









 CSPNet是一种新型网络结构,旨在优化含ShortCut结构的网络,如DenseNet和ResNet,通过改善梯度信息重复利用减少计算量。在ImageNet和MSCOCO数据集上表现出优秀的性能。
CSPNet是一种新型网络结构,旨在优化含ShortCut结构的网络,如DenseNet和ResNet,通过改善梯度信息重复利用减少计算量。在ImageNet和MSCOCO数据集上表现出优秀的性能。
论文地址:https://arxiv.org/abs/1911.11929
代码地址:https://github.com/WongKinYiu/CrossStagePartialNetworks.
论文总结
本文的目的旨在优化之前含有ShortCut结构的网络,比如DenseNet和ResNet。其围绕的中心思想是网络优化中的重复梯度信息,以此来优化之前网络中所需要的大量推理计算问题。最后,优化的网络结构在ImageNet和MS COCO上都有好的结果。因此可以初步认为具有足够的泛化能力。
论文介绍
设计CSPNet的主要目的是使这个体系结构能够实现更丰富的梯度组合,同时减少计算量。换句话说,就是既希望能有更好的模型表达能力,又希望能减少模型计算消耗。
作者认为,所提出的基于CSPNet的目标检测模型解决了如下三个问题:(1)强化了CNN的学习能力。所提出的CSPNet可简单地被应用在ResNet、ResNextXt和DenseNet中,计算量可减少
10
10
10% ~
20
20
20%;(2)移除计算瓶颈层。太高的计算瓶颈将会需要更多的周期来完成推理过程。作者像均分CNN各层,从而提高每个计算单元的利用率,从而减少不必要的能量消耗。比如在Yolov3上,就能减少
80
80
80%的计算瓶颈;(3)减少内存占用。作者在特征金字塔生成的过程中,通过跨通道池化的操作来压缩特征映射所需要的计算消耗。
CSPNet特征金字塔过程如下:

在算法性能上,本文方法,在1080ti上,达到了 109 109 109FPS – 50 50 50%的COCO A P 50 AP_{50} AP50;在Intel Core i9-9900K上,达到了 52 52 52FPS – 40 40 40%的COCO A P 50 AP_{50} AP50;在嵌入式GPU Nvidia Jetson Tx2上,达到了 49 49 49FPS – 42 42 42%的COCO A P 50 AP_{50} AP50。
算法细节
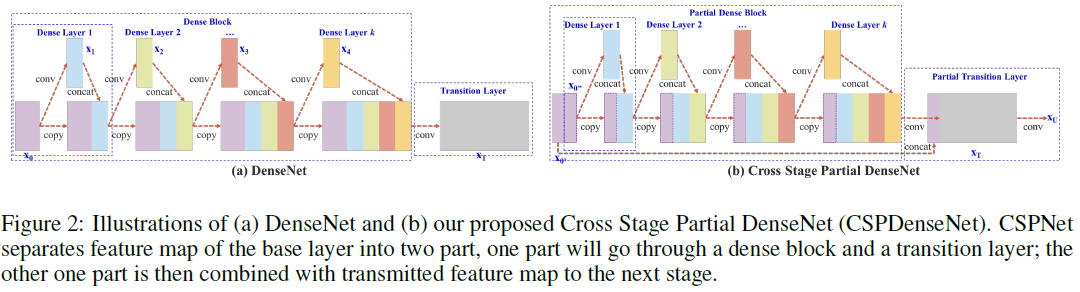
进行Concat的方式,有下图几种。本文所提出的 Transition Layer,过渡层,实际上也就是一组 1 ∗ 1 1*1 1∗1卷积,用于减少歧义性,使其更能融合。下图(c)的方式,会让大量的梯度信息被重复利用,有利于学习;下图(d)的方式,梯度流被阻断,不能复用梯度信息。但由于Transition层的输入通道比 (c)要少,因此能大大减少计算复杂度。本文采用的( b )就是结合了(c)和(d)的优点。
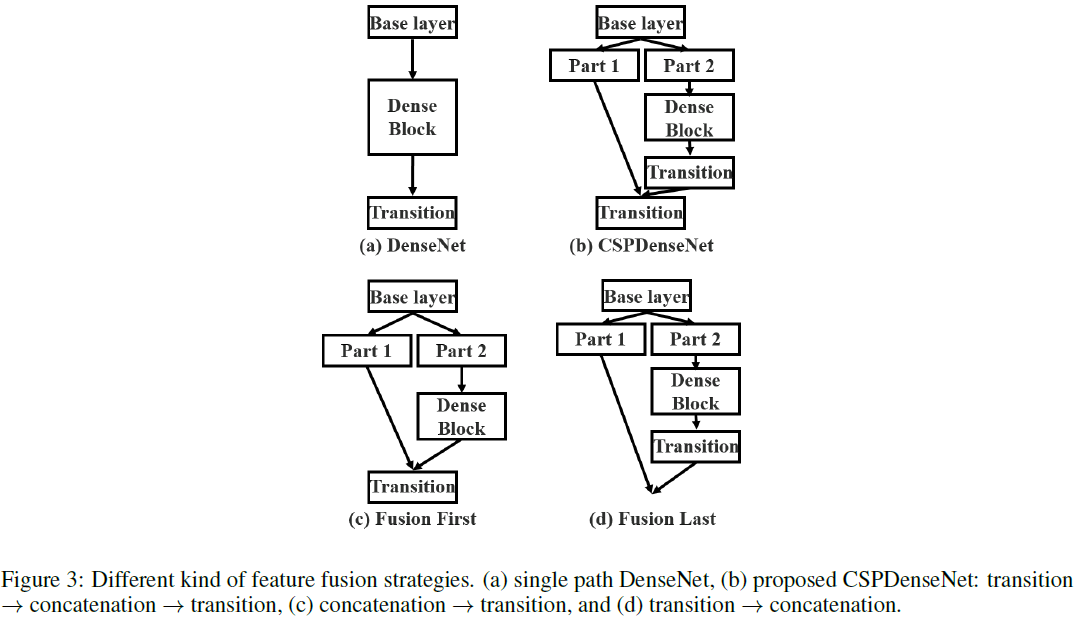
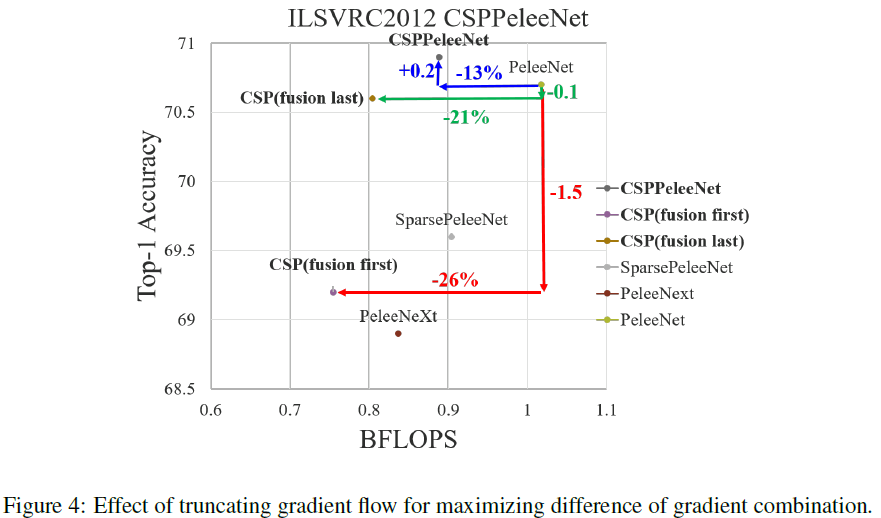
各种Concat融合特征的方式的结果如下图所示:若采用Fusion Last的方式与分类任务中,计算耗费巨大,但只损失 1 1 1%的 top-1 精度;而若采用Fusion First的方式,会损失 1.5 1.5 1.5% 的 top-1 精度,但能够减少计算耗费。
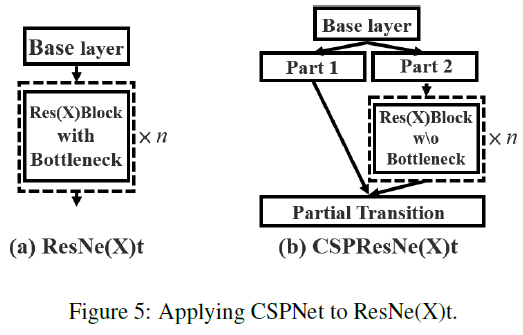
CSPResNet
对于ResNet的改造,如下图所示:但实际应用时(源码中查看),并不如下图所展示的一般分为Part1和Part2两个分开的channel,而是两个分支都包含全部的channel,再分别通过 1 ∗ 1 1*1 1∗1卷积,分别得到 1 2 \frac12 21的output channel。而Part2的分支经过 1 ∗ 1 1*1 1∗1卷积后,再通过没有BottleNect的ResNet Block, 1 ∗ 1 1*1 1∗1卷积后才得到该分支的输出。即两组分支在进行Concat前,分别进行了 1 ∗ 1 1*1 1∗1卷积的作用。
CSPResNet的cfg结构可视化如下图所示:在一个stage中stride=2的卷积,提前放在了前面进行。
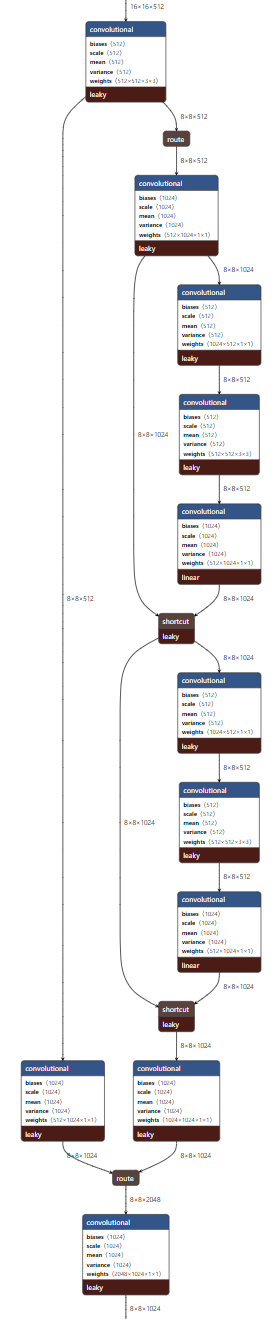
特征融合
在设计特征融合方式的时候,作者也做了独特的设计,如下图所示:基本可以认为是多阶段的特征融合,这也是比较常见的。值得特别说的就是,不同stage的下采样融合时,采用的是pooling,而不是卷积,用以压缩特征映射所需要的操作。该模块被称为EFM。
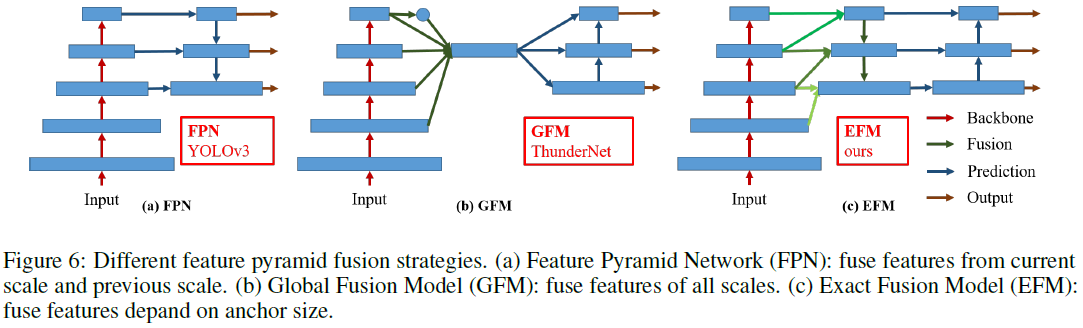
论文实验
作者在ImageNet分类数据集上验证CSPNet,然后在MS COCO数据集上验证EFM。
网络细节
ImageNet。在分类任务上,所有的超参数,比如训练steps,学习率lr,学习率方案lr schedule,优化器,数据增强等都和Yolov3论文中的设定一样。对于ResNet-based和ResNeXt-based的模型,设定 8 , 000 , 000 8,000,000 8,000,000个训练steps。对于DenseNet-based的模型,设定 1 , 600 , 000 1,600,000 1,600,000个训练steps。设定初始化学习率为 0.1 0.1 0.1,多项式衰减学习率,动量和权重衰减设为 0.9 0.9 0.9和 0.005 0.005 0.005。所有的架构都使用一个GPU,batch size设置为 128 128 128。
MS COCO。在目标检测任务上,所有的超参数都和Yolov3论文中一样。总共使用 500 , 000 500,000 500,000个训练steps。采用衰减率为 0.1 0.1 0.1的学习率策略,分别在 400 , 000 400,000 400,000和 450 , 000 450,000 450,000个迭代时衰减。动量和权重衰减设为 0.9 0.9 0.9和 0.0005 0.0005 0.0005。所有的架构都都在一个GPU上,使用batch size为64的多尺度训练。
消融学习
在ImageNet的消融学习上,使用PeleeNet作为CSPNet实验的baseline。在划分channel时,使用不同的划分率 γ \gamma γ和不同的特征融合策略用于消融学习。下表展示了CSPNet的消融学习结果。下表中,SPeleeNet和PeleeNeXt分别引入了稀疏联合和group convolution。
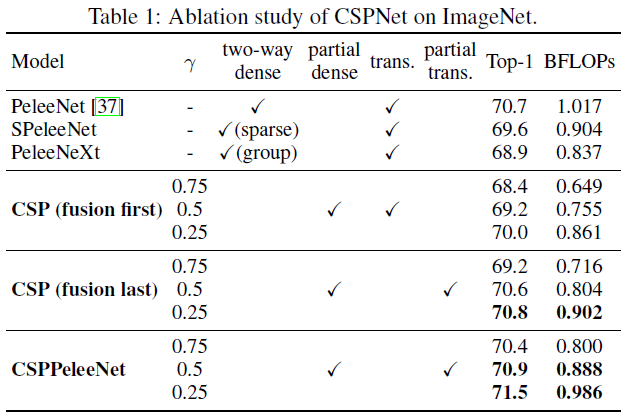
从实验结果看,如果只使用fusion first的CSP在CSP dense block中,CSPNet的表现要比SPeleeNet和PeleeNeXt要稍微好一些。但是,partial transition layer被设计去减少网络运行负担的同时可以达到好的效果。比如计算量减少 21 21 21%时,准确度只衰减 0.1 0.1 0.1%。需要被注意的是,当 γ = 0.25 \gamma=0.25 γ=0.25时,计算量减少 11 11 11%,但精确度增加了 0.1 0.1 0.1%。相较于baseline的PeleeNet,CSPPeleeNet获得了更好的性能。其减少了 13 13 13%的计算量,但增加了 0.2 0.2 0.2%的精确度。如果调整 γ = 0.25 \gamma=0.25 γ=0.25,可以使得CSPPeleeNet提升 0.8 0.8 0.8%的精确度,同时减少 3 3 3的计算量。
在MS COCO上对EFM的消融学习。对上面的三种特征融合方式(FPN/GFM/EFM)进行特征融合。在模型上,选择了两款轻量级模型ThunderNet和PRN进行比较。PRN是特征金字塔网络。作者设计了一个全局融合模型(GFM)和所提出的EFM进行比较。然后,使用GIoU,SPP和SAM应用在EFM上,进行消融学习。结果如下表所示。
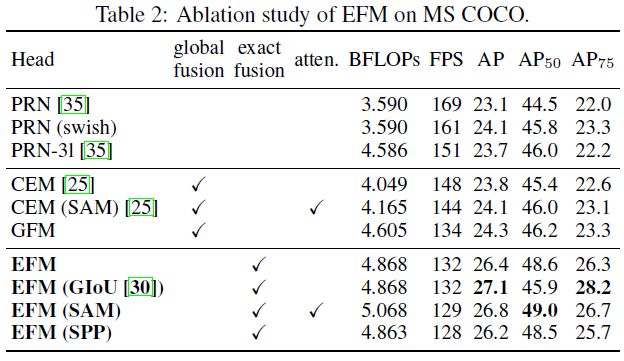
上面的结果显示:EFM比GFM慢了 2 2 2FPS,但 A P AP AP和 A P 50 AP_{50} AP50提升了 2.1 2.1 2.1%和 2.4 2.4 2.4%。尽管GIoU的使用可以将 A P AP AP提升 0.7 0.7 0.7%,但 A P 50 AP_{50} AP50却显著降低了 2.7 2.7 2.7%。然而,对于边缘计算来说,真正重要的是对象的数量和位置,而不是他们的坐标。因此,在后续模型中不会再使用GIoU用于训练。对比SPP这种增加感受野的机制,SAM使用attention机制可以得到更好的帧率和 A P AP AP,因此后面的架构使用EFM(SAM)。此外,CSPPeleeNet使用swish激活函数可以提高 A P 0.1 AP 0.1 AP0.1%。但这个算子需要在硬件设计上有一个查找表来加速,所以最终作者还是放弃了swish激活函数。
ImageNet分类任务
将CSPNet应用在ResNet-10,ResNeXt-50,PeleeNet和DenseNet–201-Elastic,与其他最先进的模型的比较结果,如下表所示。结果表示,不管是哪个引入的模型,引入CSPNet的概念后,计算负荷至少减少了10%,而精度要么不变,要么有所提高。
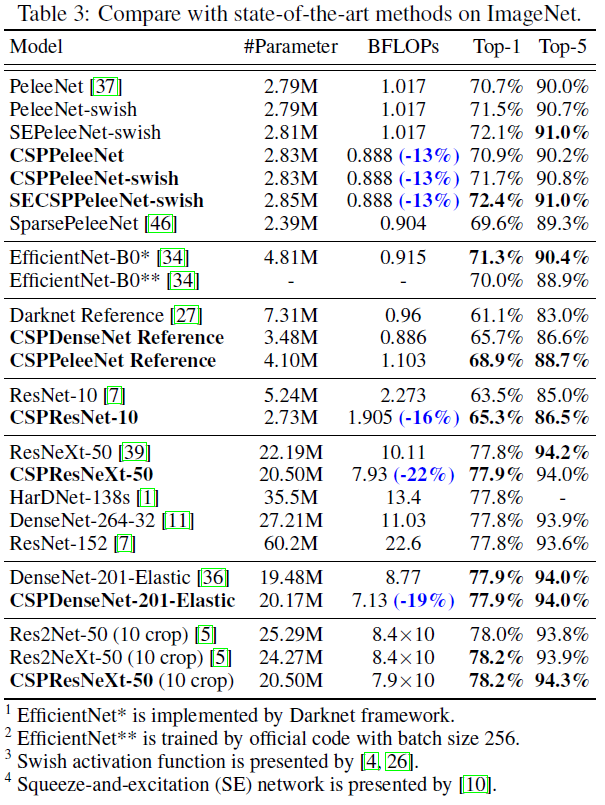
EfficientNet-B0中所使用的swish激活函数和SE block对于移动端CPU来说并不是十分有效率。这点在EfficientNet-EdgeTPU上也有相似的分析。EfficientNet-B0论文中的 76.8 76.8 76.8%精度,当batch size为2048。但在本文的实验中,和其他实验一样的配置,一个GPU,EfficientNet-B0只能达到 70.0 70.0 70.0%的精度。
但为了表示CSPNet的学习能能力,将swish激活函数和SE block放入CSPPeleeNet中,然后与EfficientNet-B0*作比较。上表展示,SECSPPeleeNet-swish减少了 3 3 3%的计算量,增加了 1.1 1.1 1.1%的top-1 精度。
与其他网络的比较,不管参数量,计算耗费等,CSPResNeXt-50都达到了最好的结果。
MS COCO目标检测
在目标检测任务上,针对三个场景:(1)GPU上实时,采用CSPResNeXt50和PANet(SPP);(2)移动GPU端上实时,采用CSPPeleeNet,CSPPeleeNet Reference和带着EFM(SAM)的CSPDenseNet Reference;(3)CPU上实时,采用CSPPeleeNet Reference和带着PRN的CSPDenseNet Reference。下表中展示了上述模型和最先进方法之间的比较。
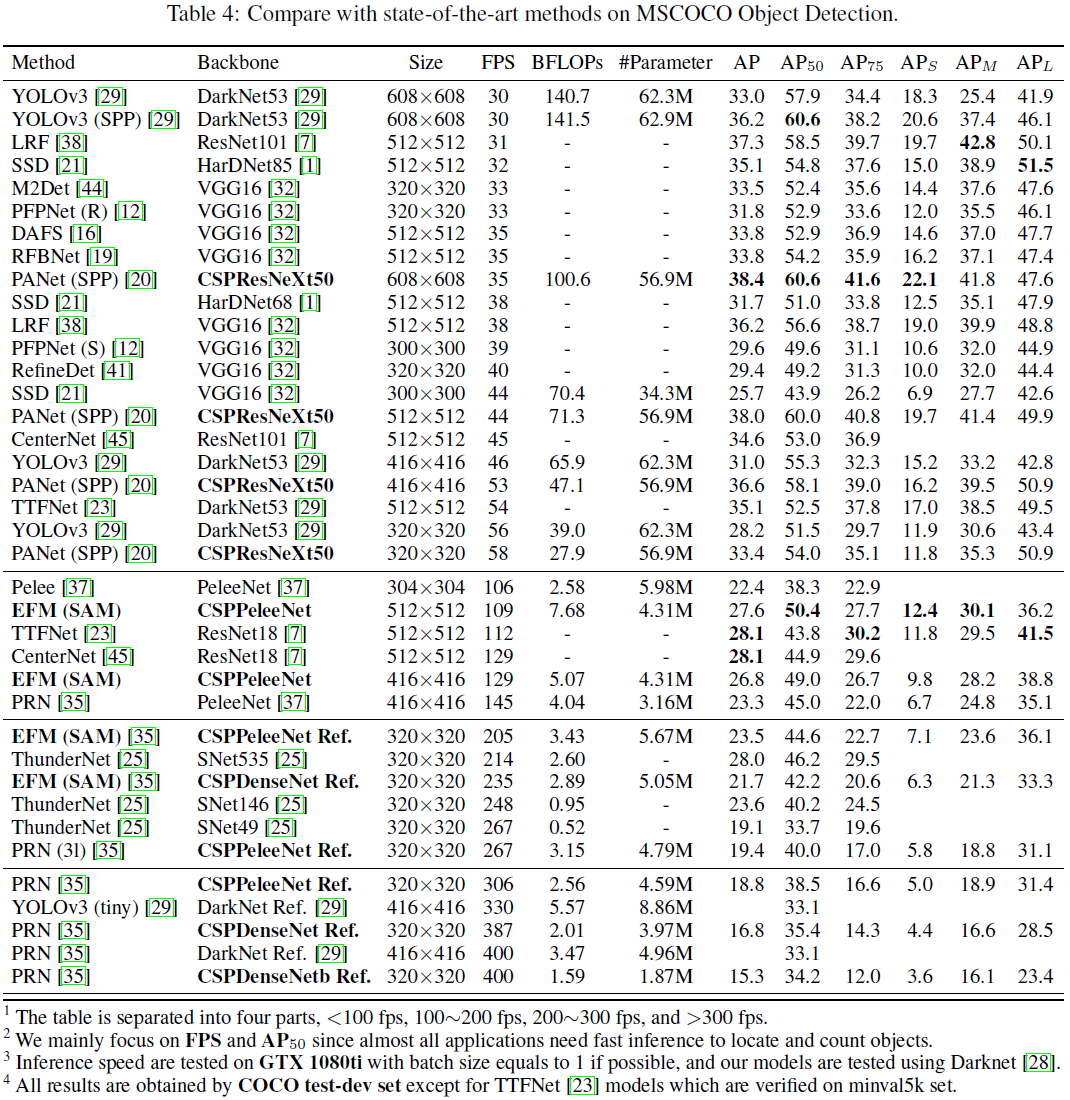
如果目标检测器在 30 30 30 ~ 100 100 100FPS的范围内,带着PANet(SPP)的CSPResNeXt50具有最好的性能( A P , A P 50 , A P 75 AP,AP_{50},AP_{75} AP,AP50,AP75),分别有 38.4 % , 60.6 % , 41.6 % 38.4\%,60.6\%,41.6\% 38.4%,60.6%,41.6%的检测率。如果与最先进的LRF算法在 512 ∗ 512 512*512 512∗512分辨率进行比较,带有PANet(SPP)的CSPResNeXt50要比带有ResNet101的LRF要高 0.7 0.7 0.7%的 A P AP AP, 1.5 1.5 1.5%的 A P 50 AP_{50} AP50, 1.1 1.1 1.1%的 A P 75 AP_{75} AP75。如果目标检测器在 100 100 100 ~ 200 200 200FPS的范围内,带有EFM(SAM)的CSPPeleeNet要比相同速度的Pelee要高 12.1 12.1 12.1%的 A P 50 AP_{50} AP50,比相同速度的CenterNet要高 4.1 4.1 4.1%。
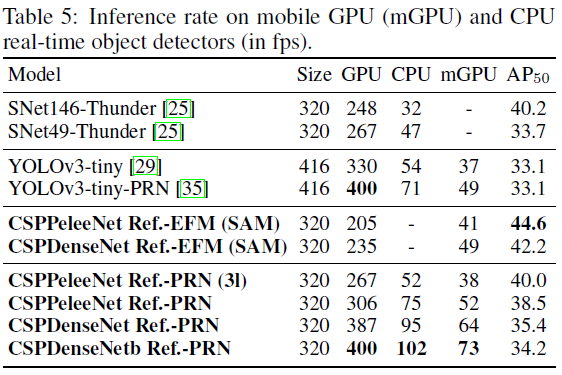
如果要和非常快的目标检测器,比如ThunderNet,YOLOv3-tiny,和YOLOv3-tiny-PRN进行比较,带有RPN的CSPDenseNetb Reference是最快的,能达到 400 400 400fps的帧率,比backbone为SNet49的ThunderNet要快 133 133 133FPS,而且高了 0.5 0.5 0.5%的 A P 50 AP_{50} AP50。如果和ThunderNet146比较,带有PRN的CSPPeleeNet要快 19 19 19FPS且维持一样水平的 A P 50 AP_{50} AP50。

















 7998
7998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









