






目录
作为一名NLP&LLM练习生,记录一下自己入门踩的坑和遇到的问题,在这里记录自己成长的脚步。
1 照着教程一步步走,配好环境
我的本地环境是win11 + i5-14600KF + Nvidia 4070s 12GB显存。然后环境配置是基于anaconda的,IDE用pycharm。虚拟环境操作比较方便。这个配置的话本地对Meta-Llama-3-8B-Instruct模型进行LoRA微调是可以满足的,后续考虑用实验室的算力做实验了,10个3090爽yy。
1.1 硬件环境校验
打开cmd显示GPU当前状态和配置信息
nvidia-smi

比如我的是12.7,就表明我想安装的CUDA版本11.8,12.1,12.4都是可以的。

1.2 CUDA和Pytorch环境校验
先把微调框架代码pull下来
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
后面就该决定你的python+pytorch+CUDA版本了,由于python包之间版本有史一样的依赖关系,版本的选择真要谨慎。最开始我在配requirement这里卡了两天多。🤣🤣
1.2.1 根据其中一个最难安装的包决定版本。
flash-attention这个包是越来越难安了哈,就是它卡了我一两天,可恶。win版本的轮子地址如下:
https://github.com/bdashore3/flash-attention/releases
经过两天的摸索,flash-attention的包的选择最终决定的是这个,所以决定了python3.11 + CUDA12.1 + pytorch2.1.2 版本,

把这个轮子下载下来,放在某个你知道的路径。我的是都放在E:\wheels
1.3 安好环境
1.3.1 用setup.py
创建一个虚拟环境叫llama_factory,转换到该环境下安装环境,不过这里不用 pip install -r requirement.txt的方式,而是用pip install -e .[metrics]这样的语法,你问为什么,因为框架已经为我们写好了安装环境的setup.py脚本。😍😍
conda create -n llama_factory python=3.11
conda activate llama_factory
cd LLaMA-Factory
pip install -e .[metrics]
这里指定metrics参数是安装jieba分词库等,方面后续可能要训练或者微调中文数据集。
1.3.2 安装CUDA12.1 + pytorch2.1.2
然后还要安装CUDA12.1 + pytorch2.1.2,因为上述方式似乎默认安装了一个CPU版本的pytorch,而且版本也不是我们想要的,直接自己安装覆盖即可。
要注意的是这里安装的命令是torch历史版本里面找的,因为我们要安装老版本2.1的

conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidia
1.3.2 安装0.38.1版本的bitsandbytes
由于直接使用pip install bitsandbytes不可行,因为Requirements Python >=3.8. Linux distribution (Ubuntu, MacOS, etc.) + CUDA > 10.0.
因此需要自己下载编译安装。
git clone https://github.com/timdettmers/bitsandbytes.git
cd bitsandbytes
set CUDA_VERSION=121
make cuda12x
python setup.py install
1.3.3 安装2.4.1版本的flash-attention
刚才下载轮子的位置是E:\wheels,要根据自己下载位置给参数
pip install E:\wheels\flash_attn-2.4.1+cu121torch2.1cxx11abiFALSE-cp311-cp311-win_amd64.whl
环境到这里就安装好了,后面测试一下。
1.4 测试环境
1.4.1 测试一
项目根目录加一个test_env.py
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import torch
print("PyTorch Version:", torch.__version__)
print("CUDA Available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("CUDA Version:", torch.version.cuda)
print("Current CUDA Device Index:", torch.cuda.current_device())
print("Current CUDA Device Name:", torch.cuda.get_device_name(0))
else:
print("CUDA is not available on this system.")
然后console里面 python test_env.py,期望输出如下:
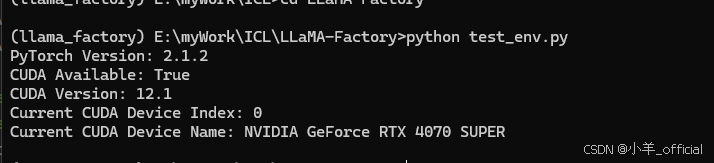
1.4.2 测试二
对本库的基础安装做一下校验,输入以下命令获取训练相关的参数指导, 否则说明库还没有安装成功
llamafactory-cli train -h
1.4.3 测试三
这里要先自己下载Llama-3-8B-Instruct模型,也是要用到绝对路径的。
git clone https://www.modelscope.cn/models/LLM-Research/Meta-Llama-3-8B-Instruct.git
cd Meta-Llama-3-8B-Instruct
git lfs pull
然后回到LLaMA-Factory文件夹下,根目录再加一个test_env1.py
# 跑一下官方raedme里提供的原始推理demo,验证模型文件的正确性和transformers库等软件的可用
import transformers
import torch
# 切换为你下载的模型文件目录, 这里的demo是Llama-3-8B-Instruct
# 如果是其他模型,比如qwen,chatglm,请使用其对应的官方demo
model_id = "E:\myWork\ICL\model\Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
没有报错并且生成输出了一段海盗措辞的船长回答那就说明环境没问题了。
2 原始模型直接推理
这里原文给的命令是适用于Linux命令行的,我们需要对应修改。
//linux
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--template llama3
win不支持CUDA_VISIBLE_DEVICES=0指定显卡,并且也不支持”\“换行console,分别对应修改:
对于第一个问题,一种方式是修改环境变量,在用户变量或者系统变量加一行就可以。CUDA_VISIBLE_DEVICES 0 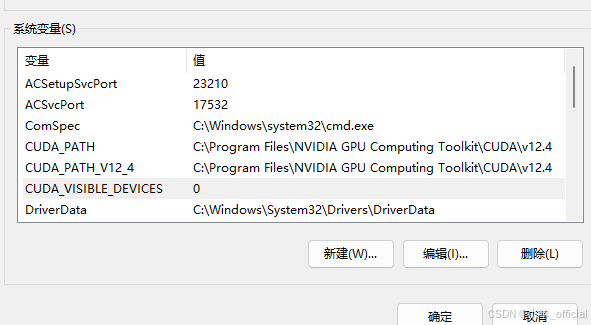
终端要重启,然后命令要换在一行,终端输入
llamafactory-cli webchat --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct --template llama3
另一种方式是终端提前输入一行
set CUDA_VISIBLE_DEVICES=0
llamafactory-cli webchat --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct --template llama3
除此之外,后面的参数指定是可以通过配置文件的,在E:\myWork\ICL\LLaMA-Factory\examples\inference路径下修改
llama3.yaml
model_name_or_path: E:\myWork\ICL\model\Meta-Llama-3-8B-Instruct
template: llama3
infer_backend: huggingface # choices: [huggingface, vllm]
则上述llamafactory-cli指令可以等价为(修改好环境变量后)
llamafactory-cli webchat E:\myWork\ICL\LLaMA-Factory\examples\inference\llama3.yaml
然后就可以通过本地主机的 http://localhost:7860/ 进行webui访问llama3模型了。

















 3764
3764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









