






研究背景
近年来,大型语言模型在医疗领域展现出巨大潜力。GPT-4和MedPalm-2等闭源模型在医疗问答中表现出色,甚至成功通过美国医疗执照考试(USMLE)。同时,开源模型如MEDITRON、PMC-LLaMA等也在逐步缩小与闭源模型的差距。
然而,目前医疗大模型主要局限于英语应用,这极大限制了其服务全球多语种人群的潜力。虽然BLOOM和InternLM 2等开源多语言模型在通用领域表现不错,但在非英语医疗查询方面表现欠佳,主要是因为通用数据集中医疗内容占比较少。
为解决这一问题,上海交通大学和上海人工智能实验室的研究团队发布了一项开创性工作,他们构建了首个大规模多语言医疗语料库MMedC,并基于此开发了高性能的开源多语言医疗大模型MMed-Llama 3。
主要贡献
论文的主要贡献可以概括为三个方面:
- 构建了大规模多语言医疗语料库MMedC
-
包含约25.5B个token
-
覆盖6种主要语言:英语、中文、日语、法语、俄语和西班牙语
-
数据来源多样:医学教材、医疗网站、现有小规模语料库等
- 提出多语言医疗问答基准MMedBench
-
包含53,566个问答对
-
覆盖21个医学领域
-
每个问题配有详细解释
- 开发了高性能开源多语言医疗大模型MMed-Llama 3
-
在多语言医疗问答和英语基准测试上均优于现有开源模型
-
在某些任务上接近GPT-4的性能水平
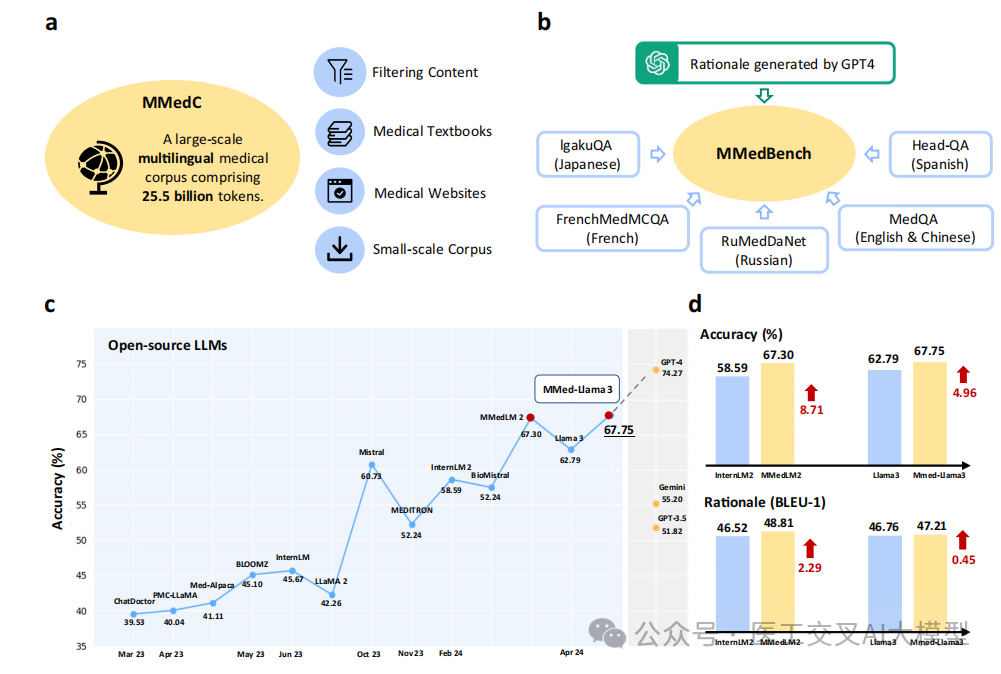
论文图1展示了整体框架,包括MMedC语料库构建、MMedBench基准开发和模型评估三个主要部分。

多语言医疗语料库MMedC详解
1. 数据来源
MMedC的数据来自四个主要来源:
a)医疗内容过滤:
-
从CulturaX数据集(6.3万亿tokens)中筛选医疗相关内容
-
每种语言设计200个医疗关键词进行匹配
-
使用两个关键指标进行筛选:
-
医疗关键词计数(MKC):文本中唯一医疗关键词数量
-
关键词密度(DENS):医疗关键词占总文本长度的比例
关键词密度计算公式:
其中,表示文本总长度,表示关键词k在文本T中出现的次数。
b)医学教材:
-
收集超过20,000本医学教材
-
使用PaddleOCR进行多语言文字识别
-
英语4B、中文1.1B、俄语0.4B、法语0.3B tokens
c)医疗网站:
-
医学百科全书
-
医疗咨询平台
-
医疗新闻网站
-
日语0.1B、西班牙语0.05B、法语0.1M tokens
d)现有小规模语料库:
-
Wikipedia医疗内容
-
百度百科医疗内容
-
UFAL医疗语料库
2. 数据分布
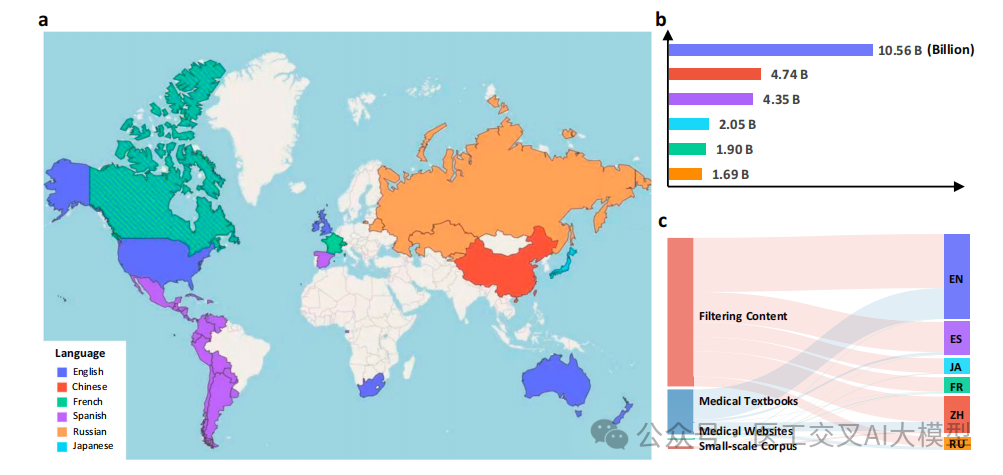
论文图2展示了MMedC的语言分布和各数据源的贡献情况:
-
英语占比最大(42%),约10.56B tokens
-
中文和法语分别占18.6%和17.1%
-
日语、西班牙语和俄语各占8-10%
多语言医疗基准MMedBench
1. 数据组成
MMedBench整合了多个现有医疗问答数据集:
-
MedQA(英语、中文)
-
IgakuQA(日语)
-
FrenchMedMCQA(法语)
-
RuMedDaNet(俄语)
-
Head-QA(西班牙语)
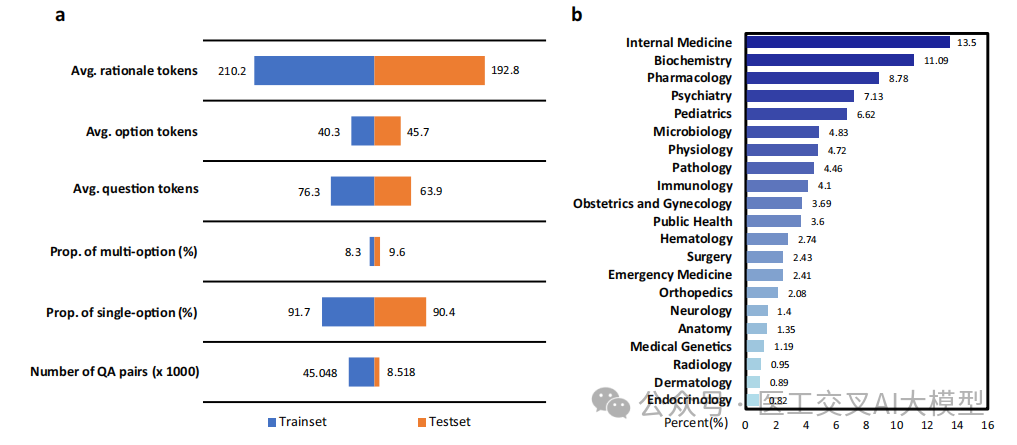
论文图3展示了MMedBench的详细统计信息:
-
训练集45,048个问答对
-
测试集8,518个问答对
-
平均问题长度192.8个tokens
-
平均答案选项长度40.3个tokens
-
平均解释长度210.2个tokens
2. 评估指标
模型性能评估采用两个主要指标:
-
选择题准确率
-
解释生成质量:
-
BLEU分数:
-
ROUGE分数:
-
BERT-Score:
实验结果
1. 多语言评估
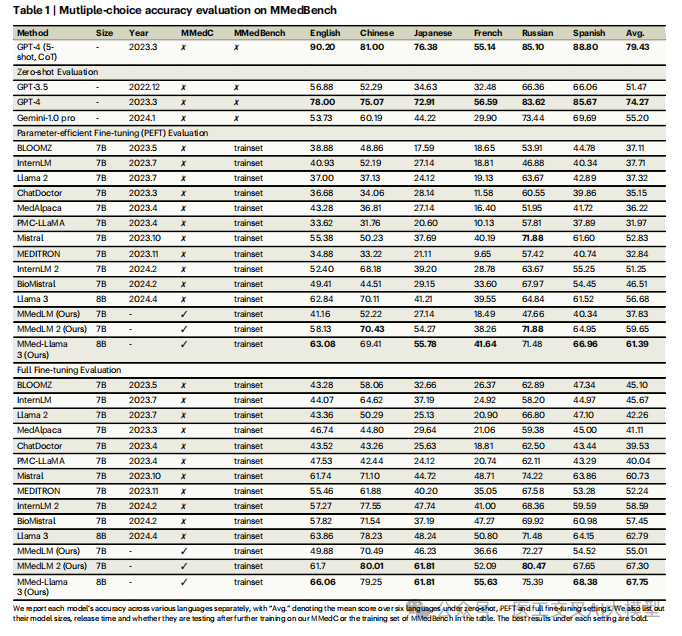
论文表1展示了在MMedBench上的多语言评估结果:
-
MMed-Llama 3在大多数语言上显著优于现有开源模型
-
在某些语言上甚至接近GPT-4的性能
-
平均准确率达67.75%,超过其他开源模型
2. 英语基准测试
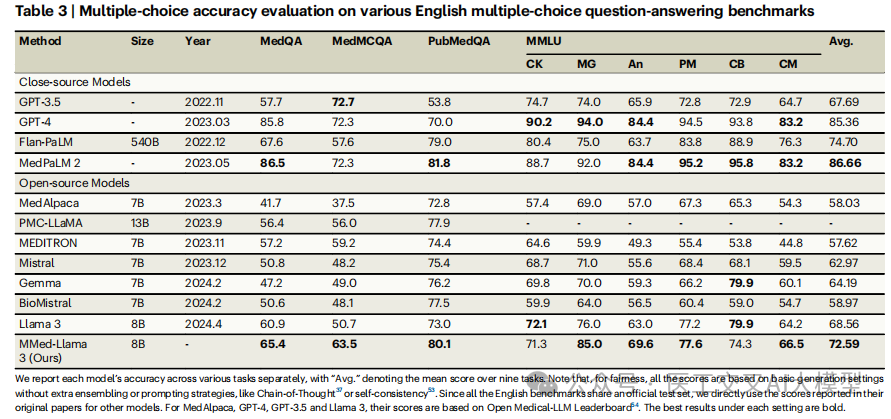
论文表3展示了在英语医疗基准上的表现:
-
MedQA:65.4%
-
MedMCQA:63.5%
-
PubMedQA:80.1%
-
MMLU医学类:平均72.59%
这些结果证明MMed-Llama 3不仅在多语言场景表现出色,在专门的英语医疗任务上也具有竞争力。
代码与数据开源
项目相关资源已全部开源:
-
MMedC数据集: https://huggingface.co/datasets/Henrychur/MMedC
-
MMedBench基准: https://huggingface.co/datasets/Henrychur/MMedBench
-
源代码: https://github.com/MAGIC-AI4Med/MMedLM
-
模型权重:
-
MMedLM: https://huggingface.co/Henrychur/MMedLM
-
MMedLM 2: https://huggingface.co/Henrychur/MMedLM2
-
MMed-Llama 3: https://huggingface.co/Henrychur/MMed-Llama-3-8B
总结与展望
这项工作首次构建了大规模多语言医疗语料库,为开发高性能多语言医疗大模型奠定了基础。MMed-Llama 3的优异表现证明了这一方向的可行性和重要性。
未来工作将从以下几个方面继续推进:
-
扩大语言覆盖范围,如增加德语、阿拉伯语等
-
开发更大规模的模型以进一步提升性能
-
加入检索增强机制以减少模型幻觉
-
增强模型可解释性
-
改进数据质量控制以减少偏见
这项工作为推动全球医疗AI发展迈出了重要一步,有望帮助更多非英语地区获得优质的AI医疗服务。
Q&A深度解析
Q1: MMedC语料库的数据质量如何保证?特别是从通用语料库筛选医疗内容的部分。
A: MMedC采用了多层次的质量控制机制:
- 关键词筛选:
-
每种语言精心设计200个医疗领域关键词
-
同时考虑关键词计数(MKC)和密度(DENS)两个指标
-
通过严格的阈值控制确保内容相关性
- 人工验证:
-
随机抽样100句进行人工检查
-
验证结果显示98%准确率
-
由医学专业人员进行审核
- 多源数据互补:
-
高质量医学教材提供专业知识保证
-
医疗网站提供实践场景补充
-
现有医疗语料库提供额外验证
Q2: 模型在生成解释(rationale)时如何保证准确性?评估标准是什么?
A: 模型的解释生成和评估采用了多维度方法:
- 评估指标:
-
BLEU得分:评估生成文本与参考答案的n-gram匹配度
-
ROUGE得分:同时考虑精确率和召回率
-
BERT-Score:评估语义层面的相似度
- 人工评分:
-
5位医学院研究生进行评估
-
评估维度包括:准确性、推理能力、知识整合
-
采用相对评分机制,6分制
- GPT-4辅助评估:
-
使用GPT-4作为额外评估者
-
与人工评分有较高相关性(相关系数0.660)
- 质量控制:
-
训练数据中的解释由GPT-4生成并经人工验证
-
测试集中94.7%的解释通过人工审核
Q3: MMed-Llama 3相比其他开源模型的主要优势在哪里?为什么能取得更好的效果?
A: MMed-Llama 3的优势主要体现在以下方面:
- 数据优势:
-
首个大规模多语言医疗语料库(25.5B tokens)
-
数据来源多样,覆盖面广
-
专业医学教材保证知识准确性
- 模型架构:
-
基于先进的Llama 3架构
-
保持了8B参数量的高效性
-
继承了基座模型的强大语言能力
- 训练策略:
-
两阶段训练:预训练+微调
-
多任务学习:选择题+解释生成
-
多语言平衡:考虑语言间的平衡
- 实验结果:
-
多语种任务平均准确率67.75%
-
英语医疗基准测试优于同规模模型
-
解释生成质量接近GPT-4
Q4: MMedBench基准测试的设计考虑了哪些因素?如何确保其全面性和代表性?
A: MMedBench的设计非常全面:
- 领域覆盖:
-
涵盖21个医学专业领域
-
从基础医学到临床医学
-
包括罕见病和常见病
- 语言分布:
-
平衡6种主要语言的题目数量
-
考虑各语言的医疗术语特点
-
保持跨语言的难度一致性
- 问题类型:
-
包含单选和多选题
-
配有详细解释说明
-
试题来源于真实医学考试
- 验证机制:
-
多位临床医生审核分类
-
GPT-4辅助生成解释
-
人工验证确保质量
Q5: 论文中提到的自回归训练(auto-regressive training)具体是如何实现的?有什么特殊的训练策略吗?
A: 自回归训练的具体实现包括:
- 数据处理:
-
文本分割为2048 tokens的块
-
块间重叠512 tokens
-
保持上下文连贯性
- 训练配置:
-
使用Fully Sharded Data Parallel (FSDP)策略
-
采用BF16数据类型
-
使用梯度检查点技术
- 超参数设置:
-
全局批量大小512
-
InternLM学习率2e-5
-
BLOOM学习率8e-6
-
训练20k次迭代(约20天)
- 优化目标: L ( p h i ) = − s u m l o g ( P h i ( x _ i ∣ x _ < i ) ) L(\\phi) = -\\sum \\log(\\Phi(x\_i|x\_{<i})) L(phi)=−sumlog(Phi(x_i∣x_<i))< section=“”></i}))$<>
Q6: 模型在实际临床应用中可能面临哪些挑战?论文提出了哪些解决方案?
A: 主要挑战和解决方案包括:
- 幻觉问题:
-
挑战:模型可能生成虚假医疗信息
-
解决:建议引入检索增强生成(RAG)机制
-
未来:扩大知识库覆盖范围
- 文化差异:
-
挑战:不同地区医疗实践存在差异
-
解决:多语言语料库包含本地化内容
-
建议:增加区域特定医疗指南
- 法律合规:
-
挑战:各国医疗法规不同
-
解决:语料库包含法规信息
-
建议:建立区域特定评估基准
- 伦理问题:
-
挑战:可能存在偏见
-
解决:严格的数据筛选
-
建议:增加多样性数据
Q7: 论文中提到的多语言能力是如何实现平衡的?各语言间的性能差异是否显著?
A: 多语言能力平衡通过以下方式实现:
- 数据平衡:
-
英语约10.56B tokens
-
中文约4.74B tokens
-
其他语言2-4B tokens不等
-
考虑语言使用频率和资源可得性
- 性能表现:
-
英语:66.06%
-
中文:79.25%
-
日语:61.81%
-
法语:55.63%
-
俄语:75.39%
-
西班牙语:68.38%
- 平衡策略:
-
高质量专业教材补充
-
本地化医疗网站内容
-
现有医疗语料库整合
Q8: 模型的解释能力(rationale)是如何训练得到的?为什么这个功能很重要?
A: 解释能力的训练和重要性:
- 训练方法:
-
使用GPT-4生成高质量解释
-
人工验证确保准确性
-
多任务学习框架
-
选择题答案和解释同时训练
- 重要性:
-
提高医疗决策透明度
-
辅助医生理解推理过程
-
帮助患者理解诊断结果
-
促进医学教育和培训
- 评估方式:
-
自动评估指标(BLEU/ROUGE/BERT-Score)
-
人工专家评分
-
GPT-4辅助评估
Q9: 针对论文提到的数据偏见问题,有什么具体的解决方案吗?
A: 数据偏见的解决方案包括:
- 短期措施:
-
严格的数据筛选标准
-
多源数据交叉验证
-
专家审核机制
-
持续监控和评估
- 中期规划:
-
扩大语言覆盖范围
-
增加低资源语言数据
-
改进数据采集方法
-
建立偏见检测工具
- 长期战略:
-
建立全球合作网络
-
开发自动偏见检测
-
构建更公平的评估基准
-
推动开放数据共享
Q10: 模型在不同医学专业领域的性能是否有显著差异?如何进一步提升薄弱领域的表现?
A: 领域性能差异和提升策略:
- 现有性能:
-
内科:13.5%的测试集,表现最好
-
生物化学:11.09%的测试集,表现次之
-
药理学:8.78%的测试集,表现中等
-
罕见专科:表现相对较弱
- 差异原因:
-
训练数据分布不均
-
专业知识深度不同
-
问题复杂度差异
-
临床实践要求不同
- 改进策略:
-
增加薄弱领域的训练数据
-
引入专门的领域专家知识
-
开发领域特定的评估指标
-
考虑分层训练策略
论文GitHub使用教程:MMedLM多语言医疗大模型论文复现指南
一、项目概述
1. 项目简介
本项目是Nature Communications发表的论文"Towards Building Multilingual Language Model for Medicine"的官方代码库。项目主要包含三个核心组件:
-
MMedC:25.5B tokens的多语言医疗语料库
-
MMedBench:多语言医疗问答基准数据集
-
MMed-Llama 3:基于以上资源训练的多语言医疗大模型
2. 相关资源链接
论文链接:
-
Arxiv版本:https://arxiv.org/abs/2402.13963
-
Nature Communications版本:https://www.nature.com/articles/s41467-024-52417-z
模型下载:
-
MMedLM-7B:https://huggingface.co/Henrychur/MMedLM
-
MMedLM 2-7B:https://huggingface.co/Henrychur/MMedLM2
-
MMedLM 2-1.8B:https://huggingface.co/Henrychur/MMedLM2-1.8B
-
MMed-Llama 3-8B:https://huggingface.co/Henrychur/MMed-Llama-3-8B
-
MMed-Llama3-8B-EnIns:https://huggingface.co/Henrychur/MMed-Llama-3-8B-EnIns
数据集:
-
MMedC:https://huggingface.co/datasets/Henrychur/MMedC
-
MMedBench:https://huggingface.co/datasets/Henrychur/MMedBench
二、环境配置
1. 硬件要求
-
GPU:A100 80GB
-
显存:至少需要8张A100 80GB GPU用于预训练
-
推荐使用Slurm调度系统
2. 软件依赖
基础环境:
# 主要依赖
torch==1.13.0
transformers==4.37.0
# LoRA微调额外依赖
peft # 版本根据transformers选择
三、代码结构
项目主要包含四个核心模块:
MMedLM/
├── pretrain/ # MMedC预训练代码
├── finetune/ # MMedBench微调代码
├── inference/ # 模型推理代码
├── data_collection/ # 数据收集pipeline
四、使用指南
1. 预训练阶段(Pretraining)
位置:pretrain/目录
主要步骤:
-
准备MMedC数据集
-
配置预训练参数
-
运行预训练脚本
注意事项:
-
需要至少8张A100 80GB GPU
-
预计训练时间超过一个月
-
详细使用说明参考
pretrain/README.md
2. 微调阶段(Fine-tuning)
位置:finetune/目录
支持两种微调方式:
-
全量微调(Full-Model Fine-tuning)
-
PEFT微调(Parameter-Efficient Fine-Tuning)
主要参数:
# 全量微调配置
global_batch_size = 128
learning_rate = 1e-6
data_type = "BF16"
# LoRA配置
rank = 16 # 默认推荐值
3. 推理阶段(Inference)
位置:inference/目录
功能:
-
在MMedBench测试集上进行模型评估
-
支持多语言医疗问答测试
-
可生成答案解释(rationale)
4. 数据收集Pipeline
位置:data_collection/目录
主要功能:
-
医疗数据过滤
-
教材OCR处理
-
可能需要安装额外OCR相关依赖
五、实验结果复现
1. 英语基准测试
模型在多个权威医疗基准上的表现:
-
MedQA
-
MedMCQA
-
PubMedQA
-
MMLU医学相关科目
2. 多语言评估
在MMedBench上评估模型的:
-
多选题准确率
-
解释生成质量(BLEU-1/ROUGE-1)
六、常见问题解答
- Q: 如何处理GPU显存不足问题? A: 可以考虑:
-
使用gradient checkpoint
-
减小batch size
-
使用PEFT而非全量微调
-
使用BF16数据类型
- Q: 预训练时间过长怎么办? A: 建议:
-
使用较小的模型版本(如1.8B)进行实验
-
使用预训练好的checkpoint
-
只训练部分数据验证流程
- Q: 数据集太大无法完整下载? A: 可以:
-
优先下载训练集子集
-
使用huggingface提供的streaming模式
-
联系作者获取alternative下载链接
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
## 大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 104
104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









