






NoRefER:基于半监督语言模型微调和对比学习的自动语音识别无参考质量度量
第一章 语音增强之《NoRefER: a Referenceless Quality Metric for Automatic Speech Recognition via Semi-Supervised Language Model Fine-Tuning with Contrastive Learning》
文章目录
前言
语音新手入门,学习读懂论文。
本文作者机构是

一、任务
介绍一种新的用于自动语音识别(ASR)系统的无参考质量度量。一种新的方法来自我监督ASR假设质量,通过使用Siamese网络架构和成对排序,利用ASR模型的多个压缩级别来训练一个多语言无参考的ASR质量估计度量。
二、动机
三、挑战
传统的基于参考的ASR系统评估指标需要昂贵的基础事实转录本。
四、方法
1.模型图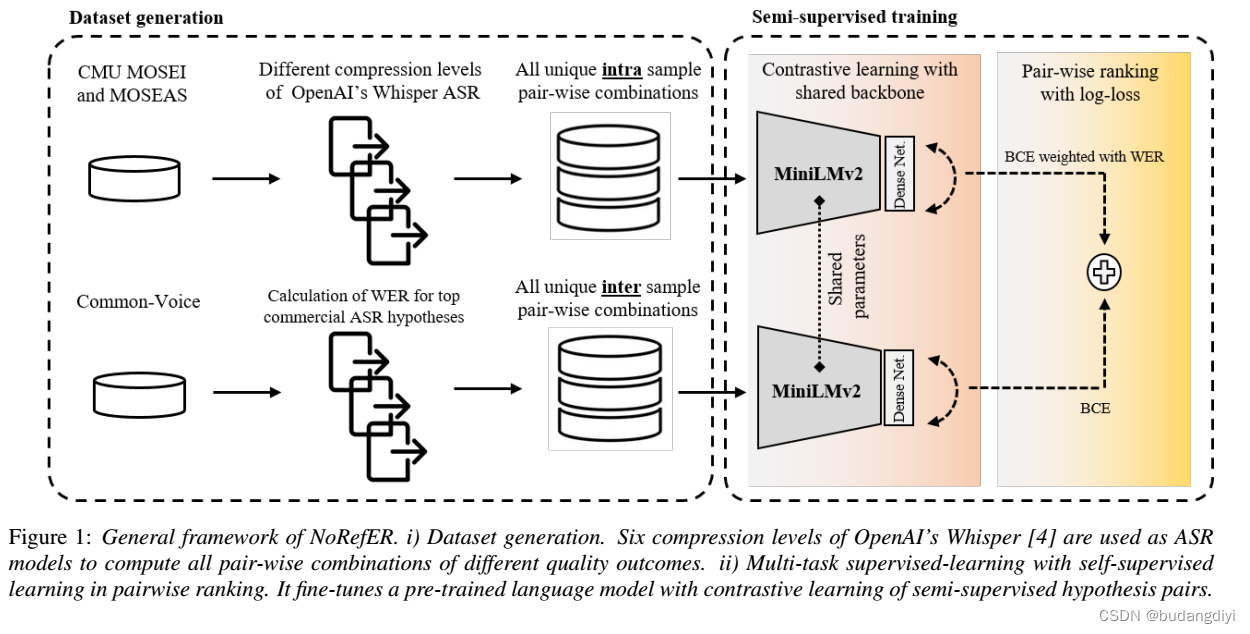
利用预先训练的语言模型,该模型使用对比学习进行微调,采用Siamese网络架构进行成对质量排序决策。
第一个任务侧重于通过利用ASR模型的多个压缩级别之间已知的质量关系进行自监督学习。
第二个任务使用监督学习进行样本间比较,利用具有基本真理的数据集。通过多任务自监督和监督学习,该方法提供了一种半监督的方法来训练LM,用于样本内和样本间假设的质量排序。
2.数据集生成
利用来自一个ASR模型的独特输出形成可以用于对比学习的成对组合。多个压缩级别被用作质量的代理,其中更高的模型压缩级别表示质量较低的转录。提取唯一对的过程涉及选择两个ASR假设,一个具有较高质量,一个具有较低质量,用于相同的语音,并将它们合并为一个对。这些对被随机洗牌并放入用于训练和验证集的小批次中。每对的训练和验证损失使用配对假设之间的词错误率(WER)进行加权。当两个假设之间的距离较大时,模型在进行错误的成对排名决策时会受到更严厉的惩罚,因为当它们接近时,进行成对排名错误是更可接受的。通过使用这种方法对提出的Siamese网络进行微调,可以有效地训练和验证质量度量方法,而无需使用真实转录。
3. 自监督 学习
该方法利用预先训练的跨语言语言模型(LM)和Siamese网络架构,然后使用密集编码器将LM产生的嵌入减少到单个标量logit。然后使用这个logit来比较Siamese网络的输出。该体系结构中预训练的LM是MiniLMv2,这是一个更小,更快的语言理解模型。
二元交叉熵(Log-Loss)由对之间的WER加权。
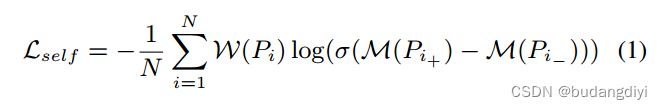
W为WER,σ(.)为Sigmoid激活,M(.)为模型的输出,N为对的数目,Pi+和Pi−分别表示每对的正样本和负样本。通过利用这种对比学习过程,LM可以学习对其质量的判别的高级表示。这种方法可以有效地训练一个无参考的质量度量,允许在没有参考的情况下进行准确的样本内假设比较。
4.半监督 学习
noreference方法通过引入额外的LogLoss项,将其自监督微调扩展到半监督版本。
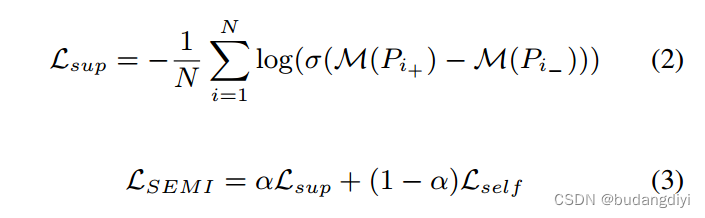
α是合并两个损失的权重参数,默认设置为0.5。
五、实验评价
1.数据集
大型自监督语料库,CMU MOSEI和MOSEAS数据集。提出的度量是使用独特的语音抄本对进行自我监督的,基于压缩水平,每对中的一个假设已知具有比另一个更高的质量。在剔除不一致的假设对后,共有800,340个自监督平行ASR假设对,其中20%保留作为验证集。使用来自Common Voice训练数据集的额外一批数据来促进半监督训练。
2.消融实验
3.客观评价
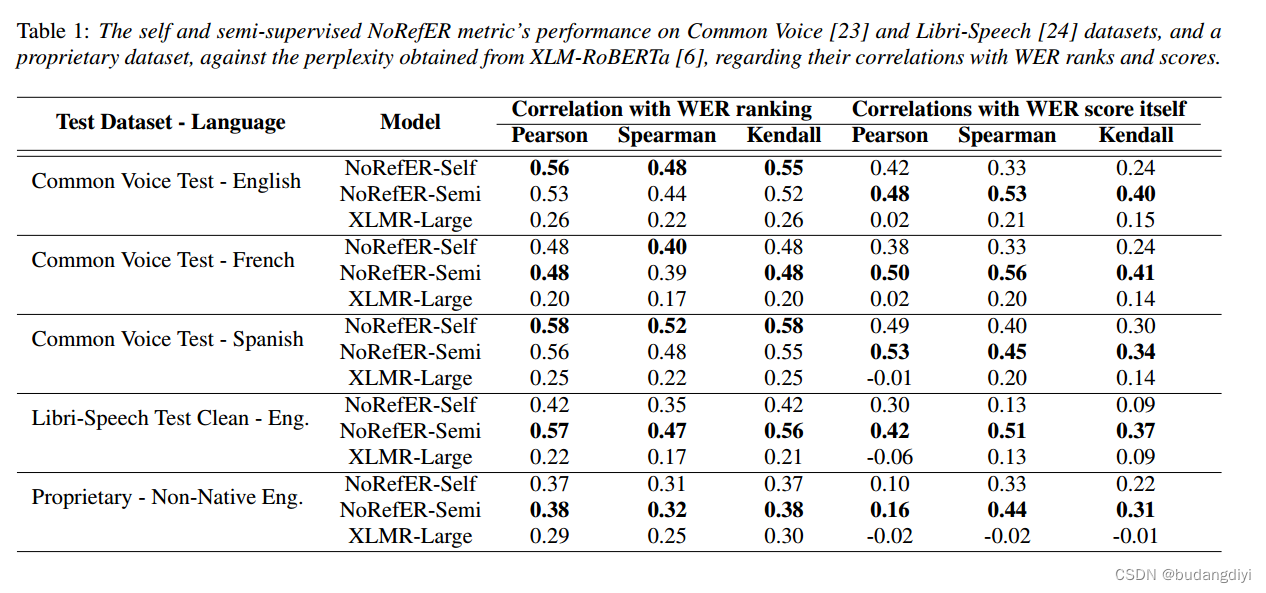
与WER排名的相关性。与WER分数本身的相关性。
Pearson相关系数衡量两个变量之间的线性关系,Spearman相关系数是两个变量之间单调关系的非参数度量,Kendall相关系数衡量两个排名之间的一致性。所有相关系数的得分范围为-1 ~ 1,-1为强负相关,0为不相关,1为强正相关
4.主观评价。
六、结论
这项工作为ASR系统提出了一个多语言无参考的质量度量,当没有基础事实可用于评估ASR输出的质量时,它是有用的。实验结果表明,无参考度量可以在不同的ASR模型之间提供有意义的质量比较,是一种可行的ASR系统替代评价度量。此外,当在包含商业ASR引擎输出的盲数据集上进行测试时,无参考指标与这些引擎的WER分数和排名密切相关。这种无参考的度量具有显著提高实际应用中ASR系统的改进和评估生命周期的潜力。未来的研究可以集中在通过结合基于音频的特征进行无参考质量估计来迁移学习所提出的度量。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











