






CSPNet
摘要
作者提出了跨阶段部分网络(CSPNet),以缓解以往工作需从网络架构的角度进行大量推理计算的问题。作者将此问题归因于网络优化中梯度信息的重复。所提出的网络通过集成网络阶段开始和结束的特征图来尊重梯度的可变性,在作者的实验中,在ImageNet数据集上以同等甚至更高的精度减少了20%的计算量,并且在MS COCO目标检测数据集上的AP50方面显著优于 SOTA
1.引言
设计CSPNet的主要目的是使该体系结构能够实现更丰富的梯度组合,同时减少计算量。这一目标是通过将基础层的特征图划分为两个部分,然后通过提出的跨阶段层次结构将它们合并来实现的。
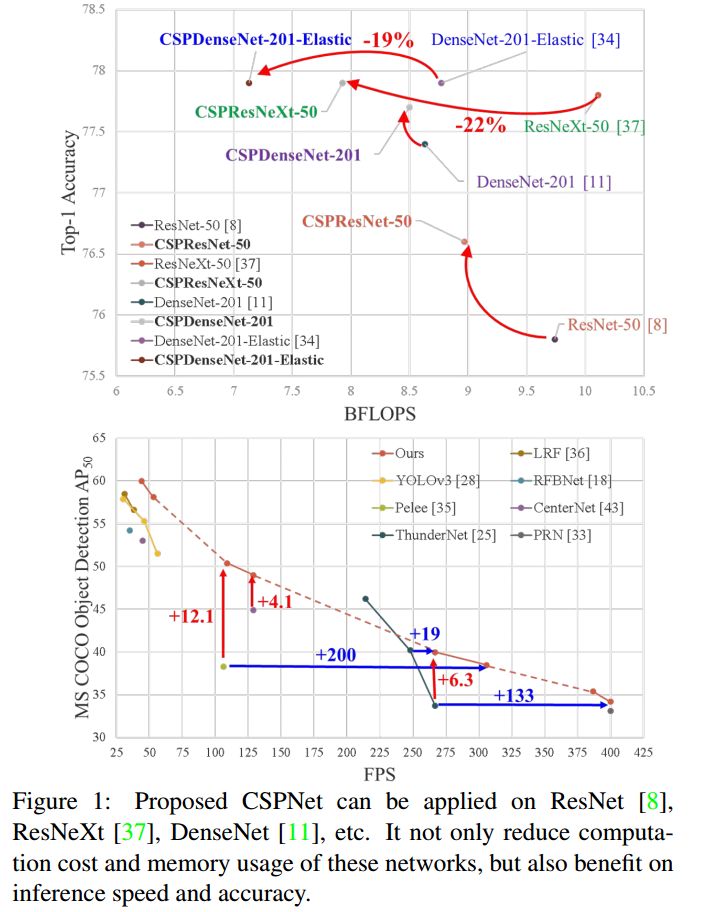
主要概念是通过拆分梯度流,使梯度流在不同的网络路径上传播。通过这种方式,作者证实了通过切换拼接 (switching concatenation) 和转换步骤 (transition steps),传播的梯度信息可以有很大的相关差异。此外,CSPNet 可以大大减少计算量,提高推理速度和精度,如图1所示。作者提出的基于cspnet的目标检测器解决了以下三个问题:
- 增强 CNN 的学习能力
所提出的CSPNet可以很容易地应用于ResNet、ResNeXt和DenseNet。在上述网络上应用CSPNet后,计算量可从10%减少到20%,但在ImageNet上进行图像分类任务时,其准确率优于ResNet、ResNeXt、DenseNet、HarDNet、Elastic和Res2Net - 消除计算瓶颈
- 降低存储成本
3.方法
3.1Cross Stage Partial Network
k k k 层 CNN 的输出可以表示为
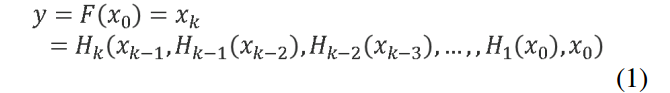
F
F
F 是输入
x
0
x_0
x0 到目标
y
y
y 的映射函数,也是整个 CNN 模型,
H
k
H_k
Hk 是 CNN 第
k
k
k 层的运算函数。通常,
H
k
H_k
Hk 由一组卷积层和一个非线性激活函数组成。以 ResNet 和 DenseNet 为例,分别用公式 2 和公式 3 表示,如下所示:
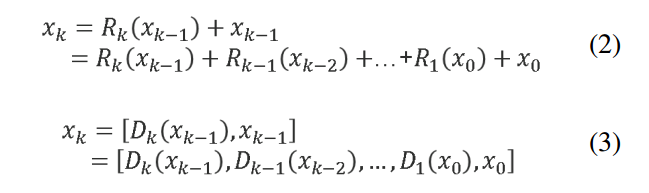
其中 R R R 和 D D D 分别代表残差层和 Dense Layer 的计算算子,这些算子通常由 2 ~ 3 个卷积层组成
在残差网络(ResNet)或密集网络(DenseNet)中,每个卷积层的输入都接收到前面所有层的输出(ResNet 是元素级加法,DenseNet 是通道维度 concatenation)。这种设计能够减少梯度路径的长度,从而在反向传播过程中使梯度流传播更加高效。然而,这种架构设计也会导致第 k k k 层将梯度传递给所有 k − 1 k-1 k−1、 k − 2 k-2 k−2、…、 1 1 1 层,并用这些梯度来更新权重,这样做会导致重复学习冗余的信息。
简单来说,虽然这种设计可以提高梯度传播的效率,但同时也带来了梯度信息的重复使用问题,这可能会导致网络学习效率降低,因为它在多个层之间重复利用相同的梯度信息来进行学习。
最近,一些研究尝试使用筛选后的 H k ( ⋅ ) H_k(\cdot) Hk(⋅) 输入来提高学习能力和参数利用率。
最先进的方法将重点放在优化每一层的 H i H_i Hi 函数上,作者建议 CSPNet 直接优化 F F F 函数如下:
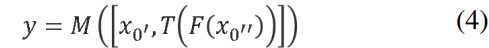
其中 x 0 x_0 x0 沿通道维度分割成两部分,可被表示为: x 0 = [ x 0 ′ , x 0 ′ ′ ] x_0 = [x_{0^{'}}, x_{0^{''}}] x0=[x0′,x0′′], T T T 是用于截断梯度流 H 1 H_1 H1, H 2 H_2 H2, … … …, H k H_k Hk 的转换函数(transition function)。
M M M 是用于混合两个被分割部分的转换函数(transition function)。接下来,作者展示如何将 CSPNet 集成到 DenseNet 中的示例,并解释如何解决 CNN 中重复信息的学习问题。
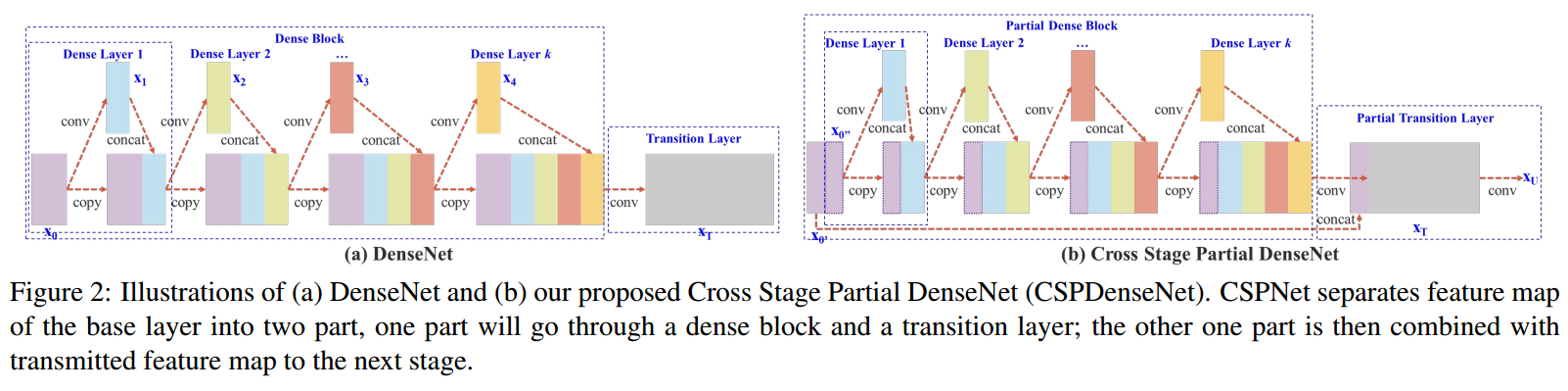
这张图展示了两种不同的神经网络架构的比较:传统的DenseNet(图a)和提出的Cross Stage Partial DenseNet(CSPDenseNet,图b)。
图 (a) DenseNet:
在DenseNet架构中,每一个Dense Layer(密集层)的输出不仅会被送入下一个层,而且会与之前所有层的输出进行连接(concat)。例如,在Dense Layer 1完成处理后,它的输出
x
1
x_1
x1 会被复制并与输入
x
0
x_0
x0 连接,作为Dense Layer 2的输入。这个过程在所有的Dense Layers中重复进行。这样,随着网络深度的增加,每个层都会积累越来越多的特征,直到在Transition Layer(转换层)中进行某种形式的维度缩减(通常是通过卷积操作)。
图 (b) Cross Stage Partial DenseNet(CSPDenseNet):
在CSPDenseNet架构中,输入特征图
x
0
x_0
x0 被分成两部分,其中一部分
x
0
′
x_0'
x0′ 直接传递到阶段 (stage) 的末尾,而另一部分
x
0
′
′
x_0''
x0′′ 则经过一系列的Dense Layers。在这些Dense Layers中,特征图依旧会进行复制和连接操作,但仅限于
x
0
′
′
x_0''
x0′′ 的部分。在经过了
k
k
k 个Dense Layers之后,这些处理过的特征图会与
x
0
′
x_0'
x0′ 进行连接,并通过一个Partial Transition Layer(部分转换层)进行特征整合和维度变换,输出
x
U
x_U
xU。
总的来说,CSPDenseNet通过在每个阶段初分割输入特征图,减少了冗余信息的传递,并试图通过这种方式平衡梯度流,提高网络学习的多样性,从而提高效率和减少计算资源的需求。这种结构对于在资源受限的设备上部署深度学习模型特别有价值。
DenseNet
DenseNet 的每个阶段(操作空间尺寸相同的特征图)包含一个密集块和一个过渡层,每个密集块由 k k k 个密集层(非线性映射层)组成。第 i i i 个密集层的输出将与第 i i i 个密集层的输入进行连接,连接后的结果将成为第 ( i + 1 ) (i + 1) (i+1) 个密集层的输入。表示上述机理的方程可表示为:
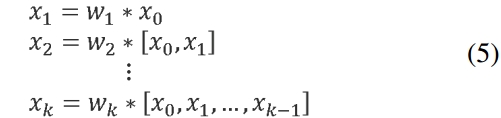
其中 ∗ * ∗ 表示卷积算子, [ x 0 , x 1 , … ] [x_0, x_1,…] [x0,x1,…] 表示连接(concatenation) x 0 , x 1 , … , x_0, x_1,…, x0,x1,…,
w i w_i wi 和 x i x_i xi 分别是第 i i i 个密集层的权值和输出。
如果利用反向传播来更新权值,则权值更新的方程可以写成:
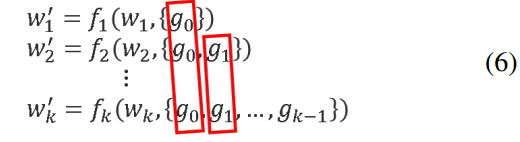
其中, f i f_i fi 为第 i i i 个密集层的权值更新函数, g i g_i gi 为传播到第 i i i 个密集层的梯度。可以发现,在更新不同密度层的权重时,大量的梯度信息被重用。这将导致不同的密集层反复学习复制的梯度信息。
在这里,每个 w k ′ w'_k wk′ 表示第 k k k 层之后的权重更新,而 f k f_k fk 是更新函数,它依赖于当前层的权重 w k w_k wk 和所有前面层的梯度信息 g 0 , g 1 , . . . , g k − 1 g_0, g_1, ..., g_{k-1} g0,g1,...,gk−1。
- w 1 ′ w'_1 w1′ 是第一层的权重更新,它只依赖于该层自身的权重 w 1 w_1 w1 和梯度 g 0 g_0 g0。
- w 2 ′ w'_2 w2′ 是第二层的权重更新,它依赖于第二层的权重 w 2 w_2 w2 和前两层的梯度信息 g 0 g_0 g0 和 g 1 g_1 g1。
- 依此类推,直到 w k ′ w'_k wk′,第 k k k 层的权重更新依赖于它自己的权重 w k w_k wk 和从第一层到第 k − 1 k-1 k−1 层的所有梯度信息。
这组方程强调了在传统的神经网络结构中,梯度在网络层间的流动方式。每一层在更新其权重时都会考虑到前面所有层的梯度,这可以在训练过程中带来一个问题:信息重复和冗余。由于每一层都重复地使用前面层的梯度信息,这可能会导致网络在学习过程中的效率降低,因为不同层可能会在更新权重时重复学习相同的信息。
在CSPNet中,这种梯度传递方式被修改,以减少重复的梯度流动,通过引入梯度的截断(truncating gradient flow)和特征图的分割,目的是减轻计算负担并提高学习效率。
为什么DenseNet在反向传播更新权重时,最后一层的权重更新会依赖所有之前层的梯度信息?
DenseNet的独特之处在于其层与层之间的连接方式。在DenseNet中,每一层的输出都会与前面所有层的输出连接起来,形成该层的输入。这意味着第 k k k 层的输入实际上包含了第 1 1 1 层到第 k − 1 k-1 k−1 层的所有特征图的信息。这种设计称为特征重用(feature reuse),它使得网络中的信息传递非常高效,同时减少了所需的训练参数数量。
然而,这种设计也意味着在反向传播过程中,最后一层的梯度计算将涉及到从第一层直到最后一层之前的所有层。每层的梯度不仅影响它自己的权重更新,还会影响所有后续层的权重更新。具体来说,最后一层的梯度是基于整个网络的损失值与该层输出的导数计算的,而因为该层的输入是所有之前层的输出的集合,它的梯度更新自然包含了前面所有层的梯度信息。当反向传播到达倒数第二层时,这一层的梯度更新同样会依赖于它自己的输出导数以及前面所有层的梯度信息,因为其输出也被最后一层用作输入之一。如此继续,直到网络的第一层。
简而言之,DenseNet中,每一层的梯度计算都依赖于前面所有层的输出,所以反向传播时,最后一层的权重更新会依赖所有之前层的梯度信息,这是因为所有层的特征都直接连接到最后一层,形成了它的输入。这种累积特征的设计让网络能够利用丰富的历史信息,从而在进行分类和回归任务时能够取得更好的性能。
Cross Stage Partial DenseNet
在 CSPDenseNet 中,一个阶段(stage)包括一个部分密集块(partial dense block)和一个部分转换层(partial transition layer)。
-
部分密集块:
- 在这个阶段的基础层(base layer)中,特征图(feature maps) x 0 x_0 x0 被沿着通道维度分为两个部分: x 0 ′ x_0' x0′ 和 x 0 ′ ′ x_0'' x0′′。
- x 0 ′ x_0' x0′ 是直接连接到这个阶段的末尾,不经过任何密集层(dense layers)的处理。
- x 0 ′ ′ x_0'' x0′′ 则会通过一系列的密集层进行处理。
-
部分转换层:
- 第一步,经过密集层处理的特征图 [ x 0 ′ ′ , x 1 , . . . , x k ] [x_0'', x_1, ..., x_k] [x0′′,x1,...,xk] 会经过一个转换层(DenseBlock每个stage自带的TransitionLayer)。
- 第二步,这个转换层的输出 x T x_T xT 会与未经过密集层处理的部分 x 0 ′ x_0' x0′ 进行连接(concatenation),然后再通过另一个转换层。
- 最终生成输出 x U x_U xU。
这个结构的设计允许网络在保持高效的特征传递和利用的同时,减少了在传统 DenseNet 中由于特征重用而可能导致的冗余计算。通过这种部分特征图的处理策略,CSPDenseNet 在前向传播和权重更新的过程中能够降低计算量,并且在实际应用中达到更快的推理速度和相似甚至更好的准确度。简言之,CSPDenseNet试图在密集的连接和计算效率之间找到一个平衡点。
CSPDenseNet 的前馈传递和权值更新方程分别如式 7 和式 8 所示:
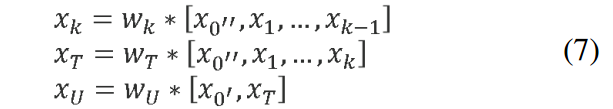
这组方程描述了CSPDenseNet中的前向传播过程,特别是在其中的一个“stage”里面。每个方程表示不同阶段的特征图(
x
k
x_k
xk、
x
T
x_T
xT、
x
U
x_U
xU)是如何通过各自的权重
W
W
W 和之前层的输出特征图进行计算的。
第一个方程 x k = W k ∗ [ x 0 ′ ′ , x 1 , . . . , x k − 1 ] x_k = W_k * [x_0'', x_1, ..., x_{k-1}] xk=Wk∗[x0′′,x1,...,xk−1]:
- x k x_k xk 是第 k k k 层的输出特征图。
- W k W_k Wk 是第 k k k 层的卷积核(或称为权重矩阵)。
- x 0 ′ ′ x_0'' x0′′ 是分割后进入密集块的特征图部分。
- [ x 0 ′ ′ , x 1 , . . . , x k − 1 ] [x_0'', x_1, ..., x_{k-1}] [x0′′,x1,...,xk−1] 表示将 x 0 ′ ′ x_0'' x0′′ 与之前所有层的输出特征图连接起来形成的向量。
- 星号 (*) 表示卷积操作,这里是将卷积核 W k W_k Wk 应用到连接后的特征图上。
第二个方程 x T = W T ∗ [ x 0 ′ ′ , x 1 , . . . , x k ] x_T = W_T * [x_0'', x_1, ..., x_k] xT=WT∗[x0′′,x1,...,xk]:
- x T x_T xT 是经过转换层后的输出特征图。
- W T W_T WT 是转换层的卷积核。
- [ x 0 ′ ′ , x 1 , . . . , x k ] [x_0'', x_1, ..., x_k] [x0′′,x1,...,xk] 表示将 x 0 ′ ′ x_0'' x0′′ 与当前所有密集层的输出连接起来形成的向量。
- 同样,这里的卷积操作是将卷积核 W T W_T WT 应用到连接后的特征图上。
第三个方程 x U = W U ∗ [ x 0 ′ , x T ] x_U = W_U * [x_0', x_T] xU=WU∗[x0′,xT]:
- x U x_U xU 是该阶段最终输出的特征图。
- W U W_U WU 是另一个转换层的卷积核。
- [ x 0 ′ , x T ] [x_0', x_T] [x0′,xT] 表示未经过密集块处理的特征图 x 0 ′ x_0' x0′ 与经过转换层的特征图 x T x_T xT 的连接。
- 这里卷积操作是将卷积核 W U W_U WU 应用到 x 0 ′ x_0' x0′ 和 x T x_T xT 连接后的特征图上。
整个过程反映了CSPDenseNet中的“部分”概念:特征图在经过不同阶段的处理后重新组合,而非在每一层都进行全部特征图的重用,从而减少了计算复杂度并增强了特征的多样性。这是CSPNet试图优化传统DenseNet中可能存在的冗余信息问题的方法。
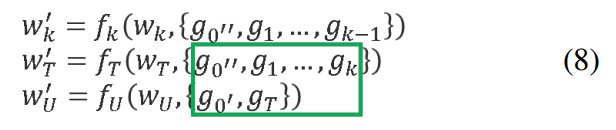
这组方程表示了在CSPDenseNet模型中,权重更新的具体过程。这些方程涉及到梯度下降优化过程中的权重更新,其中 f k f_k fk, f T f_T fT,和 f U f_U fU 表示不同层级的更新函数。这些更新函数依赖于各自层的权重和梯度。这些梯度是在反向传播过程中计算得到的。
第一个方程 w k ′ = f k ( W k , { g 0 ′ ′ , g 1 , . . . , g k − 1 } ) w'_k = f_k(W_k, \{g_0'', g_1, ..., g_{k-1}\}) wk′=fk(Wk,{g0′′,g1,...,gk−1}):
- w k ′ w'_k wk′ 是在第 k k k 层权重更新之后的权重。
- W k W_k Wk 是第 k k k 层在更新前的权重。
- g 0 ′ ′ , g 1 , . . . , g k − 1 g_0'', g_1, ..., g_{k-1} g0′′,g1,...,gk−1 是第 k k k 层及其之前所有层的梯度信息。
- 这表示第 k k k 层的权重更新是基于自己层的梯度信息和之前所有层的梯度信息。
第二个方程 w T ′ = f T ( W T , { g 0 ′ ′ , g 1 , . . . , g k } ) w'_T = f_T(W_T, \{g_0'', g_1, ..., g_k\}) wT′=fT(WT,{g0′′,g1,...,gk}):
- w T ′ w'_T wT′ 是转换层(Transition Layer)权重更新后的权重。
- W T W_T WT 是转换层在更新前的权重。
- g 0 ′ ′ , g 1 , . . . , g k g_0'', g_1, ..., g_k g0′′,g1,...,gk 表示的是包括转换层在内及其之前所有层的梯度信息。
第三个方程 w U ′ = f U ( W U , { g 0 ′ , g T } ) w'_U = f_U(W_U, \{g_0', g_T\}) wU′=fU(WU,{g0′,gT}):
- w U ′ w'_U wU′ 是另一个转换层(可能是最终输出层)更新后的权重。
- W U W_U WU 是这一层在更新前的权重。
- g 0 ′ , g T g_0', g_T g0′,gT 分别代表经过部分Dense Block的特征图的梯度和经过第一个转换层后的特征图的梯度。
方括号内的梯度 { } \{ \} {} 表示权重更新取决于一系列梯度的集合,这是因为在CSPDenseNet中,某一层的输出是基于通过特定路径传递过来的梯度信息。绿色框起来的梯度表示它们是在反向传播时计算并用于当前权重更新的依据。
整体来看,这组方程描述了CSPDenseNet中不同阶段权重更新所依赖的梯度信息,强调了CSPDenseNet在权重更新时如何利用梯度流的截断来减少计算量并提高效率。这与传统DenseNet相比,在权重更新时尝试减少重复和不必要的梯度信息的利用,以提高训练效率和模型性能。
Partial Dense Block
设计部分密集块(partial dense blocks)的三个优点:
-
增加梯度路径:通过分割(split)和合并(merge)策略,梯度路径的数量可以加倍。这是因为跨阶段(cross-stage)策略避免了显式地复制特征图进行连接(concatenation),这样可以缓解因为特征复制带来的不利影响。
-
平衡每层的计算量:通常情况下,DenseNet中基础层的通道数要远大于增长率。在部分密集块中,参与密集层运算的基础层通道只有原始数量的一半,这可以有效地解决几乎一半的计算瓶颈问题。也就是说,通过减少参与后续计算的通道数量,可以减轻网络的计算负担。
-
减少内存流量:假设DenseNet中一个密集块的基础特征图大小为 w × h × c w × h × c w×h×c,增长率为 d d d,总共有 m m m 个密集层。那么该密集块的 CIO \text{CIO} CIO(Convolutional Input/Output,一种衡量内存流量的指标)计算公式为 ( c × m ) + ( ( m 2 + m ) × d ) / 2 (c × m) + ((m^2 + m) × d)/2 (c×m)+((m2+m)×d)/2。而部分密集块的 CIO \text{CIO} CIO 计算公式为 ( ( c × m ) + ( m 2 + m ) × d ) / 2 ((c × m) + (m^2 + m) × d)/2 ((c×m)+(m2+m)×d)/2。因为 m m m 和 d d d 通常远小于 c c c,部分密集块能够至多节省一半的网络内存流量。这里的节省来源于特征图在传递到下一层之前进行了一次压缩,降低了存储和传输的开销。
总体来说,CSPDenseNet 通过在结构中引入部分密集块,旨在提高模型的训练效率和推理速度,同时减少对资源的需求,这对于希望在硬件资源有限的设备上运行复杂模型的情景特别有价值。
Partial Transition Layer
设计部分转换层(partial transition layers)的目的是为了最大化梯度组合的差异性。部分转换层是一种层级特征融合机制,通过截断梯度流的策略来防止不同层学习到重复的梯度信息。这里,作者提出了CSPDenseNet的两种变体来展示这种梯度流截断是如何影响网络学习能力的。
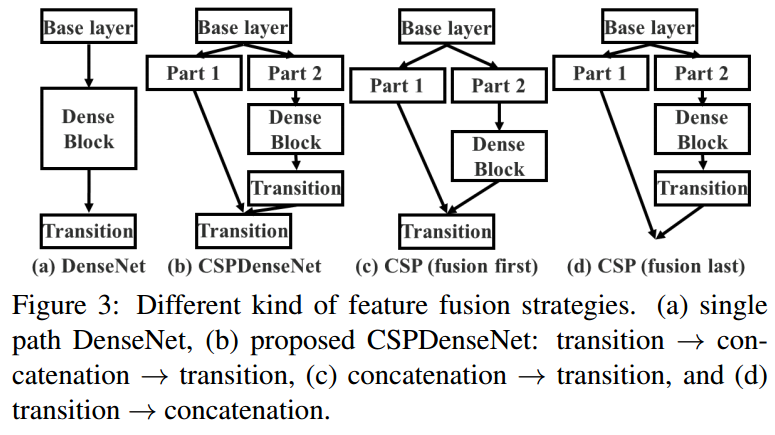
在图3中的(c)和(d),展示了两种不同的特征融合策略:
- CSP(fusion first,先融合策略)是指先将由两个部分生成的特征图进行连接(concatenate),然后执行转换操作。采用这种策略会重用大量的梯度信息。
- CSP(fusion last,后融合策略)则是先将来自密集块的输出通过转换层,然后与来自部分1的特征图进行连接。采用后融合策略时,梯度信息不会被重用,因为梯度流被截断了。
通过使用图3中展示的四种架构进行图像分类,可以在图4中看到相应的结果。结果显示,如果采用CSP(fusion last,后融合策略)进行图像分类,计算成本显著降低,而top-1精度只下降了0.1%。这表明CSP(fusion last)策略在减少计算成本的同时,几乎不损失准确性,这对于计算资源受限的环境非常有利。简而言之,这种设计有效地平衡了计算效率和模型性能。
(图3)展示了不同的特征融合策略。每个小图展示的是如何在神经网络的某一层或阶段内部处理和融合特征图。这是为了改善网络在处理图像时的信息流动和减少计算复杂度。
(a) DenseNet:
这是传统的DenseNet的示意图,特征图通过Dense Block(密集块)和Transition Layer(过渡层)进行处理。在Dense Block中,每一层的输出都会与前面所有层的输出进行连接(concatenation),然后再传递到下一层。
(b) CSPDenseNet(提出的Cross Stage Partial DenseNet):
在这个结构中,Base Layer(基础层)的特征图被分成两个部分。Part 1(部分1)直接通过Transition Layer(过渡层),而Part 2(部分2)通过Dense Block和Transition Layer。然后,这两部分的特征图再进行融合(concatenation),这样的设计可以降低重复信息的学习。
© CSP (fusion first)(CSP中的先融合策略):
在这个变体中,Base Layer的特征图被分成两个部分,两部分都先经过自己的Dense Block,然后进行融合,再一起通过Transition Layer。这种方式先做连接操作,然后再统一做特征图的转换。
(d) CSP (fusion last)(CSP中的后融合策略):
与©相反,这种策略先将Part 2通过Dense Block和Transition Layer,然后再与Part 1融合。这样做的目的是先对Part 2的特征进行处理和降维,然后再与Part 1结合,可能有助于减少在Transition Layer中的计算负担。
每种策略的选择都与特定的网络设计目标相关联,如减少计算复杂度、减轻内存占用、增强模型的特征学习能力等。通过不同的特征融合策略,作者试图找到一个平衡点,既可以保持网络性能,又可以减少资源消耗。
另一方面,CSP(融合优先)策略确实有助于计算成本的大幅下降,但top-1准确率大幅下降了1.5%。 通过跨阶段的拆分和合并策略,能够有效地减少信息集成过程中重复的可能性。 从图4所示的结果可以明显看出,如果能够有效减少重复的梯度信息,网络的学习能力将得到极大的提高。
“fusion first”和“fusion last”的区别
在CSPNet论文中,作者提到了两种不同的特征融合策略,即“fusion first”和“fusion last”。这两种策略描述的是在构建网络时如何处理和融合来自前面层的特征图(feature maps)。这些策略直接影响了梯度如何在网络中流动和传播,从而影响网络学习的方式。
-
Fusion First(先融合):
- 在这种策略中,特征图的融合发生在执行转换层操作之前。
- 具体来说,网络的两个分支输出(比如CSPNet中的两部分特征图)首先进行连接操作,合并成一个单一的特征图。
- 然后,这个融合后的特征图被送入转换层(transition layer),在这里可以进行卷积、批归一化、激活函数等操作。
- 这种方式会重用大量的梯度信息,因为所有的特征图在合并之前都已经参与了梯度的计算。
-
Fusion Last(后融合):
- 在“fusion last”策略中,转换层的操作发生在特征图融合之前。
- 这意味着网络的每个分支先独立通过各自的转换层。
- 之后,各分支的输出特征图再进行连接操作。
- 这种方法有助于减少梯度重用,因为每个分支的梯度在合并之前是独立计算的。
论文中指出,采用“fusion last”策略(后融合)相较于“fusion first”(先融合),能够显著减少计算成本,并且对精度影响甚微。这是因为“fusion last”策略通过在融合之前截断梯度流,减少了冗余的梯度传播,从而降低了计算量,这对于优化计算资源非常重要,尤其是在有限资源的设备上。
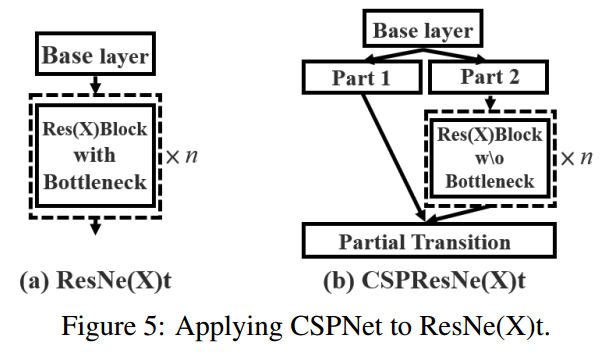
Apply CSPNet to Other Architectures
CSPNet也可以应用于ResNet和ResNeXt,架构如图5所示。由于只有一半的特征通道通过Res(X)块,因此不再需要引入瓶颈层 (bottleneck layer)。
3.2 Exact Fusion Model
Looking Exactly to predict perfectly
Aggregate Feature Pyramid
Balance Computation
5. 结论
作者提出了 CSPNet,它使 ResNet、ResNeXT 和 DenseNet 等最先进的方法能够针对移动 GPU 或 CPU 实现轻量级。 主要贡献之一是作者已经认识到冗余梯度信息问题会导致低效的优化和昂贵的推理计算。 作者提出利用跨阶段特征融合策略和截断梯度流来增强不同层内学习特征的可变性。 此外,作者提出了EFM,它结合了Maxout操作来压缩从特征金字塔生成的特征图,这大大减少了所需的内存带宽,因此推理效率足以与边缘计算设备兼容。 实验表明,所提出的带有 EFM 的 CSPNet 在移动 GPU 和 CPU 上用于实时目标检测任务的准确性和推理率方面显着优于竞争对手。
CSPDenseNet 核心代码实现
import torch
from torch import Tensor
from typing import List
from collections import OrderedDict
from torch import nn
import torch.utils.checkpoint as cp
import torch.nn.functional as F
class _Transition(nn.Sequential):
def __init__(self,
num_input_features: int,
num_output_features: int):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_features))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_features,
num_output_features,
kernel_size=1,
stride=1,
bias=False))
self.add_module("pool", nn.AvgPool2d(kernel_size=2, stride=2))
class _DenseLayer(nn.Module):
"""DenseBlock中的内部结构 DenseLayer: BN + ReLU + Conv(1x1) + BN + ReLU + Conv(3x3)"""
def __init__(self,
num_input_features: int,
growth_rate: int,
bn_size: int,
drop_rate: float,
memory_efficient: bool = False):
"""
:param input_c: 输入channel
:param growth_rate: 论文中的 k = 32
:param bn_size: 1x1卷积的filternum = bn_size * k 通常bn_size=4
:param drop_rate: dropout 失活率
:param memory_efficient: Memory-efficient版的densenet 默认是不使用的
"""
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(in_channels=num_input_features,
out_channels=bn_size * growth_rate,
kernel_size=1,
stride=1,
bias=False))
self.add_module("norm2", nn.BatchNorm2d(bn_size * growth_rate))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(bn_size * growth_rate,
growth_rate,
kernel_size=3,
stride=1,
padding=1,
bias=False))
self.drop_rate = drop_rate
self.memory_efficient = memory_efficient
def bn_function(self, inputs: List[Tensor]) -> Tensor:
# 第一个DenseBlock inputs: 最后会生成 [16,32,56,56](输入) + [16,32,56,56]*5
# concat_features=6个List的shape分别是: [16,32,56,56](输入)、[16,32,56,56]、[16,64,56,56]、[16,96,56,56]、[16,128,56,56]、[16,160,56,56]、[16,192,56,56]
concat_features = torch.cat(inputs, 1) # 该DenseBlock的每一个DenseLayer的输入都是这个DenseLayer之前所有DenseLayer的输出再concat
# 之后的DenseBlock中的append会将每一个之前层输入加入inputs 但是这个concat并不是把所有的Dense Layer层直接concat到一起
# 注意:这个concat和之后的DenseBlock中的concat非常重要,理解这两句就能理解DenseNet中密集连接的精髓
bottleneck_output = self.conv1(self.relu1(self.norm1(concat_features))) # 一直是[16,128,56,56]
return bottleneck_output
@staticmethod
def any_requires_grad(inputs: List[Tensor]) -> bool:
"""判断是否需要更新梯度(training)"""
for tensor in inputs:
if tensor.requires_grad:
return True
return False
@torch.jit.unused
def call_checkpoint_bottleneck(self, inputs: List[Tensor]) -> Tensor:
"""
torch.utils.checkpoint: 用计算换内存(节省内存)。 详情可看: https://arxiv.org/abs/1707.06990
torch.utils.checkpoint并不保存中间激活值,而是在反向传播时重新计算它们。 它可以应用于模型的任何部分。
具体而言,在前向传递中,function将以torch.no_grad()的方式运行,即不存储中间激活值 相反,前向传递将保存输入元组和function参数。
在反向传播时,检索保存的输入和function参数,然后再次对函数进行正向计算,现在跟踪中间激活值,然后使用这些激活值计算梯度。
"""
def closure(*inp):
return self.bn_function(inp)
return cp.checkpoint(closure, *inputs)
def forward(self, inputs: Tensor) -> Tensor:
if isinstance(inputs, Tensor): # 确保inputs的格式满足要求
prev_features = [inputs]
else:
prev_features = inputs
# 判断是否使用memory_efficient的densenet and 是否需要更新梯度(training)
# torch.utils.checkpoint不适用于torch.autograd.grad(),而仅适用于torch.autograd.backward()
if self.memory_efficient and self.any_requires_grad(prev_features):
# torch.jit 模式下不合适用memory_efficient
if torch.jit.is_scripting():
raise Exception("memory efficient not supported in JIT")
# 调用efficient densenet 思路:用计算换显存
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
# 调用普通的densenet 永远是[16,128,56,56]
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output))) # 永远是[16,32,56,56]
if self.drop_rate > 0:
new_features = F.dropout(new_features,
p=self.drop_rate,
training=self.training)
return new_features
class _Csp_Transition(torch.nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Csp_Transition, self).__init__()
self.add_module('norm', torch.nn.BatchNorm2d(num_input_features))
self.add_module('relu', torch.nn.ReLU(inplace=True))
self.add_module('conv', torch.nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False))
class _Csp_DenseBlock(torch.nn.Module):
def __init__(self,
num_layers,
num_input_features,
bn_size,
growth_rate,
drop_rate,
memory_efficient=False,
transition=False):
"""
:param num_layers: 当前DenseBlock的Dense Layer的个数
:param num_input_features: 该DenseBlock的输入Channel,开始会进行拆分,最后concat 每经过一个DenseBlock都会进行叠加
叠加方式:num_features = num_features // 2 + num_layers * growth_rate // 2
:param bn_size: 1x1卷积的filternum = bn_size*k 通常bn_size=4
:param growth_rate: 指的是论文中的k 小点比较好 论文中是32
:param drop_rate: dropout rate after each dense layer
:param memory_efficient: If True, uses checkpointing. Much more memory efficient
:param transition: 分支需不需Transition(csp transition) stand/fusionlast=True fusionfirst=False
"""
super(_Csp_DenseBlock, self).__init__()
self.csp_num_features1 = num_input_features // 2 # 平均分成两部分 第一部分直接传到后面concat
self.csp_num_features2 = num_input_features - self.csp_num_features1 # 第二部分进行正常卷积等操作
trans_in_features = num_layers * growth_rate
for i in range(num_layers):
layer = _DenseLayer(
num_input_features=self.csp_num_features2 + i * growth_rate, # 每生成一个DenseLayer channel增加growth_rate
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module('denselayer%d' % (i + 1), layer)
self.transition = _Csp_Transition(trans_in_features, trans_in_features // 2) if transition else None
def forward(self, x):
# x = [B, C, H, W] [batch,channel,height,weight]
# 拆分channel, 每次只用一半的channel(csp_num_features1)会继续进行卷积等操作 另一半(csp_num_features2)直接传到当前DenseBlock最后进行concat
features = [x[:, self.csp_num_features1:, ...]] # [16,32,56,56](输入) [16,32,56,56]*6
for name, layer in self.named_children():
if 'denselayer' in name: # 遍历所有denselayer层
# new_feature: 永远是[16,32,56,56]
new_feature = layer(features)
features.append(new_feature)
dense = torch.cat(features[1:], 1) # 第0个是上一DenseBlock的输入,所以不用concat
# 到这里分支DenseBlock结束
if self.transition is not None:
dense = self.transition(dense) # 进行分支(csp transition)Transition
return torch.cat([x[:, :self.csp_num_features1, ...], dense], 1)
class Csp_DenseNet(torch.nn.Module):
def __init__(self,
growth_rate=32,
block_config=(6, 12, 24, 16),
num_init_features=64,
transitionBlock=True,
transitionDense=False,
bn_size=4,
drop_rate=0,
num_classes=1000,
memory_efficient=False):
"""
:param growth_rate: DenseNet论文中的k 通常k=32
:param block_config: 每个DenseBlock中Dense Layer的个数 121=>(6, 12, 24, 16)
:param num_init_features: 模型第一个卷积层(Dense Block之前的唯一一个卷积)Conv0 的channel = 64
:param transitionBlock: 分支需不需要Transition transitionDense: 主路需不需要transition
transitionBlock=True + transitionDense=True => stand
transitionBlock=False + transitionDense=True => fusionfirst
transitionBlock=True + transitionDense=False => fusionlast
:param bn_size: 1x1卷积的filternum = bn_size*k 通常bn_size=4
:param drop_rate: dropout rate after each dense layer 默认为0 不用的
:param num_classes: 数据集类别数
:param memory_efficient: If True, uses checkpointing. Much more memory efficient 默认为False
"""
super(Csp_DenseNet, self).__init__()
self.growth_down_rate = 2 if transitionBlock else 1 # growth_down_rate这个变量好像没用到
self.features = torch.nn.Sequential(OrderedDict([
('conv0', torch.nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', torch.nn.BatchNorm2d(num_init_features)),
('relu0', torch.nn.ReLU(inplace=True)),
('pool0', torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]))
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _Csp_DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
transition=transitionBlock
)
self.features.add_module('denseblock%d' % (i + 1), block)
# 每执行了一个Dense Block就要对下一个Dense Block的输入进行更新(channel进行了叠加)
# 这里num_features变换是代码的最核心的部分
# num_features:每个DenseBlock的输出
# 如果支路用了transition: num_features=(上一个DenseBlock输出//2 + num_layers * growth_rate) // 2
# 因为只要经过transition输出都会变为原来的一半
# 如果支路没有用transition: num_features=上一个DenseBlock输出//2 + num_layers * growth_rate
num_features = num_features // 2 + num_layers * growth_rate // 2 if transitionBlock \
else num_features // 2 + num_layers * growth_rate
# 主路需不需要transition(常见的DenseNet的那种transition)
if (i != len(block_config) - 1) and transitionDense:
trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_features // 2
self.features.add_module('norm5', torch.nn.BatchNorm2d(num_features))
self.classifier = torch.nn.Linear(num_features, num_classes)
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight)
elif isinstance(m, torch.nn.BatchNorm2d):
torch.nn.init.constant_(m.weight, 1)
torch.nn.init.constant_(m.bias, 0)
elif isinstance(m, torch.nn.Linear):
torch.nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = torch.nn.functional.relu(features, inplace=True)
out = torch.nn.functional.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
def _csp_densenet(growth_rate, block_config, num_init_features, model='fusionlast', **kwargs):
"""
:param growth_rate: DenseNet论文中的k 通常k=32
:param block_config: 每个DenseBlock中Dense Layer的个数 121=>(6, 12, 24, 16)
:param num_init_features: 模型第一个卷积层(Dense Block之前的唯一一个卷积)Conv0 的channel
:param model: 模型类型 有stand、fusionfirst、fusionlast三种
:param **kwargs: 不定长参数 通常会传入 num_classes
transitionBlock: 分支需不需要Transition transitionDense: 主路需不需要transition
transitionBlock=True + transitionDense=True => stand
transitionBlock=False + transitionDense=True => fusionfirst
transitionBlock=True + transitionDense=False => fusionlast
"""
if model == 'stand':
return Csp_DenseNet(growth_rate, block_config, num_init_features,
transitionBlock=True, transitionDense=True, **kwargs)
if model == 'fusionfirst':
return Csp_DenseNet(growth_rate, block_config, num_init_features,
transitionBlock=False, transitionDense=True, **kwargs)
if model == 'fusionlast':
return Csp_DenseNet(growth_rate, block_config, num_init_features,
transitionBlock=True, transitionDense=False, **kwargs)
raise ('please input right model keyword')
def csp_densenet121(growth_rate=32, block_config=(6, 12, 24, 16),
num_init_features=64, model='fusionlast', **kwargs):
return _csp_densenet(growth_rate, block_config, num_init_features, model=model, **kwargs)
def csp_densenet161(growth_rate=48, block_config=(6, 12, 36, 24),
num_init_features=96, model='fusionlast', **kwargs):
return _csp_densenet(growth_rate, block_config, num_init_features, model=model, **kwargs)
def csp_densenet169(growth_rate=32, block_config=(6, 12, 32, 32),
num_init_features=64, model='fusionlast', **kwargs):
return _csp_densenet(growth_rate, block_config, num_init_features, model=model, **kwargs)
def csp_densenet201(growth_rate=32, block_config=(6, 12, 48, 32),
num_init_features=64, model='fusionlast', **kwargs):
return _csp_densenet(growth_rate, block_config, num_init_features, model=model, **kwargs)
if __name__ == '__main__':
"""测试模型"""
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 可以输入变量model='stand/fusionfirst/fusionlast(默认)'自己选择三种模型
model = csp_densenet121(num_classes=5, model='fusionlast')
print(model)














 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









