






在上篇中,我们探讨了构建RAG应用中常面临的两个问题:如何提高语义检索的精度以及实现多轮对话中上下文理解的检索。本文接着探讨另一个常见的也是比较复杂的问题:
- 如何对多模态文档,特别是其中的图片内容进行嵌入、检索与引用?
我们将基于Google最新的Gemini多模态模型作简单实现与测试。
01 需要处理的图片
在构建基于大模型的RAG应用时,通常需要从大量的文档中导入私有知识,需要对其中的内容进行分割、嵌入与索引,从而能够在响应用户输入时检索到需要引用的关联知识。
棘手的是,我们在处理这些文档时,往往面临的是一个混合了多种内容形式的文档,其中对于文本类型的内容处理相对简单,不管是纯文本,还是Markdown或者HTML;而相对复杂的是图片内容,如果没有完善的处理方案,那么就会丢失图片中的有价值信息。
需要强调的是,并不是所有的文档中涉及的图片都需要处理。通常来说,在RAG应用中需要做深度处理的图片指的是:**包含了可能会被检索与参考到的知识信息的图片。**比如:
-
一个包含了产品详细操作说明的示意图
-
一个反映了数据分析结果的可视化图表
-
一个与竞争对手产品对比的表格图片等
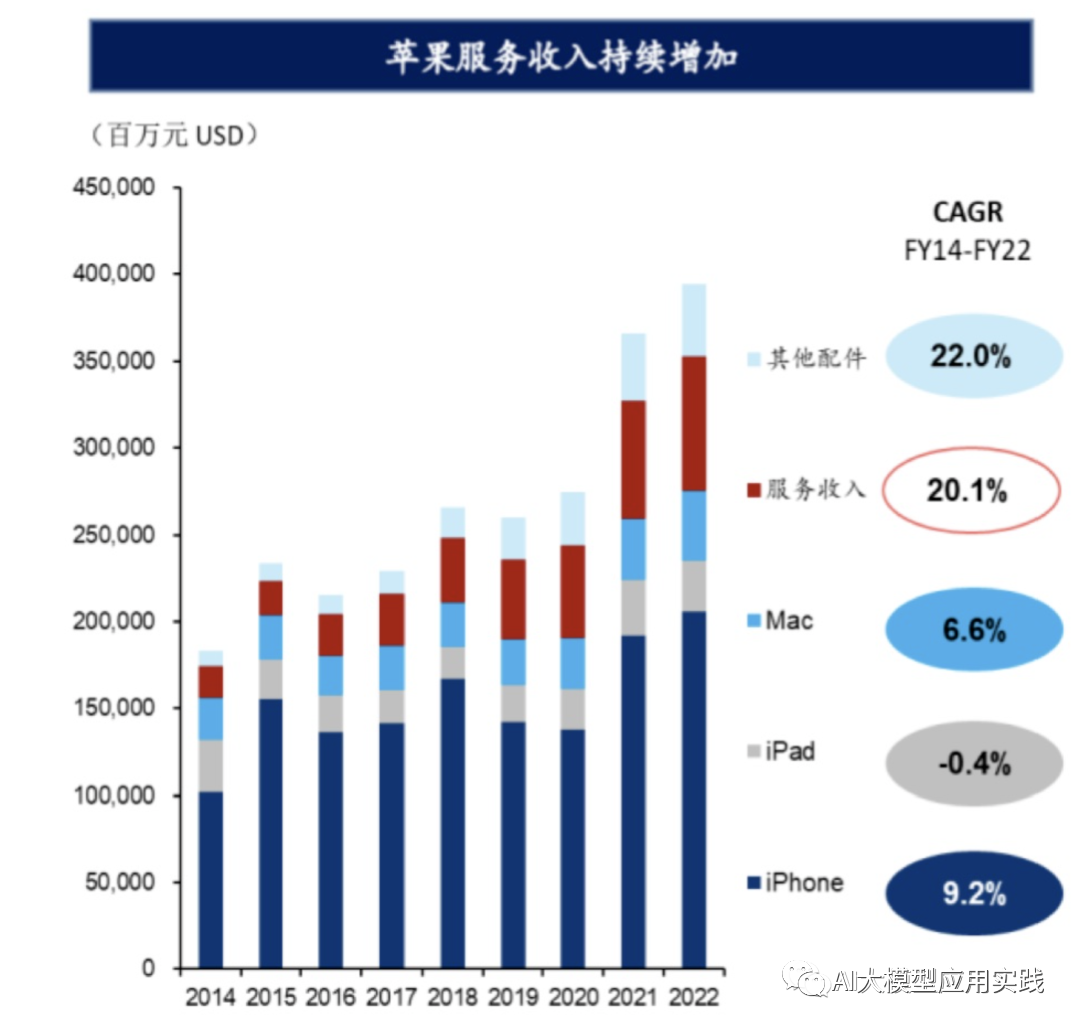
一个包含有用信息的图片
**文档中一些仅用于参考的图片或者无关的装饰图则无需进行RAG相关处理(**注意这一类图片只是不需要进行类似嵌入与语义检索的操作,但仍然有可能需要在大模型响应时输出,如包含在输出的Markdonw内容中)。比如:
-
一个已经有了文字说明的操作手册中的界面截图
-
一些不包含有用知识的装饰型图片
-
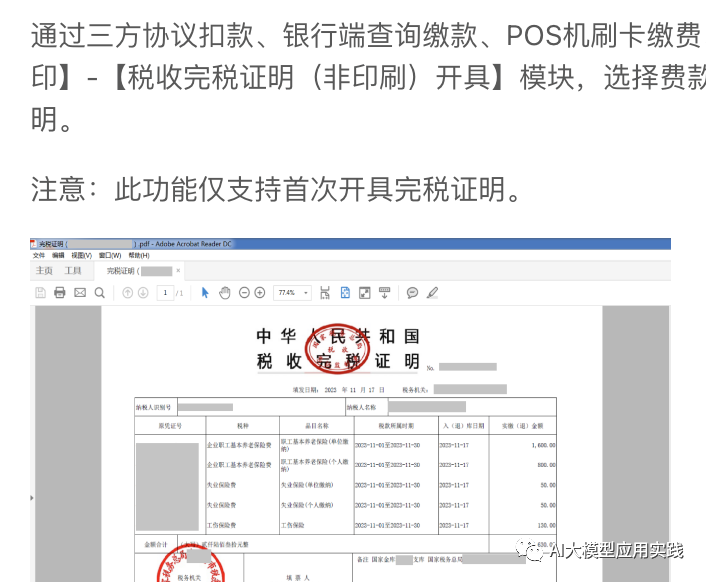
一个无需处理的参考图片

02【图片RAG处理方案】
多模态的混合文档处理的总体方案,我们在之前文章中结合了Langchain开发框架做过介绍(点击阅读:GPT4-V之前:企业私有知识库中半结构化与多模态数据的RAG方案思考)。我们在此做简单总结:
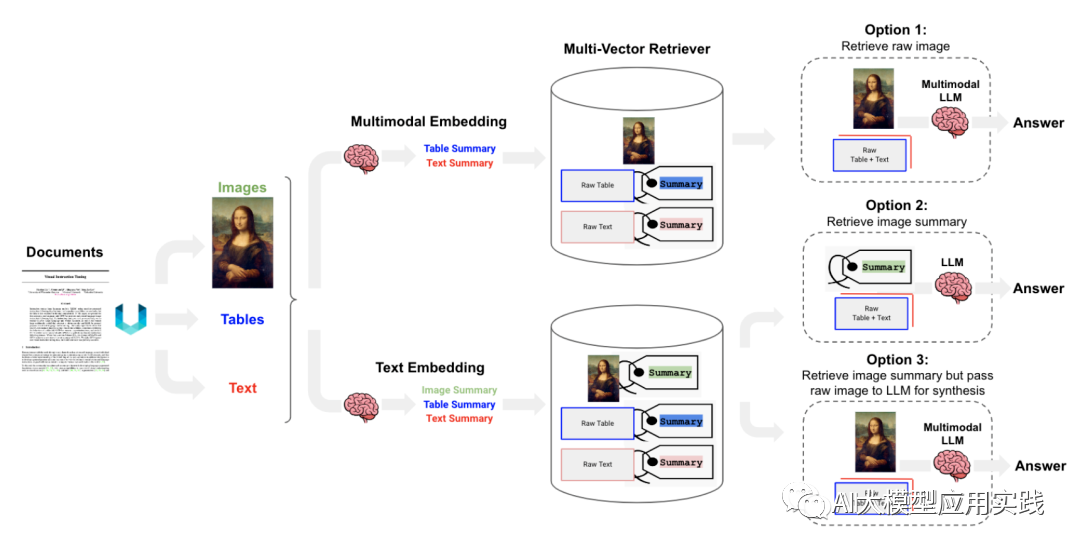
图片来自LangChain Cookbook
忽略掉其中对文本内容(Text)的处理,这里展示了三种具有代表性且复杂性有区别的图片(Image)处理方法,我们对这里的三种方法做简单剖析以帮助我们更好的选择与实现:
方法1
-
嵌入:直接嵌入图片,需要借助特殊的图片嵌入模型
-
检索:直接根据用户问题语义检索出原图片即可
-
引用:借助多模态大模型(GPT-4v/Gemini等),输入检索出的图片
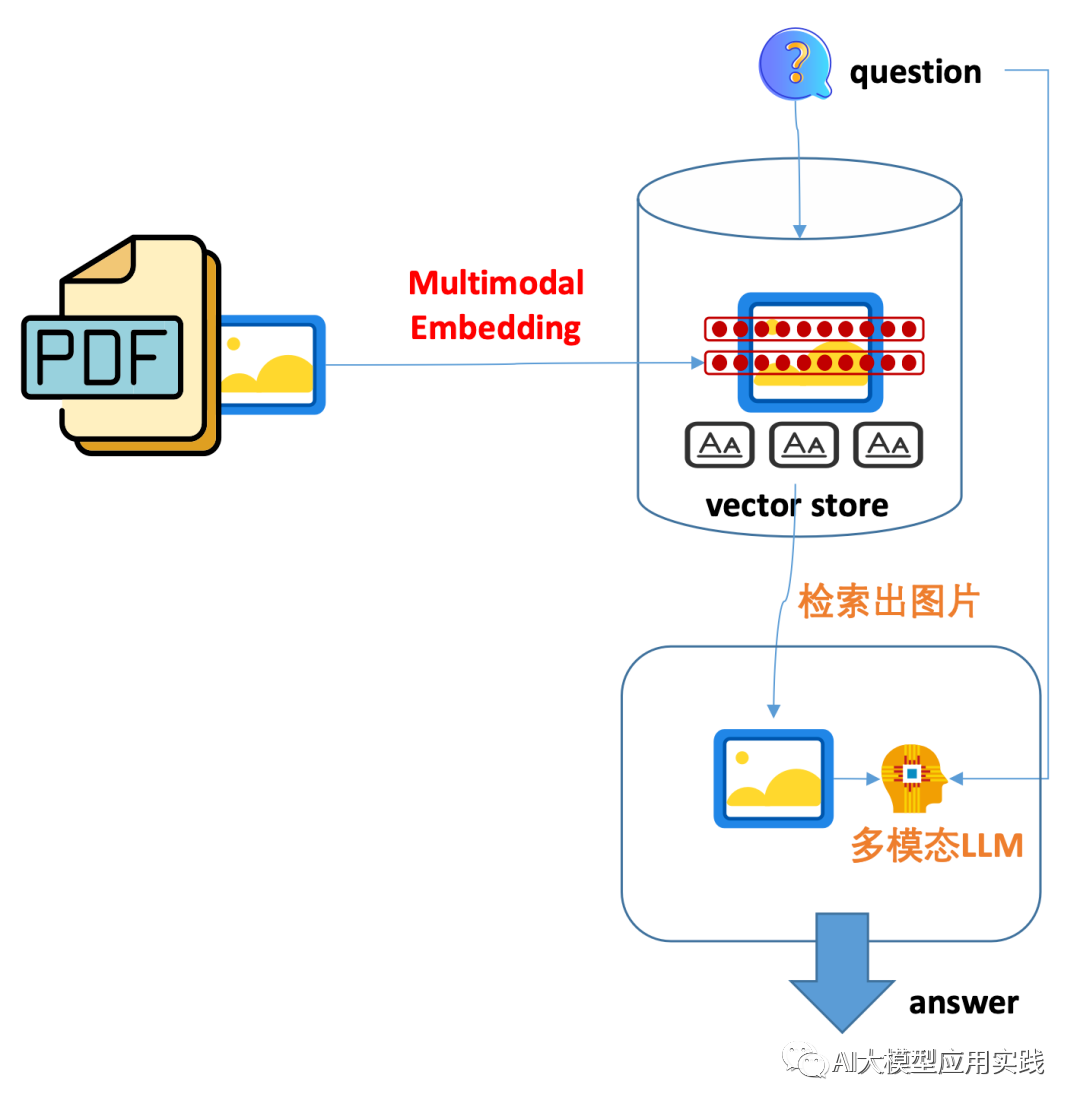
方法1的特点是**直接对图片嵌入。**其特殊性在于需要借助多模态的embedding模型(如OpenClip)以及支持多模态的向量库(如Chroma),由于不需要生成图片的摘要信息,因此简化了嵌入的过程;但同时也引入了多模态嵌入与检索过程的复杂性
方法2
-
嵌入:嵌入图片摘要信息(Summary),需借助多模态模型先生成摘要
-
检索:通过用户问题检索出图片摘要信息文本
-
引用:将检索的摘要信息作为上下文输入大模型获得响应
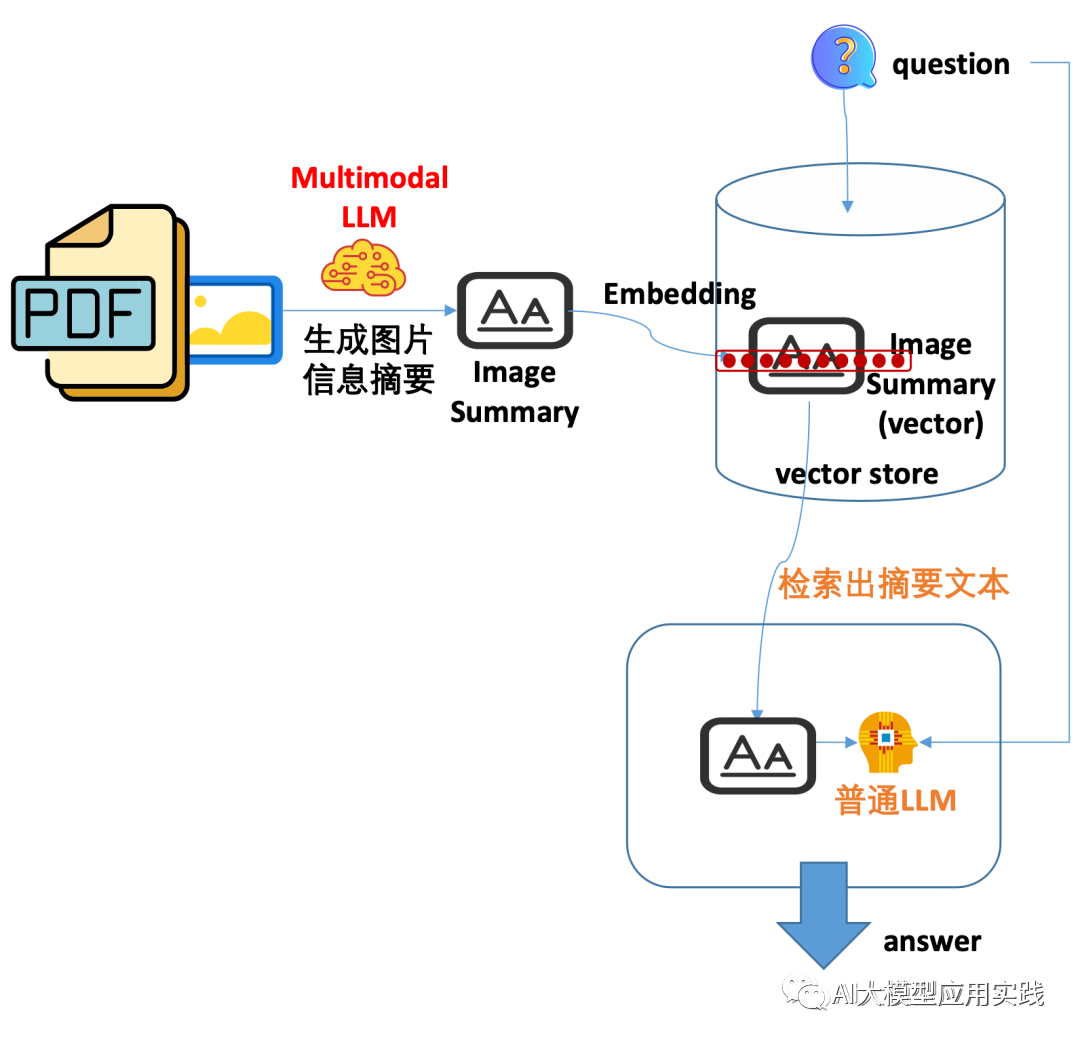
方法2是一种最简单也是效果相对较差的方法。简单的说就是在嵌入时把图片转成图片的摘要文本,后续的检索与引用都基于该文本处理。由于摘要可能隐藏了图片的大量真实细节信息,可能会导致回答效果较差。一种简单优化的方法是在生成摘要文本的时候,要求尽量细节化(借助多模态大模型)。
方法3
-
嵌入:嵌入图片摘要信息(Summary),需借助多模态模型先生成摘要
-
检索:通过用户问题关联检索出图片摘要信息与原始图片
-
引用:借助多模态大模型(GPT-4v/Gemini等),输入检索出的原图
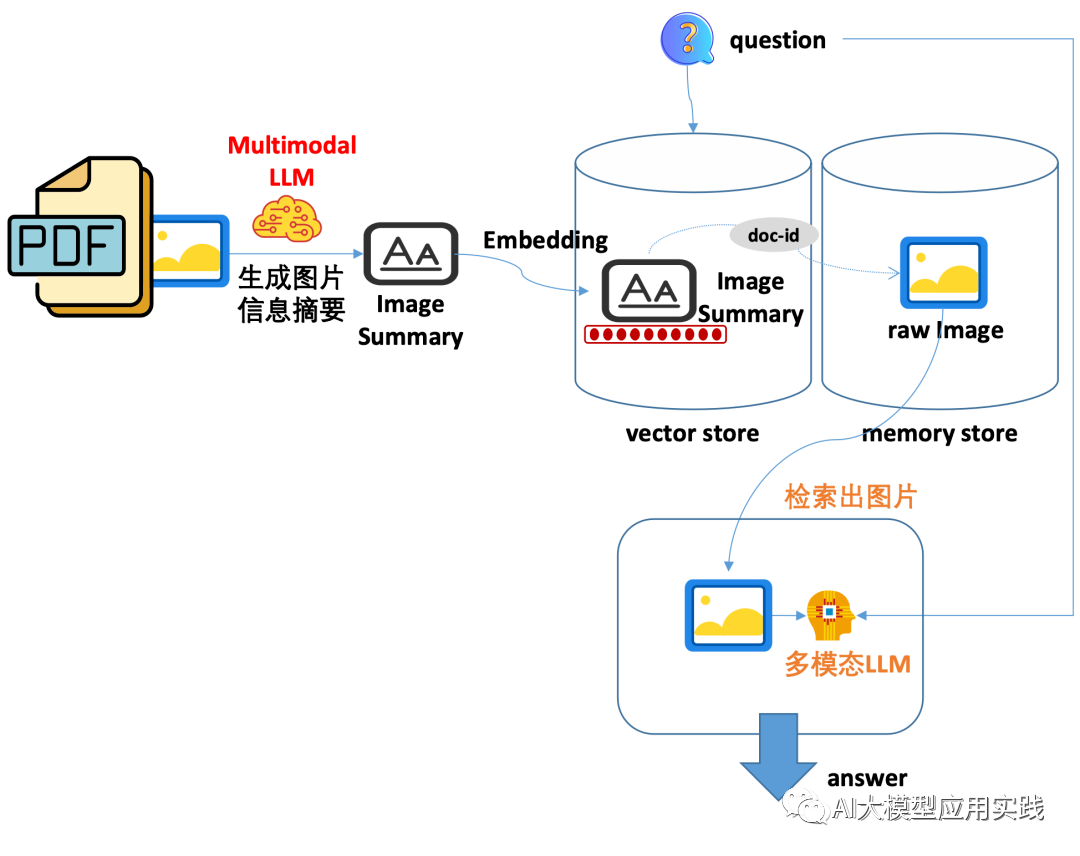
**推荐的一种方法。**其嵌入的对象是生成的图片摘要文本信息,因此只需要普通的文本embedding模型即可;但是在检索时会通过元数据关联获取到原始图片,进而引用原始图片,并借助多模态大模型响应用户输入。

03 基于Gemini模型的实现
Google最新推出的Gemini模型支持多模态,且当前的API还处于免费调用阶段,非常适合研究与测试。所以这里我们借助于最新的Google的Gemini Pro模型来简单实现与测试方法3中的过程。为了更好的关注重点,这里忽略了从原始文档比如PDF提取图片的过程(可参考之前的文章),我们假设提取的图片已经存放在本地目录中,其中包含三张测试图片:
基本的处理过程如下:
-
生成图片摘要信息
-
对图片摘要进行嵌入与关联存储
-
输入用户问题检索,并输入大模型获得响应
1. 生成****图片摘要:首先将原始图片转为base64格式,并通过多模态模型生成摘要信息即可。这个处理过程比较简单,只需要利用提示词即可完成。下面是一个生成某个图片摘要的参考代码(仅列出关键过程)
"""
对单一图片生成摘要文本信息,借助google gemini多模态模型
"""
def image_summarize(img_path):
#模型
model = ChatVertexAI(model_name="gemini-pro-vision",
max_output_tokens=1024,project="my-ai-assistant")
#提示
prompt = """你是一位负责为检索任务总结图像的助手。这些总结将被嵌入并用于检索原始图像。给出一个简洁的、针对检索优化的图像总结。"""
#图片转为encode格式
img_base64=encode_image(img_path)
msg = model(
[
HumanMessage(
content=[
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url":{"url":f"data:image/jpeg;base64,{img_base64}"},
},
]
)
]
)
我们来看看生成的摘要效果:

2. 嵌入与向量存储:在生成图片摘要后,需要对生成的图片摘要信息作嵌入,借助于嵌入模型,可以轻松的完成这个任务。但是这里有一个问题:
由于后续我们需要在检索(retrieve)的时候关联获取到原始图片,因此在嵌入并存储到向量库时,要建立一个图片摘要与原始图片之间的映射关系,这可以简单的通过一个doc_id来实现关联。
我们推荐使用Langchain中的多向量检索器(MultiVectorRetriever),可以很方便建立这种映射关系,并且在检索时自动关联取出原始图片。
多向量检索也是我们在上篇中介绍的RAG应用中提高文本知识语义检索精度的一种重要方案。
下面展示对图片摘要进行嵌入与存储,并关联原始图片的处理过程:
"""
对图片摘要images_summaries作嵌入,并关联原始图片images
传入图片摘要列表与图片列表
"""
def create_images_retriever(image_summaries, images):
#向量存储:用来存放图片摘要的向量(chroma)
vectorstore = Chroma(collection_name="google_test",embedding_function=VertexAIEmbeddings(model_name="textembedding-gecko@latest",project="my-ai-assistant"))
#普通存储:用来存放原始图片(base64)
store = InMemoryStore()
#两者之间通过doc_id关联
id_key = "doc_id"
#创建一个多向量检索器,关联到以上存储
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
#对每个图片创建doc_id
doc_ids = [str(uuid.uuid4()) for _ in images]
#将图片摘要嵌入到vectorstore,注意元数据为doc_id
summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(image_summaries)]
retriever.vectorstore.add_documents(summary_docs)
#将原始图片存放到普通内存存储,注意将doc_id与图片关联
retriever.docstore.mset(list(zip(doc_ids,images)))
#后续将用此retriever进行检索
return retriever
3. 语义检索并引用: 在完成上述“准备工作”后,接下来就可以接受用户输入。根据用户的输入进行关联图片的检索,然后把图片作为参考的上下文,与用户输入问题一起交给多模态大模型,等待响应即可。
使用上面返回的多向量retriever检索器,则过程会变得非常简单,我们建立一个简单的LangChain中的链,来自动的完成这个过程:语义检索->图片提取->Prompt组装->大模型输出这个过程。处理过程如下(使用gemini-pro-vision多模态大模型):
# 创建用来回答问题的多模态大模型:gemini-pro-vision
model = ChatVertexAI(temperature=0, model_name="gemini-pro-vision", max_output_tokens=1024,project="my-ai-assistant")
#创建一个langchain的处理链
#此处传入的参数:
#retriever:上文创建的检索器
#split_image_text_type: 这是一个把检索出来的文档区分成普通文本与图片的方法
#img_prompt_func: 这是一个把上面的context,question等组装成prompt的方法
chain = (
{
"context":retriever | RunnableLambda(split_image_text_types),
"question": RunnablePassthrough(),
}
| RunnableLambda(img_prompt_func)
| model
| StrOutputParser()
)
#获得输入
query = input("请输入你的问题:")
#调用获得结果
result=chain.invoke(query)
可以看到借助Langchain,可以简洁优雅的完成整个过程(当然,完全可以自主实现)。这里面涉及到两个辅助方法:
一个是split_image_text_types:之所以有这样的过程,是由于在实际处理时,如果把图片摘要与普通文本知识一起做嵌入时,那么检索出来的参考知识就会混合图片(base64)与文本内容,由于两种类型的内容在交给大模型时处理方式不同,因此需要在此区分,并用于后续处理,可借助base64工具库完成。
另外一个是img_prompt_func: 这是将检索出的关联内容(文本内容或者图片内容)、用户问题一起组装成Prompt的方法;一般只要根据你所使用的多模态模型的API规范进行封装即可。比如:
#本方法用来组装prompt消息
#注意输入为上文chain中的第一个参数
#包含了用户问题question与context,context包含了语义检索出的、拆分后的普通文本内容与图片内容
messages = []
#引用的普通文本内容
context_texts = "\n".join(data_dict["context"]["texts"])
#将用户问题与需要引用的普通文本内容作为上下文包装成文本消息
text_message = {"type": "text","text": ("你是一名聪明的AI问答助手,你会根据提供给你的文本、表格、图片(通常为图表或者带有文字的图片),来智能的回答用户问题。如果无法根据提供的信息回答问题,请回答'我暂时无法理解你的问题',不要编造答案。\n"
f"用户问题是: {data_dict['question']}\n\n"
"文本信息如下:\n"
f"{context_texts}"
),
}
messages.append(text_message)
#将需要引用的图片内容包装成图片消息
for image in data_dict["context"]["images"]:
image_message = {"type": "image_url","image_url":{"url": f"data:image/jpeg;base64,{image}"}}
messages.append(image_message)
#OK,现在messages发送给大模型即可!
现在,我们来看下测试结果:

Gemini模型很好的回答了我们的问题。对比上文的第一个测试图片,也证实了这个图片被检索了出来,并且传给了大模型做输出参考。

04 结束语
以上简单介绍了针对包含知识内容的图片,如何在RAG应用中进行嵌入、检索与生成。实际应用中,还可以根据需要在以下两个方面做优化:
-
图片的摘要信息生成可以根据用户问题做优化以提交检索精度。比如生成更详细的信息以覆盖更多语义、或者利用大模型生成一些假设性的问题等。
-
注意多模态大模型的选择。实际测试中我们发现目前多模态大模型(比如Gpt-4v/Gemini)在图片文字内容识别、特别是中文识别时仍然存在一定的不完善,从而导致回答错误。
在下篇中我们将探讨如何基于开源框架评估RAG应用的效果。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









