结果发现在ShanghaiTechA数据集上,迭代两次取得更低的MAE。

-
batch size和batch normalization layer的影响。
-
CSRNet ∗ \text{CSRNet}^* CSRNet∗引入了BN层以及做了数据增强(随机cropping和resizing)。
-
baseline \text{baseline} baseline使用的是VGG16_bn作为backbone,和 CSRNet ∗ \text{CSRNet}^* CSRNet∗有相同的decoder结构,但是空洞率为1。

-
estimated density map和dialtion map的可视化分析。

-
有没有Self-correction对结果的影响

-
实验结果大表

-
不同的空洞率对实验结果的影响。
















 2582
2582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









