







 论文Network in Network提出将卷积层替换为MLP,增强了CNN对非线性特征的捕捉能力,并用全局平均池化层代替全连接层,减少过拟合。实验在CIFAR-10等数据集上验证了NIN的有效性。
论文Network in Network提出将卷积层替换为MLP,增强了CNN对非线性特征的捕捉能力,并用全局平均池化层代替全连接层,减少过拟合。实验在CIFAR-10等数据集上验证了NIN的有效性。
这篇文章是在2014年3月份发表的,由颜水成老师等人撰写。该论文对原先常用的CNN网络结构,即先是一些卷积层和池化层,最后会展开连接一些全连接层,最终通过softmax层连接到输出层,提出了两点改进,最主要的就像论文的题目所说的是对卷积层做出了改进,不再是使用N个卷积核对每一层的输入张量做一次卷积计算,而是改成一种网络(文中用的是MLP)来做类似于这里的卷积的操作,从而捕捉到更多的非线性特征。第二点就是去掉了传统的最后的全连接层,改为对最后一次MLP卷积得到的多个特征图的每一个特征图分别做全局平均池化操作,得到一个向量,再把该向量连接到最后的softmax层预测出输出。
1. Introduction
正如前面摘要所说,CNN的特别之处主要就是由一些卷积层和池化层组成。而卷积层对前一输入层的每一个点先是通过线性过滤器linear filter和前一层的感受野receptive field做内积,然后再加上一个非线性的激活函数。有几个线性过滤器就可以得到几个通道的输出层,输出的结果被称为特征图feature map。
这样一个使用固定权重的线性过滤器对前一层每一个位置的patch做内积的操作,其实就是一个广义线性模型Generalized Linear Model,作者提出这样一种简单的广义线性模型其实只能够对原输入做比较低级的特征抽象。因为这里使用了线性模型就是假设了原来的隐藏的概念可以被线性表达,但是实际上同一概念的数据往往是存在在一个非线性空间的,因而作者要用一个非线性模型来表达。所以,作者用Network in Network(NIN)来替代CNN的卷积层的这种GLM操作,从而实现对隐藏概念的非线性近似。这里的卷积层中的网络作者选的是多层感知机MLP,因而可以用误差反向传播求梯度。
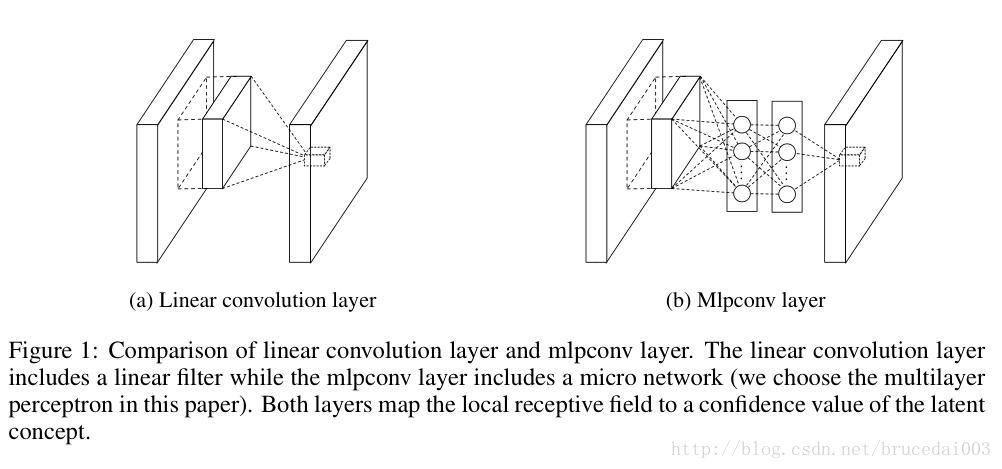
显而易见的看出,原先的线性的卷积层和新提出的MLP卷积层一开始都是使用一个线性核对输入层进行卷积,但是线性卷积层对每一个感受野的输入得到的输出是同样位置的一个长度为depth的新的表达向量,这样就完事了。而MLP卷积层同样也得到这样的表达向量,但是这是他的网络中的网络的隐层的输入,同样这里也使用一个激活函数,然后再全连接到下一个隐层,如此这么般,这么般如此,知道最后输出一个向量到下一层,这个整个网络也是这么的共享参数,对输入层进行平移的。那么中间的这些全连接层其实也相当于是对前一层做一个1x1的卷积,这样就可以把不同通道的信息整合,得到对某一隐藏概念的较为复杂的表达。
除了NIN这种结构的提出,另外一个就是前面说的去掉了最后用作分类的全连接层,改为在最后一个MLP卷积层输出的feature map做全局平均池化global average pooling操作。这个是什么意思呢?其实和平均池化类似的,平均池化不是有一个kernel size吗?通常是2x2的窗口,这样就把前一层的输入长宽都缩小一半。但是谁规定一定得用2x2的窗口来降采样了?也可以把窗口的大小设置成和整个feature map一样大啊,这样我得到的就是一个scalar数字了,而不是一个矩阵了。有多少个feature map来,我就可以给你输出多少个scalar,这些scalar就组成一个向量,再把这样的向量输入到最后的softmax层做分类。
那为什么要用这样的全局平均池化的方式呢?因为原先CNN中使用的全连接层,使得我之前卷积层和池化层得到的空间特征图没法直接和最后属于哪一个类别很好的联系起来,这些全连接层的加入,舍得我原先加入CNN带来的那种空间局部特征的假设的好处没法直接看出来了,这些全连接层就像是一个black box,夹在两者中间。但是全局平均池化层替代了全连接层之后呢,Bingo,这些空间特征啊就可以直接映射到后面属于哪一个类别了,这样可以有更直观的联系,显得更有意义,同时也得益于前面那些非线性的MLP卷积层能够抽取出更高级一些的概念表达,否则你还是很难把那些线性转换得到的概念表达跟类别联系起来,他们之间相对而言没那么强的联系。同时,我们直到全连接层参数很多容易过拟合,但是全局平均池化层它没参数啊,这就相当于加了一个正则化,能减少过拟合。
2. Convolutional Neural Networks
这里又是对这个NIN的MLP卷积层和传统的卷积层做了些比较和分析。提到了一点,传统卷积层没办法表达通常为非线性的隐藏的概念,因为传统的卷积层是线性模型,但是传统的解决方式是什么呢?就是用很多个核,来增加对这种概念的不同的表达,然后再在后面的层得到他们的线性组合,但是这就给后面的层增加了负担,因为这些曾得考虑很多种线性组合来拟合出最优的结果。同时呢,我们知道CNN后面的卷积层的核可以映射到原先输入层的较大的区域,它是通过对较低层的概念进行组合得到后面更高级的概念。那么,我们的MLP卷积层能够提供更高级的概念表达,对后面层的进一步表达更高级概念就会更有好处。
3. Network in Network
这里也没讲什么新的,就是前面讲的这些。
3.1 MLP卷积层
- MLP卷积层网络从输入层到隐层,隐层再到隐层直至最后的输出层的计算公式:
f1i,j,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









