







0.摘要
本项目是史上最详细的、易理解的故障诊断学习项目,适合小白学习[项目中所有程序代码包含详细的注释*]。
本项目从原始信号处理,数据集制作,模型搭建,模型保存,特征可视化,混淆矩阵绘制等流程来帮助读者学习故障诊断。学懂本项目即可全面了解故障诊断的具体流程。
项目文件具体包含(以下所有程序文件均使用python语言和pytorch架构):
1. CWRU原始信号数据;
2. 数据预处理程序文件:该文件包含加载原始信号、样本采样、信号变换、信号归一化、样本打标签、生成训练集和测试集。
3. 自己搭建的诊断模型程序文件,CWRU同工况诊断准确率可达100%;
4. 模型训练与测试程序文件,该文件的功能包括:
(1)保存最佳诊断模型;
(2)保存最佳模型预测的分类标签;
(3)保存模型的训练过程,包括训练集的损失和准确率、测试集的损失和准确率,以及总的训练损失。
(4)项目使用经验风险最小化优化模型。
5. 绘制混淆矩阵的程序文件,该文件可以读取保存的预测标签并绘制混淆矩阵;
6. 模型测试与特征抽取的程序文件,该文件可以:
(1)加载4保存好的模型并进行测试模型的效果;
(2)抽取模型提取的某一层特征,以便于特征可视化;
7. 特征可视化程序文件,该文件可以加载6抽取好的特征进行t-SNE可视化。
8. 本项目包含详细的程序说明文档,文档内容包括:数据集介绍、数据预处理过程介绍、模型结构与详细参数介绍、所有程序文件概述。
1.数据集介绍
1.1试验台介绍
CWRU凯斯西储大学数据集包括四种轴承不同轴承健康状态,即正常状态、内圈故障、外圈故障和滚动体故障。分别有7mils、14mils和21mils三种故障直径(1mils=0.0254mm)。该电动机在0hp、1hp、2hp、3hp四种不同的负载和1730r/min、1750r/min、1772r/min、1797r/min四种不同转速下收集振动信号。

1.2采集信号样本介绍
(1)正常数据样本
| Motor Load (HP) | Approx. Motor Speed (rpm) | Normal Baseline Data |
| 0 | 1797 | 97.mat |
| 1 | 1772 | 98.mat |
| 2 | 1750 | 99.mat |
| 3 | 1730 | 100.mat |
(2)故障数据样本
| 故障直径 | 电机负载 (HP) | 电机 转速 (rpm) | 内圈 故障 | 滚珠故障 | 外圈故障 | ||
| Centered | Orthogonal | Opposite | |||||
| 0.007" | 0 | 1797 | 105.mat | 118.mat | 130.mat | 144.mat | 156.mat |
| 1 | 1772 | 106.mat | 119.mat | 131.mat | 145.mat | 158.mat | |
| 2 | 1750 | 107.mat | 120.mat | 132.mat | 146.mat | 159.mat | |
| 3 | 1730 | 108.mat | 121.mat | 133.mat | 147.mat | 160.mat | |
| 0.014" | 0 | 1797 | 169.mat | 185.mat | 197.mat | * | * |
| 1 | 1772 | 170.mat | 186.mat | 198.mat | * | * | |
| 2 | 1750 | 171.mat | 187.mat | 199.mat | * | * | |
| 3 | 1730 | 172.mat | 188.mat | 200.mat | * | * | |
| 0.021" | 0 | 1797 | 209.mat | 222.mat | 234.mat | 246.mat | 258.mat |
| 1 | 1772 | 210.mat | 223.mat | 235.mat | 247.mat | 259.mat | |
| 2 | 1750 | 211.mat | 224.mat | 236.mat | 248.mat | 260.mat | |
| 3 | 1730 | 212.mat | 225.mat | 237.mat | 249.mat | 261.mat | |
2.数据预处理
数据预处理部分主要是将原始信号划分为训练集和测试集,以用于训练模型。该部分包括:
- 加载原始信号,从.mat原始数据中加载信号数据;
- 信号分割,即将原始信号分割为多个样本;
- 信号变换,将时域信号转换为频域信号;
- 信号归一化,将信号进行归一化处理;
- 信号重塑,将信号转换为[batch, channel, height, weight]的数据,以便于输入卷积模型;
- 数据集生成,将每个类别的样本和标签进行拼接,组成一个完成的训练集。
2.1加载原始信号
从mat文件中加载原始的信号,如下图所示。
图1. 原始信号
2.2信号分割
从原始信号中随机采样n个样本长度为1024的样本,如下图所示。
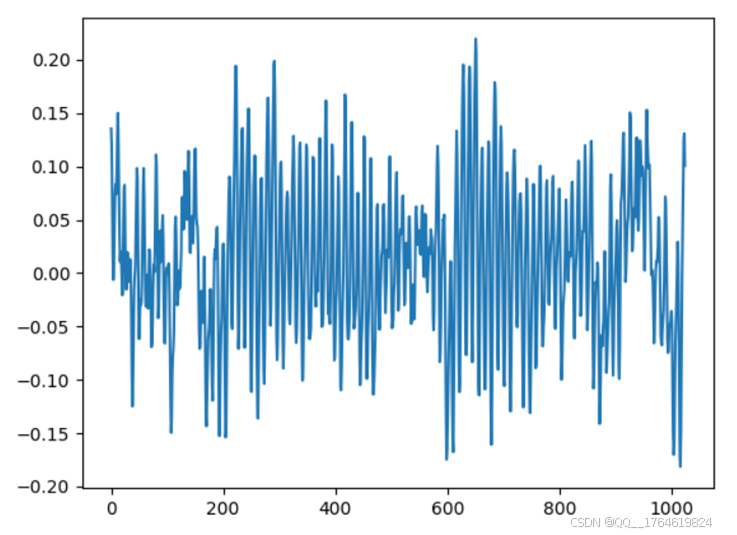
图2. 截取的单个样本信号
2.3对原始信号进行FFT变换
图3. 时域信号变换为频域信号
2.4信号重塑
将长度为[1024]的一维频域信号重塑为[32, 32]的二维信号,如下图所示。

图5. 二维信号
3.模型介绍
3.1模型结构介绍
本项目使用的轻量化模型主要由标准卷积(Conv1和Conv2)、轻量化特征提取块(Block1和Block2)和分组卷积GC组成,如图6所示。
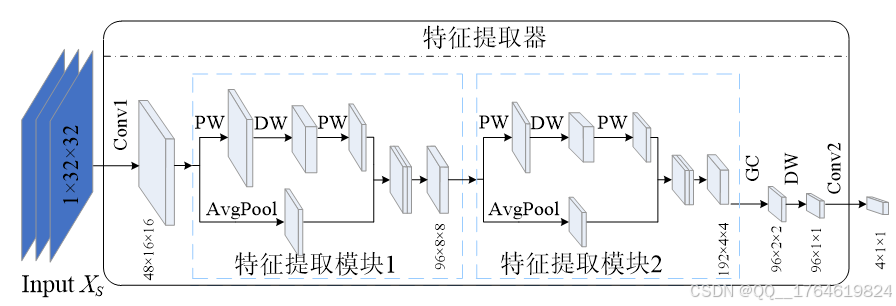
图6. 诊断模型结构
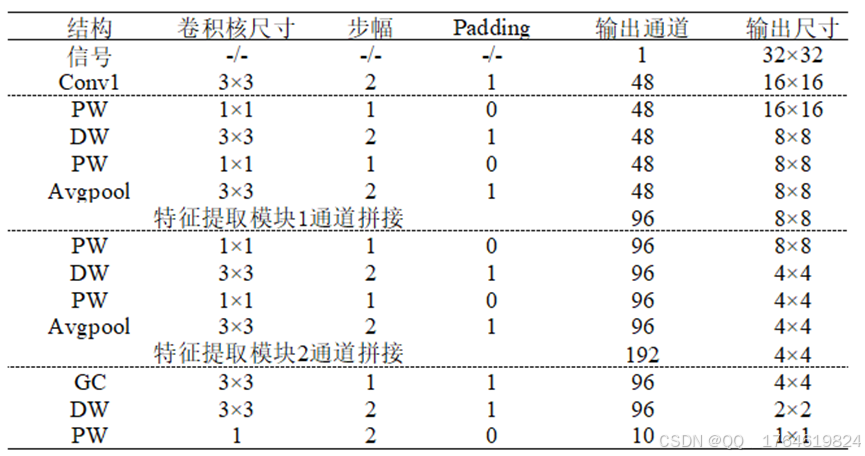
3.2模型结构参数介绍
具体的模型结构如表1所示,如果不理解可以查看ShuffleNet参考文献。
表1. 诊断模型详细结构参数
4.程序介绍
4.1 CWRU_original_data文件夹
该文件夹包含了第2章介绍的原始信号数据。
4.2 Data_processing文件夹
数据预处理文件夹
- Data_Preprocessing.py:从采集的原始数据集中读取数据,划分训练集和测试集,并进行频域相关变换等。
- Data_Preprocessing_API_functions.py:数据预处理接口函数,包含FFT变换,STFT变换等,建议使用:FFT变换。
4.3 CWRU_dataset文件夹
由3.2生成的训练集和测试集。
4.4 models文件夹
- SCARA_res_net.py:故障诊断主干模型
- SCARA_res_blo.py: 主干模型的特征提取模块
4.5 ERM_main.py
该文件为主函数,运行该文件可以训练和测试模型,并且可以保存训练好的模型,保存模型输出的预测标签,以便于绘制混淆矩阵。此外,该文件可以保存模型的训练历史记录,包括训练集的准确率和损失,测试集的准去率和损失。
4.6 save_dir文件夹
该文件夹包含训练的历史记录与保存的最佳模型。
4.7 ConfusionMatrix文件夹
- predicted_label文件夹:包含了模型输出的预测标签。
- Confusion_matrix_plot.py:根据预测标签与真实标签画混淆矩阵。
绘制的混淆矩阵如下:
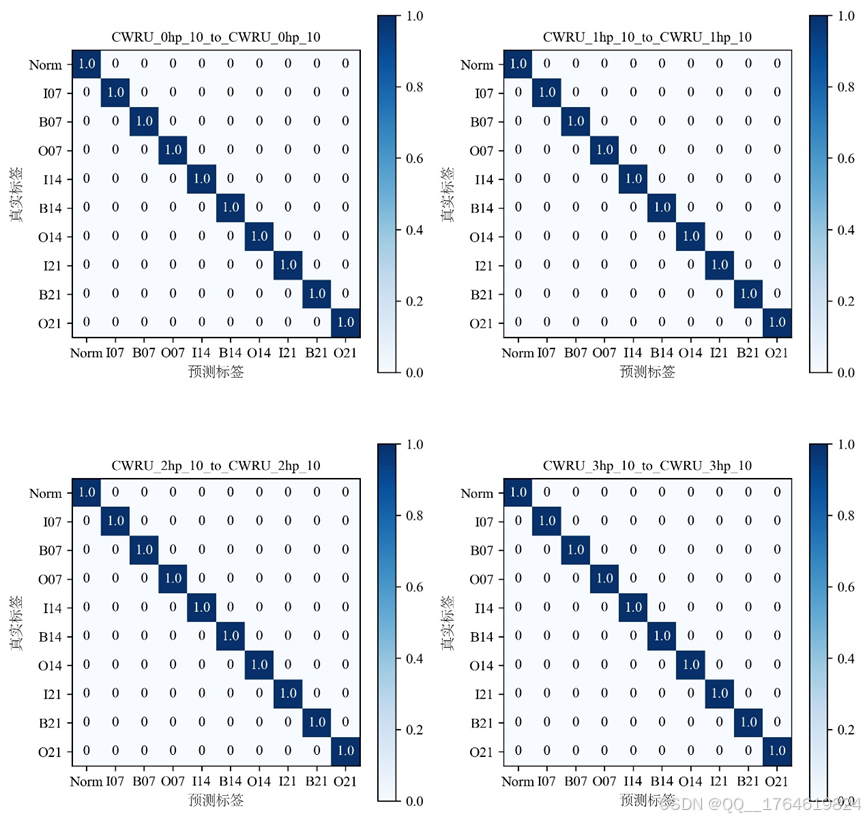
图7. 混淆矩阵
4.8 load_model_and_extract_features文件夹
- load_model_and_filter_features.py:加载一个文件夹中的所有模型,并提取所有模型的某一层的特征。
4.9 t-SNE文件夹
- features文件夹:由3.8加载模型并抽取的模型某一层的特征。
- t-SNE_for_feature_visualization.py:对模型提取的特征进行可视化。
绘制的特征可视化结果如下图所示。
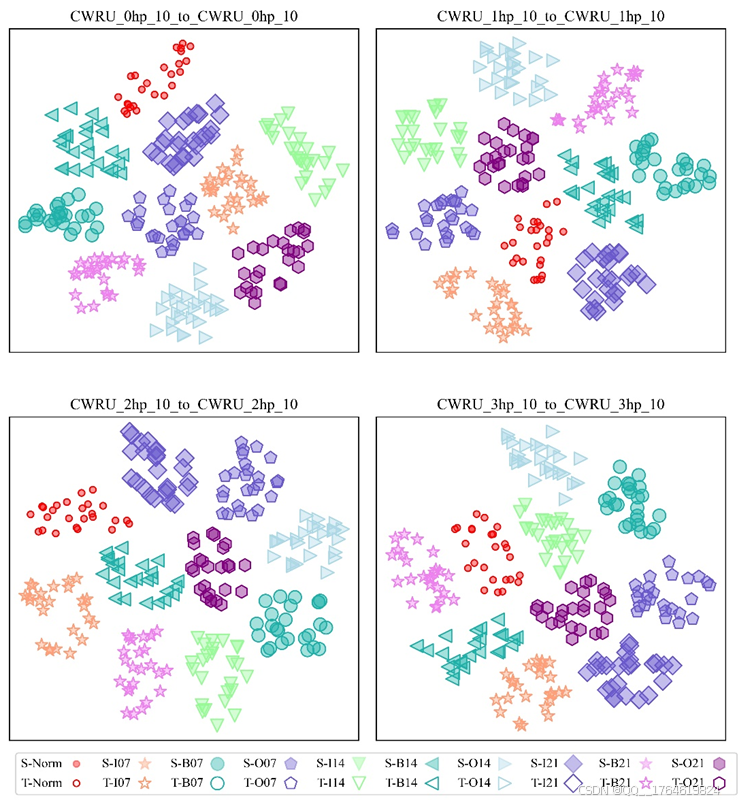
图8. 不同任务之间的特征可视化结果
4.10 utils_dsbn文件夹
此文件夹为一些小函数,了解保存模型训练数据的save_other_functions.py文件即可。


















 2674
2674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











