






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
前面只讲为什么,不写代码,代码全部放在最后
最近突然想看射雕英雄传,但是网上的视频老卡,就想自己爬取出来看(虽然在自己的音频播放器里也很卡哈哈)
提示:以下是本篇文章正文内容,下面案例可供参考
一、下载ts文件并合并
打开视频网站,点击F12,跳到网络,点击ctrl+r重新刷新,发现有很多小的文件

这些小文件就是要我们需要的视频文件
现在我们要找到他的列表进行下载
仔细查看他的最前面有两个文件:index.m3u8和mixed.m3u8
为什么他俩要最先接受呢?
点进去一看,发现他们就是我们需要的列表
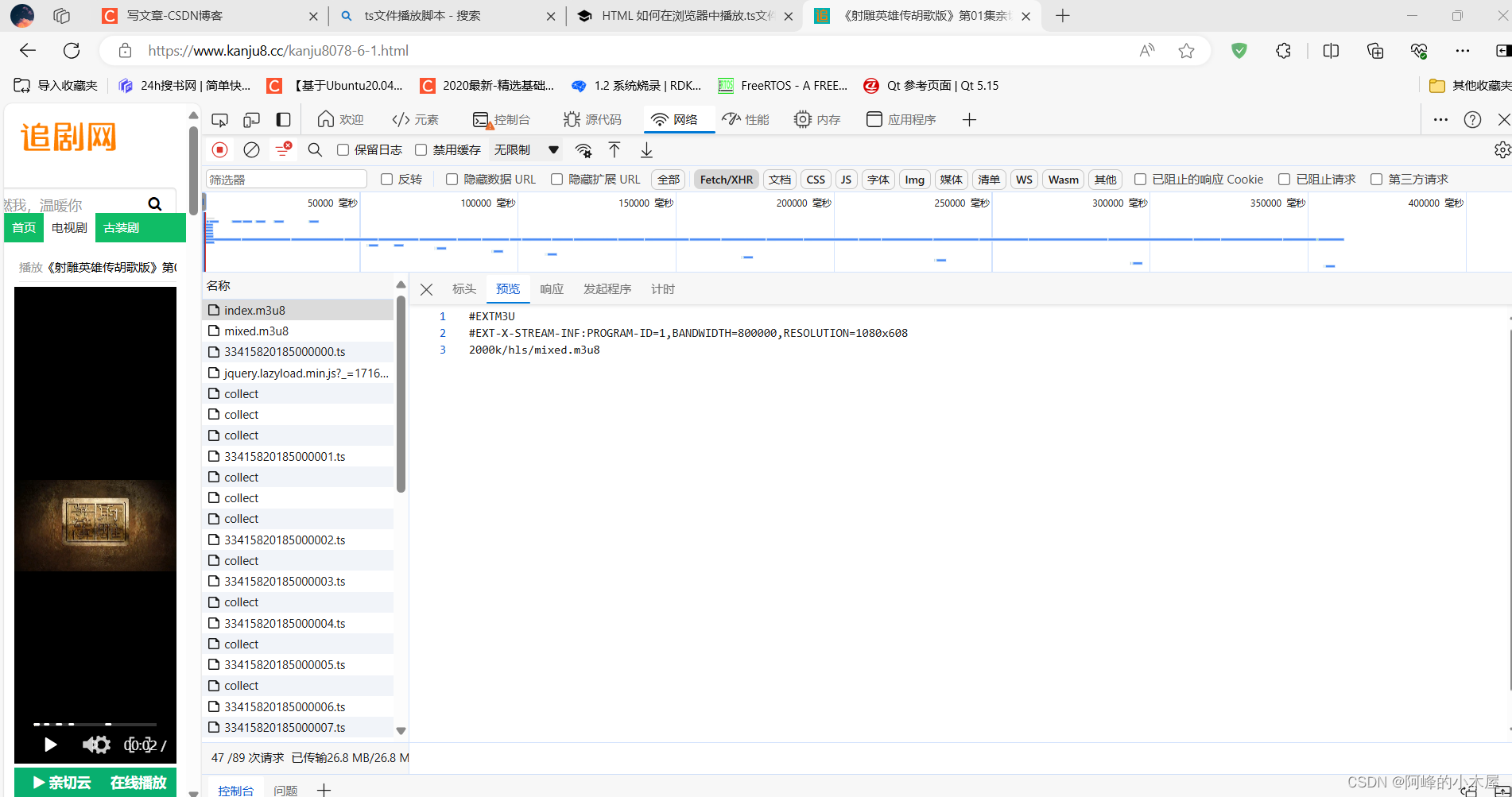
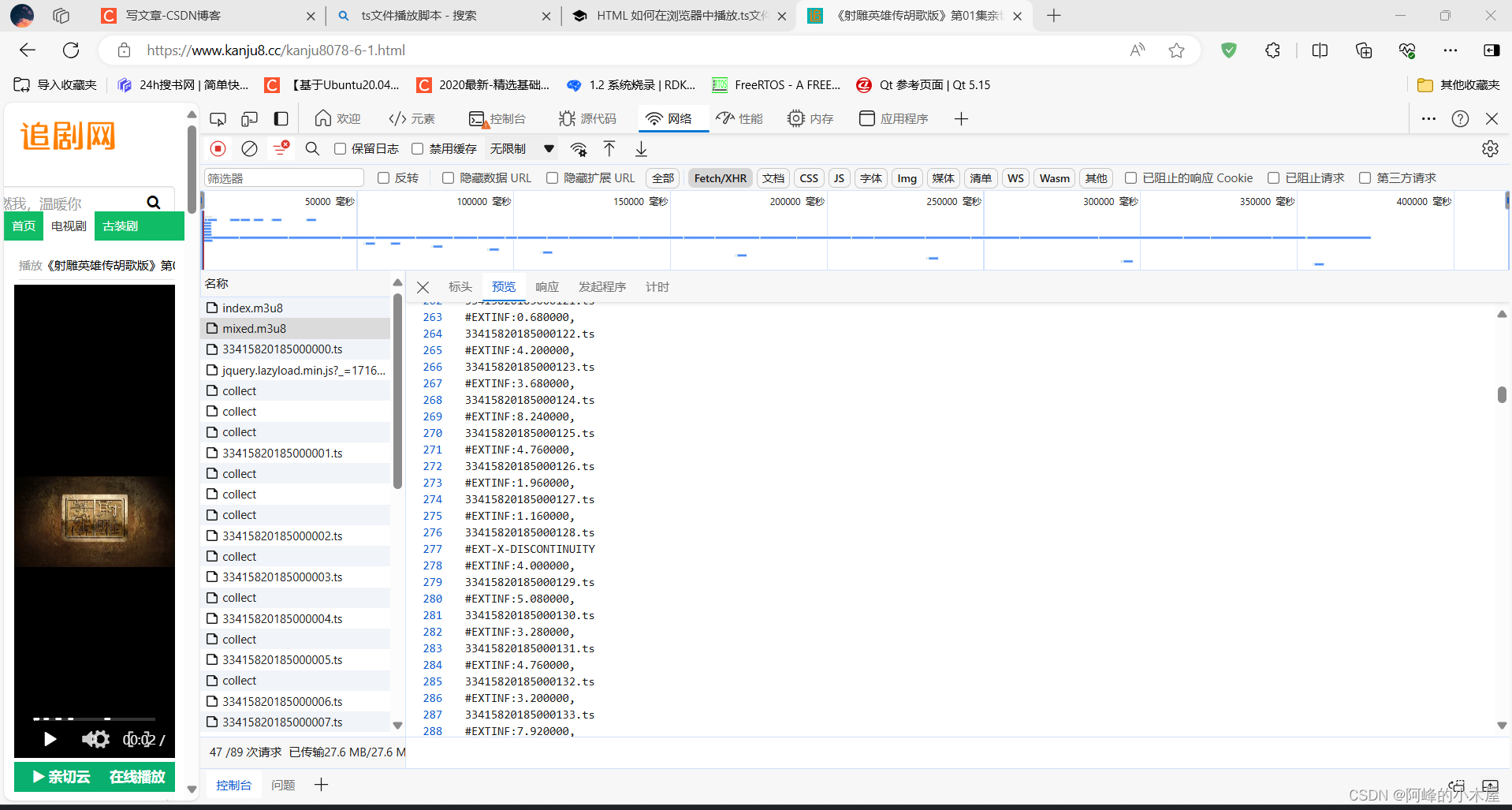
我们用ai写一个正则表达式,把他从源码中抓出来
二、导出信息
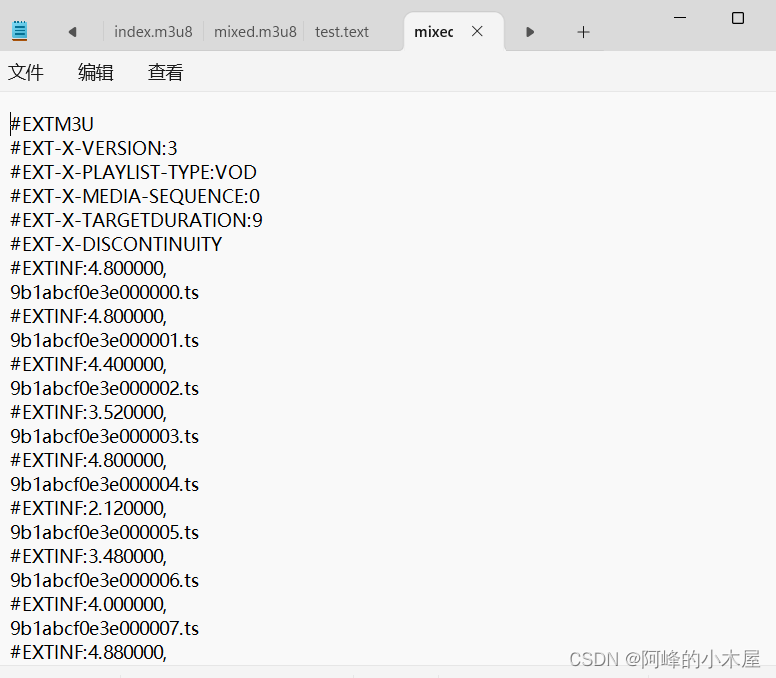
mixed.m3u8中我们需要.ts文件的编号
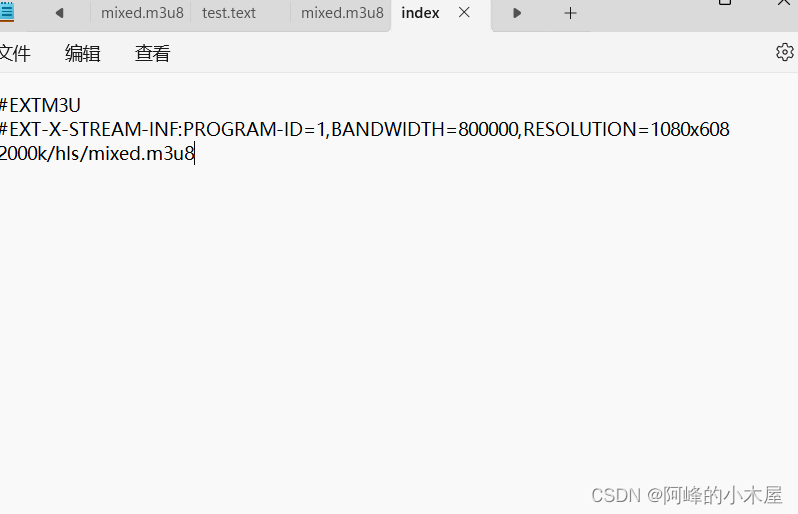
index.m3u8中我们需要mixed文件的地址(本来读取一个就行了,这个网站的作者加了两个文件)
然后就是根据这些信息下载视频文件,最后把这些文件合成一个
三、放代码
(我知道大部分都是来看这个的,前面的就简略一些了)
代码如下(示例):
下载代码
import requests # 导入requests包
import threading
import sys
import re
import time
#用来储蓄mixed的网址
global_url=""
#获取ts文件
def get_ts_url(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6,zh-TW;q=0.5',
'Cache-Control': 'max-age=0',
'Cookie': 'PHPSESSID=fnb11ir6hf7n4ea5qheg66c534; Hm_lvt_632e62475bf2e5b863e145abe974c17a=1716447052,1716449150,1716452751; Hm_lpvt_632e62475bf2e5b863e145abe974c17a=1716452751',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1'}
cookies = {
'PHPSESSID': '3iupdd0qa6inicek1iv97gnnf1',
'Hm_lvt_632e62475bf2e5b863e145abe974c17a':'1716447052,1716449150,1716452751,1716459869',
'Hm_lpvt_632e62475bf2e5b863e145abe974c17a':'1716470366'
}
r=requests.get(url,headers=headers)
return r
# 下载ts文件
def download(url,name):
r=get_ts_url(url)
with open("C:\\Users\\zhou\\Desktop\\ts_all\\"+name, "wb") as code:
code.write(r.content)
#读取信息
def get_list():
with open("C:\\Users\\zhou\\Desktop\\ts\\mixed.m3u8","r") as f:
ts_list = f.readlines()
f.close()
mid_url=global_url.split("/")
urlheader="https://v.cdnlz17.com/20231223/88297_2612d94c/2000k/hls/"
urlheader=urlheader.replace("88297_2612d94c",mid_url[4])
print(urlheader)
count = 0
for i in ts_list:
if "#" not in i:
i = i.replace("\n","")
print(urlheader+i)
if(count<10):
count='00'+str(count)
# download(urlheader+i,"00"+str(count)+".ts")
elif(count<100):
count='0'+str(count)
# download(urlheader+i,"0"+str(count)+".ts")
else:
count=str(count)
# download(urlheader+i,str(count)+".ts")
threading.Thread(target=download, args=(urlheader+i,count+".ts")).start()
count = int(count)+1
time.sleep(0.25)
#读取mixed.m3u8文件
def get_mixed_text(url):
response=get_ts_url(url)
if(response.status_code==200):
print("success")
response.encoding='utf-8'
with open("C:\\Users\\zhou\\Desktop\\ts\\test.text","w",encoding='utf-8') as f: #写入文件
f.write(response.text)
pattern = r'https://v\.cdnlz17\.com/20231223/.*?\.m3u8'
matches = re.findall(pattern, response.text)
mixed=get_ts_url(matches[0])
with open("C:\\Users\\zhou\\Desktop\\ts\\index.m3u8","wb") as f:
f.write(mixed.content)
f.close()
with open("C:\\Users\\zhou\\Desktop\\ts\\index.m3u8","r") as f:
mixed_list = f.readlines()
f.close()
mixed_url=mixed_list[2]
mixed_url = matches[0].replace('index.m3u8', mixed_url)
global global_url
global_url=mixed_url
mixed_url_text=get_ts_url(mixed_url)
with open("C:\\Users\\zhou\\Desktop\\ts\\mixed.m3u8","w",encoding='utf-8') as f:
f.write(mixed_url_text.text)
f.close()
if __name__ == '__main__':
url01=""#写自己的url
get_mixed_text(url01)
get_list()
合并代码
代码如下(示例):
import os
#合并ts文件
def ts_synthesis():
os.system('copy /b ' + r'C:\Users\zhou\Desktop\ts_all\*.ts ' + r'C:\Users\zhou\Desktop\ok.mp4')
print("合并成功")
ts_synthesis()
最终出现这五个文件
出现的一些问题
刚开始下载源码的时候总是乱码
后面关闭了压缩就好了
Accept-Encoding:gzip, deflate, br, zstd















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









