








CVPRW-2020
文章目录
1 Background and Motivation
SOTA 的 CNN 在诸如目标检测等计算机视觉任务中取得令人难以置信的结果,但比较依赖 costly computation resources
本文作者提出轻量级主干网络 Cross Stage Partial Network,achieve a richer gradient combination while reducing the amount of computation
partitioning feature map of the base layer into two parts and then merging them through a proposed crossstage hierarchy.(splitting the gradient flow)
2 Related Work
- CNN architectures design
- Real-time object detector
3 Advantages / Contributions

提出 Cross Stage Partial Network(CSPNet)
- Strengthening learning ability of a CNN(increase gradient path)
- Removing computational bottlenecks(split 一半做原来的操作)
- Reducing memory costs(用 Convolutional Input/Output (CIO) 评价指标评估,见方法部分)
公开数据集上精度不掉,计算量降低
4 Cross Stage Partial Network
先看看原版的 DenseNet
详细分析可参考




-
f i f_i fi is the function of weight updating of i t h i^{th} ith dense layer,
-
g i g_i gi represents the gradient propagated to the i t h i^{th} ith dense layer

This will result in different dense layers repeatedly learn copied gradient information.(红框处梯度重复了)
再看看作者的改进版 Cross Stage Partial DenseNet


就是把原来的输入 split 成两条分支
x
0
=
[
x
0
′
,
x
0
′
′
]
x_0 = [x_0', x_0'']
x0=[x0′,x0′′]
分支一同 DenseNet(所以这里面还是存在梯度复用的情况)
分支二直接 Concat 分之一 transform 后的结果
再经一层 transform
保留 DenseNet 结构的同时,prevents an excessively amount of duplicate gradient information by truncating the gradient flow
both sides do not contain duplicate gradient information that belongs to other sides
4.1 Partial Dense Block
好处
- increase gradient path
- balance computation of each layer(降低 computational bottleneck,因为只有一半进行了 DenseNet block 中的操作)
- reduce memory traffic
前两个优点比较好理解,下面看看作者的这种设计是如何 Reducing memory traffic 的
作者是通过 CIO 评价指标来分析说明的
Convolutional Input/Output (CIO) which is an approximation of Dynamic Random-Access Memory (DRAM) traffic proportional to the real DRAM traffic measurement
计算公式如下
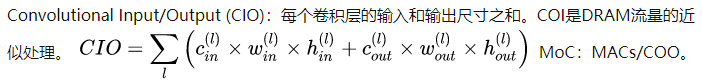
(截图来自 HarDNet简析)
1)原版 DenseNet 的 CIO
去掉 h 和 w
DenseNet block 中通道变化符合等差数列,公差为增长率
先回忆下等差数列的求和公式

m c + m ( m − 1 ) 2 d mc + \frac{m(m-1)}{2}d mc+2m(m−1)d
- m m m 为 total dense layer
- d d d 为 growth rate
- c c c 为输入特征图的 channels
哈哈哈,感觉论文呢中 m ( m + 1 ) m(m+1) m(m+1) 搞错了
2)再看看改进后的 Cross Stage Partial DenseNet 的 CIO
输入被 split 成两份
m c 2 + m ( m − 1 ) 2 d \frac{mc}{2} + \frac{m(m-1)}{2}d 2mc+2m(m−1)d
网络结构中 c c c 要远远大于 m m m 和 d d d,所以作者设计的这个 1 / 2 1/2 1/2 split 就能很大程度上降低 memory traffic
4.2 Partial Transition Layer
设计的目的是 maximize the difference of gradient combination(truncating the gradient flow to prevent distinct layers from learning duplicate gradient information)

fusion last 比 fusion first 要好,the gradient information will not be reused since the gradient flow is truncated
不同结构结果图如下

if one can effectively reduce the repeated gradient information, the learning ability of a network will be greatly improved.
4.3 Apply CSPNet to Other Architectures

4.4 Exact Fusion Model
CNN can be often distracted when it learns from image-level labels and concluded that it is one of the main reasons that two-stage object detectors outperform one-stage object detectors.


EFM assembles features from the three scales(图 6 c 只画了 2 个 scale 的 fusion)
为了 balance computation,作者 incorporate the Maxout technique to compress the feature maps
5 Experiments
5.1 Datasets
ImageNet
COCO
5.2 Ablation Experiments
1)Ablation study of CSPNet on ImageNet

γ
\gamma
γ 为 partial ratio,也即 Densenet 分支的比例(split 时候通道数的占比)
2)Ablation study of EFM on MS COCO

SAM 是 Spatial Attention Module
5.3 ImageNet Image Classification

效果相当,性能提升主要体现在计算量的减少上
5.4 MS COCO Object Detection

5.5 Analysis
1)Computational Bottleneck


看蓝色
2)Memory Traffic


看蓝色
6 Conclusion(own) / Future work
-
CIO 来自于 《HarDNet: A Low Memory Traffic Network》

-
the depth-wise convolution they adopted is usually not compatible with industrial IC design such as Application-Specific Integrated Circuit (ASIC) for edge-computing systems
-
Too high a computational bottleneck will result in more cycles to complete the inference process, or some arithmetic units will often idle.
-
DenseNet 梯度信息 reused 太严重(作者砍半),核心图是下面这张,transition 的位置也有讲究

-
在 yolov5 中的实现形式
class Bottleneck(nn.Module): # Standard bottleneck def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 def forward(self, x): return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x)) class BottleneckCSP(nn.Module): # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False) self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False) self.cv4 = Conv(2 * c_, c2, 1, 1) self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3) self.act = nn.SiLU() self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n))) def forward(self, x): y1 = self.cv3(self.m(self.cv1(x))) y2 = self.cv2(x) return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))















 1054
1054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









