







上一篇我们主要学习了目标检测的背景、指标、数据集等内容,点下方可以跳转
这次我们继续讲讲目标检测的经典算法,目标检测算法主要有以下几种:
1、基于候选区域的目标检测器(区域+分类的两步算法)
RCNN——SPP-Net——Fast RCNN——Faster RCNN——Mask RCNN
特点是精确度较高,mAP指数较高
2、基于回归的检测算法(一步算法)
YOLO——YOLOv2——YOLOv3
SSD
RetinaNet
特点是实时性,处理图片速度快
RCNN作为深度学习目标检测的开山之作,是目标检测绕不开的重要概念,因此我们将从这里开始。
RCNN(Regions with CNN features)是将CNN方法应用到目标检测问题上的一个里程碑,由Ross B. Girshick(人称RGB大神)提出,使用Region Proposal + CNN代替传统目标检测使用的滑动窗口+手工设计特征,使得目标检测取得巨大突破,并开启了基于深度学习目标检测的热潮。
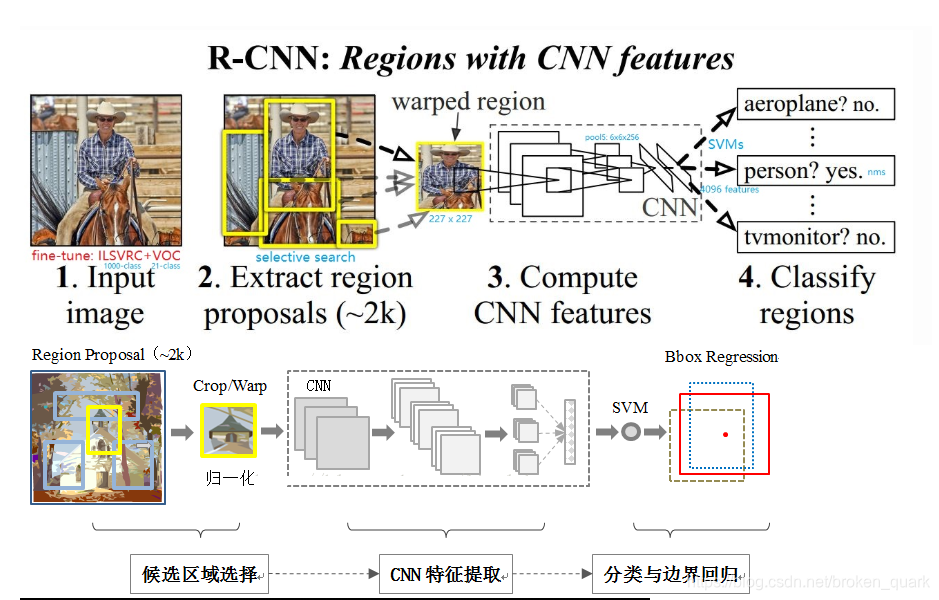
具体的实现思路是:
- 训练或者下载一个分类模型(文中使用了AlexNet),并对该模型进行调优(fine-tuning),以适应当前分类的需要。使网络开始之前参数都是经过训练过的参数,该技巧可以大大提高精度,这种方法叫有监督的训练方式(也称为迁移学习)。
- 输入一张图片,使用选择性搜索(Selective Search)算法从图像中选取2000个左右的可能包含物体的候选区域(Region Proposal)
- 将上面取出的候选区域进行各向异性缩放为固定大小227*227(缩放前在图片周围添加了边框padding为16像素),作为CNN的输入(CNN需要固定输入和输出),做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘
- 训练一个SVM分类器(二分类)来判断这个候选框中目标的类别,每一个类别对应一个SVM,判断是否属于该类别。去掉AlexNet最后一层输出层,将第七层的结果使用SVM进行判断,得到一定的分数。作者测试了IOU阈值各种方案数值0,0.1,0.2,0.3,0.4,0.5。最后我们通过训练发现,如果选择IOU阈值为0.3效果最好(选择为0精度下降了4个百分点,选择0.5精度下降了5个百分点),即当重叠度小于0.3的时候,我们就把它标注为负样本。
- 利用上一步骤的打分,使用非极大抑制去除重复框,使用边框回归算法修正候选框位置,即对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。
R-CNN 在 PASCAL-VOC 2010-12 的表现
R-CNN 是在 PASCAL VOC 2012 进行最终的 fine-tune,也是在 VOC 2012 的训练集上优化 SVM.
然后,还与当时 4 个强劲的对手,也就是 4 个不同的目标检测算法进行了比较。

值得关注的是,上面表格中 UVA 检测系统也采取了相同的候选区域算法,但 R-CNN 的表现要好于它。
一些实现的细节:
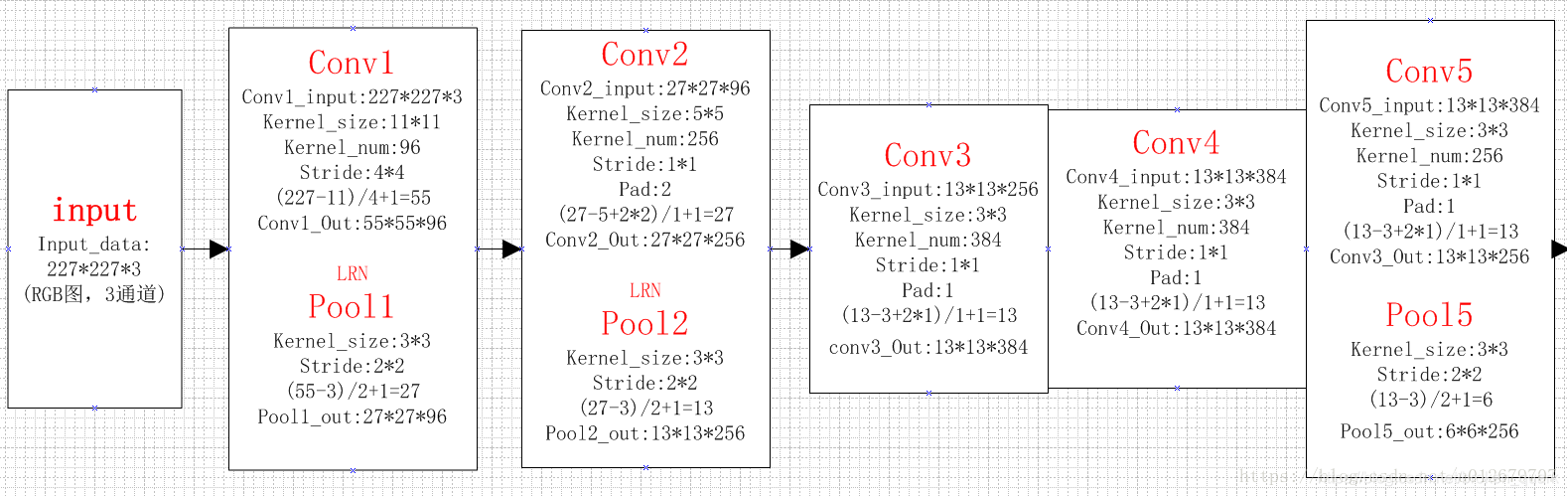
1、Alexnet
AlexNet为8层深度网络,其中5层卷积层和3层全连接层,不计LRN层和池化层。具体每一层的构成如下:
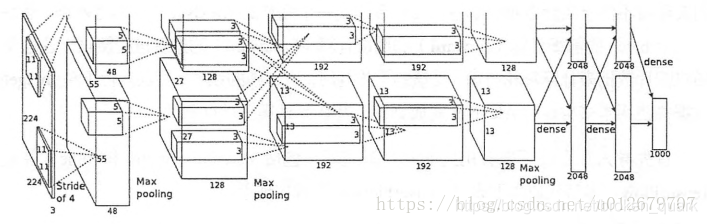
卷积层C1
该层的处理流程是: 卷积-->ReLU-->池化-->归一化。
卷积,输入是227×227,使用96个11×11×3的卷积核,得到的FeatureMap为55×55×96。
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中。
池化,使用3×3步长为2的池化单元(重叠池化,步长小于池化单元的宽度),输出为27×27×96((55−3)/2+1=27)
局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为27×27×96,输出分为两组,每组的大小为27×27×48
卷积层C2
该层的处理流程是:卷积-->ReLU-->池化-->归一化
卷积,输入是2组27×27×48。使用2组,每组128个尺寸为5×5×48的卷积核,并作了边缘填充padding=2,卷积的步长为1. 则输出的FeatureMap为2组,每组的大小为27×27 times128. ((27+2∗2−5)/1+1=27)
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为(27−3)/2+1=13,输出为13×13×256
局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为13×13×256,输出分为2组,每组的大小为13×13×128
卷积层C3
该层的处理流程是: 卷积-->ReLU
卷积,输入是13×13×256,使用2组共384尺寸为3×3×256的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times384
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
卷积层C4
该层的处理流程是: 卷积-->ReLU
该层和C3类似。
卷积,输入是13×13×384,分为两组,每组为13×13×192.使用2组,每组192个尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times384,分为两组,每组为13×13×192
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
卷积层C5
该层处理流程为:卷积-->ReLU-->池化
卷积,输入为13×13×384,分为两组,每组为13×13×192。使用2组,每组为128尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13×256
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
池化,池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为 (13−3)/2+1=6,即池化后的输出为6×6×256
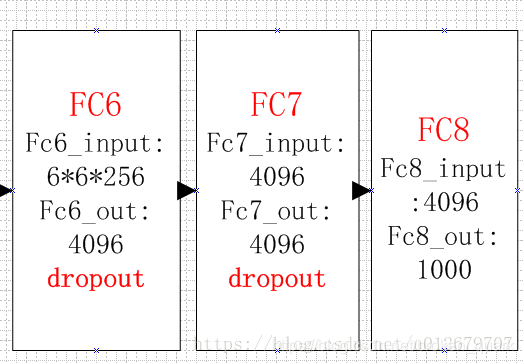
全连接层FC6
该层的流程为:(卷积)全连接 -->ReLU -->Dropout
卷积->全连接: 输入为6×6×256,该层有4096个卷积核,每个卷积核的大小为6×6×256。由于卷积核的尺寸刚好与待处理特征图(输入)的尺寸相同,即卷积核中的每个系数只与特征图(输入)尺寸的一个像素值相乘,一一对应,因此,该层被称为全连接层。由于卷积核与特征图的尺寸相同,卷积运算后只有一个值,因此,卷积后的像素层尺寸为4096×1×1,即有4096个神经元。
ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
全连接层FC7
流程为:全连接-->ReLU-->Dropout
全连接,输入为4096的向量
ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
输出层
第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值,这就是预测结果。
2、选择性搜索(Selective Search)
通常来说,最常规也是最简单粗暴的方法,就是用不同尺寸的矩形框,一行一行地扫描整张图像,通过提取矩形框内的特征判断是否是待检测物体。这种方法的复杂度极高,所以又被称为穷举检索(exhaustive search)。
下面是选择性搜索的算法框架:

输入:彩色图片。
输出:物体可能的位置,实际上是很多的矩形坐标。
首先,将图片初始化为很多小区域R(图的分割算法)。
初始化一个相似集合为空集:S
计算所有相邻区域之间的相似度,放入集合 S 中,集合 S 保存的其实是一个区域对以及它们之间的相似度。
找出 S 中相似度最高的区域对,将它们合并,并从 S 中删除与它们相关的所有相似度和区域对。重新计算这个新区域与周围区域的相似度,放入集合 S 中,并将这个新合并的区域放入集合 R 中。重复这个步骤直到 S 为空。
从 R 中找出所有区域的 bounding box(即包围该区域的最小矩形框),这些 box 就是物体可能的区域。
3、调优(fine-tuning)
所谓fine-tuning就是用别人训练好的模型,加上我们自己的数据,来训练新的模型。fine-tuning相当于使用别人的模型的前几层,来提取浅层特征,然后在最后再落入我们自己的分类中。
fine-tuning的好处在于不用完全重新训练模型,从而提高效率,因为一般新训练模型准确率都会从很低的值开始慢慢上升,但是fine-tuning能够让我们在比较少的迭代次数之后得到一个比较好的效果。在数据量不是很大的情况下,fine-tuning会是一个比较好的选择。
R-CNN 采取迁移学习。提取在 ILSVRC 2012 的模型和权重,然后在 VOC 上进行 fine-tuning。需要注意的是,这里在 ImageNet 上训练的是模型识别物体类型的能力,而不是预测 bounding box位置的能力。
ImageNet 的训练当中需要预测 1000个类别,而 R-CNN 在 VOC 上进行迁移学习时,神经网络只需要识别 21个类别。因此本文将ImageNet上的原模型分类数从1000改为21,即20个物体类别+ 1个背景,并去掉最后一个全连接层。论文经过实验,得出一般的CNN网络,前5层是用于特征提取的,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。文献paper给我们证明了一个理论,如果你不进行fine-tuning,类似于HOG、SIFT一样做特征提取,不针对特定的任务。然后把提取的特征用于分类,结果发现p5的精度竟然跟f6、f7差不多,而且f6提取到的特征还比f7的精度略高;如果你进行fine-tuning了,那么f7、f6的提取到的特征在最后训练的svm分类器的精度就会飙涨。
训练数据为使用PASCAL VOC 2007的训练集,输入一张图片,输出21维的类别标号,表示20类+背景。
考察一个候选框和当前图像上所有标定框(人工标注的候选框)重叠面积最大的一个。如果重叠比例大于0.5,则认为此候选框为此标定的类别;否则认为此候选框为背景。
训练策略是:采用 SGD 训练,初始学习率为 0.001,mini-batch 大小为 128,每一个batch包含32个正样本(属于20类)和96个背景的负样本。
4、边框回归
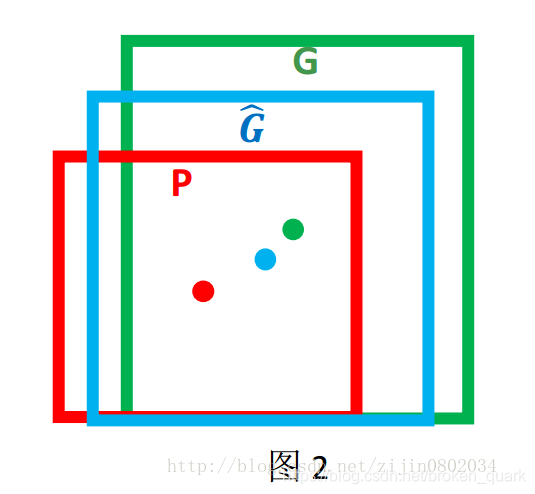
对于窗口一般使用四维向量(x,y,w,h)来表示, 分别表示窗口的中心点坐标和宽高。 对于图 2, 红色的框 P 代表原始的预测框(Proposal region), 绿色的框 G 代表目标的真实框(Ground Truth), 我们的目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口G^。
 。
。
边框回归的目的是:给定(Px,Py,Pw,Ph)寻找一种映射f,使得f(Px,Py,Pw,Ph)=(Gx^,Gy^,Gw^,Gh^),并且(Gx^,Gy^,Gw^,Gh^)≈(Gx,Gy,Gw,Gh)。
那么经过何种变换才能从图 2 中的窗口 P 变为窗口G^呢? 比较简单的思路就是: 平移+尺度放缩。
先做平移(Δx,Δy), Δx=Pwdx(P),Δy=Phdy(P)这是R-CNN论文的:
G^x=Pwdx(P)+Px,(1)
G^y=Phdy(P)+Py,(2)
然后再做尺度缩放(Sw,Sh), Sw=exp(dw(P)),Sh=exp(dh(P)), 对应论文中:
G^w=Pwexp(dw(P)),(3)
G^h=Phexp(dh(P)),(4)
观察(1)-(4)我们发现, 边框回归学习就是dx(P),dy(P),dw(P),dh(P)这四个变换。在边框回归的全连接层,输入的是候选区域的特征信息X以及其边框信息P,要学习的是全连接层的权值矩阵W,也就说回归的全连接层就实现了上述变换,输出的是dx(P),dy(P),dw(P),dh(P),经过上述公式的可以得到平移和缩放(Δx,Δy,Sw,Sh)。 对候选区域的边框进行该平移和缩放得到的边框尽可能的和Ground Truth相近。
5、非极大抑制(NMS)
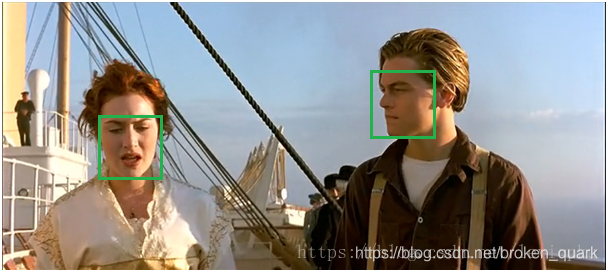
非极大值抑制(NMS, non maximum suppression),就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的边界框(bounding box)。对于有重叠在一起的预测框,只保留得分最高的那个。简单来说就是去掉detection任务重复的检测框。(上文我们介绍过,这一步主要用在RCNN的SVM步骤之后)
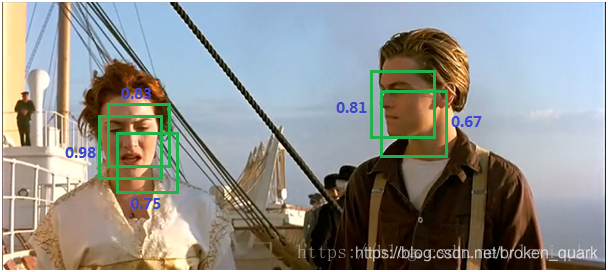
(1)NMS计算出每一个bounding box的面积,然后根据score(分数,也就是框中有该类别的概率)进行排序,把score最大的bounding box作为队列中首个要比较的对象;
(2)计算其余bounding box与当前最大score的bounding box的IoU,去除IoU大于设定的阈值的bounding box,保留小的IoU的预测框;
(3)从剩下的bounding box重复上面的过程,直至候选bounding box为空。
本文部分素材来自以下博客:
RCNN
https://blog.csdn.net/briblue/article/details/82012575
https://luckmoonlight.github.io/2018/10/29/RCNN/
https://blog.csdn.net/hjimce/article/details/50187029
Alexnet
https://blog.csdn.net/u012679707/article/details/80793916
Selective search
https://zhuanlan.zhihu.com/p/27467369
边框回归
https://blog.csdn.net/zijin0802034/article/details/77685438/
非极大抑制

















 3019
3019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









