







Abstract
视觉问答(VQA)的关键解决方案在于如何融合从输入图像和问题中提取的视觉和语言特征。我们表明,一种能够在两种模式之间实现密集双向交互的注意机制有助于提高答案预测的准确性。具体来说,我们提出了一个在视觉和语言表达之间完全对称的简单体系结构,其中每个问题词出现在图像区域,每个图像区域出现在问题词上。它可以被堆叠以形成图像-问题对之间的多步骤交互的层次。我们通过实验表明,所提出的架构在VQA和VQA 2.0上实现了新的最先进的状态,尽管它的尺寸很小。我们还提供了定性评估,演示了所提出的注意机制如何在图像和问题上生成合理的注意图,从而得到正确的答案预测。
Introduction
VQA方法的进步主要分为两部分,一部分是提出更好的注意力机制和对从图片和文本中提出的特征进行更好的融合。一般而言这两部分分属于模型独立模块, 而本文认为两者是有联系的, 应该进行有机的结合, 一个好的注意力机制能够使得图片-问题对更好的融合。
作者提出了一种新的协同注意机制来改进视觉和语言表示的融合。给定图像和问题的表示形式,首先为每个问题单词生成图像区域上的注意图,并为每个图像区域生成问题单词上的注意图。然后计算想要得到的特征,然后将特征连接起来,输入一个带ReLU的单层神经网络,并且带有残差连接。他考虑所有区域和单词的关系,两个模态完全对称,并且可以叠加多步进行。
Related Work
Attention Mechanisms
Attention主要是分为两种,一种是使用由边缘框提供的部分区域,另一种是对图片进行卷积得到的特征。最开始研究主要集中在以问题为引导的对图片区域的注意力图,后来研究以图片区域为引导生成对问题的单词的注意力图。目前的研究只考虑有限的模态交互,比如Co-attention虽然考虑了问题中的每个单词,但是却使用的是整个图片。作者提出的注意力机制考虑了两种模态的交互,可能是能够建立两种模态的复杂关系。
Multimodal Feature Fusion
目前的方法主要是对图片和问题进行单独的提取特征,然后进行简单的模态融合,比如 concatenation, summation, and element-wise product。然后在进行分类。以下介绍三种融合方法
- MCB 是对两个向量进行外积(outer product)
- MLB 是对两个向量进行哈达玛积(Hadamard product)
- MFB 是使用矩阵分解的技巧进行参数减少和提高收敛速度。
注意机制也可以被认为是特征融合方法,不管它是否被明确地关注,因为它们被设计成基于它们的交互来获得图像-问题对的更好的表示。共同注意机制中,两个特征被对称地对待。作者提出的密集的共同关注网络就是基于这一观察。它通过注意力机制的多个应用来融合这两个特性,这些应用可以使用它们之间更细粒度的交互。
Dense Co-Attention Network (DCN)
如下就是DCN整个框架,它由一堆密集的共同关注层组成,这些层反复融合了语言和视觉特征,在这些层之上还有一个答案预测层,该层在多标签分类设置中预测答案。

Feature Extraction
Question and Answer Representation
使用双向LSTM来编码问题和答案。首先将N个单词的问题转化为GloVe向量序列,然后将其输入到双向LSTM且带残差连接的单层网络:

根据如上,我们生成一个矩阵,其中
,使用
得到输入的图片的表示。相似的按照如上方法编码答案。首先对M个单词转化为
,然后将其输入到双向LSTM。以
为答案的表示。
Image Representation
我们从四个conv层中提取特征,然后在这些层上使用问题引导的注意力来融合它们的特征。这样做是为了利用随后密集的共同关注层的最大潜力。作者推测,视觉表征层次中不同层次的特征对于正确回答一系列问题是必要的。
从四个conv中提取输出。这四个conv层是在最后四个池层之前的层(ReLU之后)。具体的大小分别为256 × 112 × 112,512 × 56 × 56, 1024 × 28 × 28 和2048 × 14 × 14,然后通过不同大小的最大池化和一对一的卷积层分别将其转化为相同的维度d× 14 × 14。还对每个张量的深度维度应用l2归一化。将归一化张量重塑为四个d × T矩阵,其中T = 14 × 14。
由上文中的的来生成对四个卷积层的注意力,使用一个有724个隐藏单元的两层神经网络,用ReLU非线性将
投影到四个层的分数上
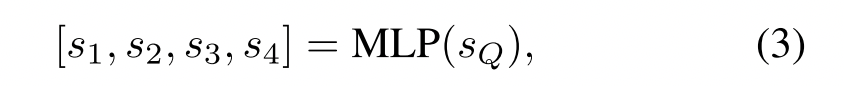
然后进行softmax归一化以获得四个注意力权重。计算上述四个矩阵的加权和,得到d×T矩阵
,这是我们对输入图像的表示。它将图像特征的第t个图像区存储在大小为d的第t列向量域。
Dense Co-Attention Layer
Overview of the Architecture
如下图所示,每一层的密集共同注意层,对问题Q和图片V的特征的一次更新。首先,这是一个共同关注的机制。第二,共同注意是密集的,因为它考虑了任何单词和任何区域之间的每一次互动。具体来说,这种机制为每个单词的区域创建一个注意图,为每个区域的单词创建一个注意图(见图3)。第三,它可以如图1所示堆叠.

Dense Co-attention Mechanism
Basic method for attention creation 给定一个问题Q和一个图片V,两个注意力图的产生如所图三所示:

计算公式如下: 其中是一个可学习的矩阵
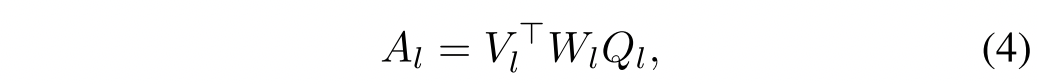
将我们将按行方向归一化,得到每个图像区域所对应的问题词的注意图:
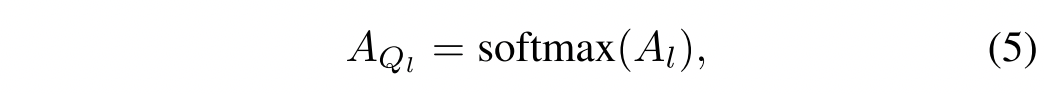
在列方向上对进行归一化,从而在每个问题词限定的图像区域上生成注意力图,注意
和
的每一行都包含一个单独的注意图。
![]()
Nowhere-to-attend and memory 在每个注意力地图的创建和应用过程中,经常会出现这样的情况:没有特定的区域或单词是模型应该关注的。针对整个情况,选择做法就是对问题和图像 进行增加K个元素。和
的增加提供了尺寸为(T +K) × (N+K)的
;
和
的大小分别为(T+K)×(N+K)和(N +K) × (T +K)。
Parallel attention 在之前的几项研究中,多个注意力地图被创建并以并行方式应用于目标特征,这提供了多个关注的特征,然后它们通过串联被融合。作者采用相似的方法,只不过将串联改为使用多头注意力的平均值。
首先将和
映射到h个更低维的空间,维度为
,其中
,
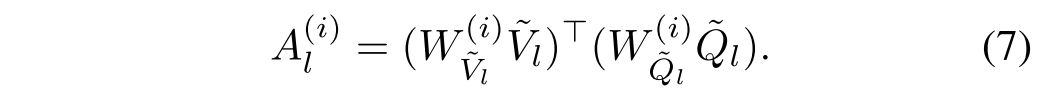
注意力图是通过按列和按行标准化从每个相似性矩阵创建的,如下所示

如下所述,当我们使用乘法(或点积)注意力时,多个关注特征的平均融合相当于平均我们的注意力图

Attended feature representations 根据存储在行中的注意力得到想要的特征,如图三中所示,现在(d×T),
(d×N),因为
(N×T),
(T×N).
Fusing Image and Question Representations
得到想要的目标之后就进行模态的融合。矩阵在其第n列中存储以第n个问题词为条件的整个图像的关注表示。然后,第n列向量
通过级联与第n个问题词的表示qln融合,以形成2d向量.这个连接的向量被一个单层网络投影回一个d维空间,接着是ReLU激活和残差连接。其中
,
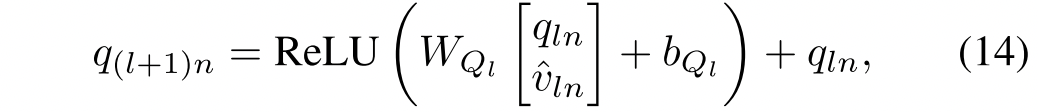
所以,新的问题的表示为.
相似的,第t个图像区域的表示与在第t个图像区域条件下的整个查询词的表示
连接,然后投影回d维空间,其中
,
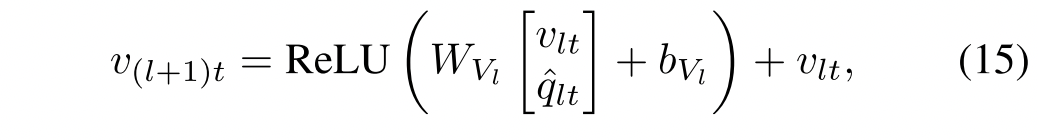
所以,新的图片 的表示为.
Answer Prediction
给定最后一个密集共同关注层的最终输出和
,我们预测答案。由于它们包含N个问题词和T个图像区域的表示,我们首先对它们中的每一个执行自我注意功能,以获得整个问题和图像的聚集表示。对于
来说如下:
- 通过在隐藏层中应用具有ReLU非线性的相同的两层MLP来计算对于
的分数
。
- 然后将softmax应用于它们,以获得注意力权重
。
- 计算聚集表示
相同的步骤能得到图像的聚集表示。然后利用一下三种方法来进行预测:
- 利用
和
的外积来计算答案的分数
,然后答案的表示为(最灵活的,因为它允许我们处理在训练整个网络时没有考虑到的任何答案)
![]()
- 使用MLP来计算一组预定义答案的分数,只不过融合方法不同,一种是两者相加
![]()
- 另一种是串联
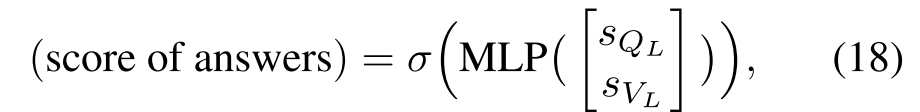
Experiments
1、使用开放式任务(VQA 2.0)的验证集对DCNs的每个模块进行消融研究。*表示最终模型中使用的模块。

2、提出的方法的结果,以及在类似条件下在VQA 1.0上发表的其他结果(即,单一模式;在没有外部数据集的情况下进行训练)

3、在类似条件下(即单一模型;在没有外部数据集的情况下训练)。DCN(数字)表示DCN配备了使用等式(数字)进行分数计算的预测层。*:使用外部数据集进行培训。* 2017年VQA挑战赛的获胜者,未发表
4、来自VQA 2.0数据集的补充图像问题对的关注图像区域和问题词的典型示例。每行包含两对相同问题的可视化,但图像和答案不同。原始图像和问题与它们在答案预测层中生成的注意力图一起显示。图像像素的亮度和单词的红色表示注意力的权重。















 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









