






Gaussian Shell Maps for Efficient 3D Human Generation
基于高斯壳映射的高效三维人体生成
Rameen Abdal *1 王一凡 *1 Zifan Shi *†1,2 Yinghao Xu 1 Ryan Po 1 Jengfei Kuang 1
Qifeng Chen2 Dit-Yan Yeung2 Gordon Wetzstein1
陈琪峰 2 杨彦彦 2 Gordon Wetzstein 1
1Stanford University 2HKUST
1 斯坦福大学 2 科大
Abstract 摘要 [2311.17857] Gaussian Shell Maps for Efficient 3D Human Generation
Efficient generation of 3D digital humans is important in several industries, including virtual reality, social media, and cinematic production. 3D generative adversarial networks (GANs) have demonstrated state-of-the-art (SOTA) quality and diversity for generated assets. Current 3D GAN architectures, however, typically rely on volume representations, which are slow to render, thereby hampering the GAN training and requiring multi-view-inconsistent 2D upsamplers. Here, we introduce Gaussian Shell Maps (GSMs) as a framework that connects SOTA generator network architectures with emerging 3D Gaussian rendering primitives using an articulable multi shell–based scaffold. In this setting, a CNN generates a 3D texture stack with features that are mapped to the shells. The latter represent inflated and deflated versions of a template surface of a digital human in a canonical body pose. Instead of rasterizing the shells directly, we sample 3D Gaussians on the shells whose attributes are encoded in the texture features. These Gaussians are efficiently and differentiably rendered. The ability to articulate the shells is important during GAN training and, at inference time, to deform a body into arbitrary user-defined poses. Our efficient rendering scheme bypasses the need for view-inconsistent upsamplers and achieves high-quality multi-view consistent renderings at a native resolution of 512×512 pixels. We demonstrate that GSMs successfully generate 3D humans when trained on single-view datasets, including SHHQ and DeepFashion.
高效生成3D数字人在包括虚拟现实、社交媒体和电影制作在内的多个行业中非常重要。3D生成对抗网络(GAN)已经证明了生成资产的最先进(SOTA)质量和多样性。然而,当前的3D GAN架构通常依赖于渲染缓慢的体积表示,从而妨碍GAN训练并需要多视图不一致的2D上采样器。在这里,我们介绍高斯壳映射(GSMs)作为一个框架,连接SOTA生成器网络架构与新兴的3D高斯渲染原语使用一个可连接的多壳为基础的支架。在此设置中,CNN生成3D纹理堆栈,其中包含映射到壳的特征。后者表示处于规范身体姿势的数字人的模板表面的充气和放气版本。 而不是光栅化的外壳直接,我们采样的外壳,其属性编码在纹理特征的3D高斯。这些高斯分布被有效地和可微地呈现。在GAN训练期间,以及在推理时,将身体变形为任意用户定义的姿势的能力很重要。我们的高效渲染方案绕过了对视图不一致上采样器的需求,并以 512×512 像素的原生分辨率实现了高质量的多视图一致渲染。我们证明了GSM在单视图数据集(包括SHHQ和DeepFashion)上训练时成功地生成了3D人类。
Project Page: rameenabdal.github.io/GaussianShellMaps
项目页面:rameenabdal.github.io/GaussianShellMaps
![[Uncaptioned image]](https://img-blog.csdnimg.cn/img_convert/f866049c74b2f08fcd5bedc19a1e7b08.png)
Figure 1:Gaussian Shell Maps. Gaussian Shell Maps is an efficient framework for 3D human generation connecting 3D Gaussians with CNN-based generators. 3D Gaussians are anchored to “shells” derived from the SMPL template [36] (only two shells are visualized for clarity), and the appearance is modeled in texture space. Trained only on 2D images, we show that our method can generate diverse articulable humans in real-time with state-of-the-art quality directly in high resolution without the need for upsampling and hence avoiding aliasing artifacts.
图1:高斯壳映射。Gaussian Shell Maps是一个用于3D人体生成的有效框架,将3D Gaussians与基于CNN的生成器连接起来。3D高斯被锚定到从SMPL模板[36]导出的“壳”(为了清晰起见,仅可视化了两个壳),并且外观在纹理空间中建模。仅在2D图像上进行训练,我们证明了我们的方法可以直接以高分辨率实时生成具有最先进质量的各种发音人,而无需上采样,从而避免了混叠伪影。
1Introduction 1介绍
00* Equal Contribution * 同等贡献00† Work done as a visiting student researcher at Stanford University
† 在斯坦福大学担任访问学生研究员
The ability to generate articulable three-dimensional digital humans augments traditional asset creation and animation workflows, which are laborious and costly. Such generative artificial intelligence–fueled workflows are crucial in several applications, including communication, cinematic production, and interactive gaming, among others.
生成可表达的三维数字人的能力增强了传统的资产创建和动画工作流程,这些工作流程既费力又昂贵。这种生成式人工智能驱动的工作流程在多个应用中至关重要,包括通信、电影制作和交互式游戏等。
3D Generative Adversarial Networks (GANs) have emerged as the state-of-the-art (SOTA) platform in this domain, enabling the generation of diverse 3D assets at interactive framerates [41, 6, 23, 76, 15, 8, 71, 76]. Most existing 3D GANs build on variants of volumetric scene representations combined with neural volume rendering [65]. However, volume rendering is relatively slow and compromises the training of a GAN, which requires tens of millions of forward rendering passes to converge [11]. Mesh–based representations building on fast differentiable rasterization have been proposed to overcome this limitation [19, 71], but these are not expressive enough to realistically model features like hair, clothing, or accessories, which deviate significantly from the template mesh. These limitations, which are largely imposed by a tradeoff between efficient or expressive scene representations, have been constraining the quality and resolution of existing 3D GANs. While partially compensated for by using 2D convolutional neural network (CNN)–based upsamplers [22, 11], upsampling leads to multi-view inconsistency in the form of aliasing.
3D生成对抗网络(GAN)已成为该领域最先进的(SOTA)平台,能够以交互式帧率生成各种3D资产[41,6,23,76,15,8,71,76]。大多数现有的3D GAN建立在体积场景表示与神经体积渲染相结合的变体上[65]。然而,体积渲染相对较慢,并且会影响GAN的训练,这需要数千万次前向渲染才能收敛[11]。已经提出了基于快速可微光栅化的基于网格的表示来克服这种限制[19,71],但这些表示不足以真实地建模头发,衣服或配饰等特征,这些特征明显偏离模板网格。这些限制在很大程度上是由高效或富有表现力的场景表示之间的权衡所造成的,一直制约着现有3D GAN的质量和分辨率。 虽然通过使用基于2D卷积神经网络(CNN)的上采样器进行部分补偿[22,11],但上采样导致混叠形式的多视图不一致。
Very recently, 3D Gaussians have been introduced as a promising neural scene representation offering fast rendering speed and high expressivity [28]. While 3D Gaussians have been explored in the context of single-scene overfitting, their full potential in generative settings has yet to be unlocked. This is challenging because it is not obvious how to combine SOTA CNN-based generators [26, 27] with 3D Gaussian primitives that inherently do not exist on a regular Cartesian grid and that may vary in numbers.
最近,3D高斯被引入作为一种有前途的神经场景表示,提供快速渲染速度和高表现力[28]。虽然3D高斯模型已经在单场景过拟合的背景下进行了探索,但它们在生成环境中的全部潜力尚未被释放。这是具有挑战性的,因为如何将基于联合收割机的SOTA CNN生成器[26,27]与固有地不存在于规则笛卡尔网格上并且可能在数量上变化的3D高斯基元组合并不明显。
We introduce Gaussian Shell Maps (GSMs), a 3D GAN framework that intuitively connects CNN generators with 3D Gaussians used as efficient rendering primitives. Inspired by the traditional computer graphics work on shell maps [47], GSMs use the CNN generator to produce texture maps for a set of “shell” meshes appropriately inflated and deflated from the popular SMPL mesh template for human bodies [36]. The textures on the individual shells directly encode the properties of 3D Gaussians, which are sampled on the shell surfaces at fixed locations. The generated images are rendered using highly efficient Gaussian splatting, and articulation of these Gaussians can be naturally enabled through deforming the scaffolding shells with the SMPL model. Since 3D Gaussians have spatial extent, they represent details on, in between, and outside the discrete shells. GSMs are trained exclusively on datasets containing single-view images of human bodies, such as SHHQ [17].
我们介绍高斯壳映射(GSMs),这是一个3D GAN框架,直观地将CNN生成器与用作高效渲染基元的3D高斯连接起来。受传统计算机图形学在壳图上的工作的启发[47],GSM使用CNN生成器为一组“壳”网格生成纹理图,这些网格从人体的流行SMPL网格模板适当地膨胀和收缩[36]。单个壳上的纹理直接编码3D高斯的属性,这些属性在固定位置的壳表面上进行采样。生成的图像使用高效的高斯溅射渲染,并且可以通过使用SMPL模型使脚手架壳变形来自然地启用这些高斯的接合。由于3D高斯具有空间范围,因此它们表示离散壳上、之间和外部的细节。GSM专门在包含人体单视图图像的数据集上进行训练,例如SHHQ [17]。
Our experiments demonstrate that GSM can generate highly diverse appearances, including loose clothing and accessories, at high resolution, without an upsampler, at a state-of-the-art rendering speed of 125 FPS (or 35FPS including generation). Among various architecture design choices, multiple shells with fixed relative locations of the 3D Gaussian achieve the best results in our experiments.
我们的实验表明,GSM可以以高分辨率生成高度多样化的外观,包括宽松的衣服和配饰,无需上采样器,最先进的渲染速度为125 FPS(或35 FPS,包括生成)。在各种结构设计选择中,具有固定的3D高斯相对位置的多个壳在我们的实验中获得了最好的结果。
Specifically, our contributions include
具体而言,我们的贡献包括
- 1.
We propose a novel 3D GAN framework combining a CNN-based generator and 3D Gaussian rendering primitives using shell maps.
1.我们提出了一种新的3D GAN框架,结合了基于CNN的生成器和使用壳映射的3D高斯渲染基元。 - 2.
We demonstrate the fastest 3D GAN architecture to date, achieving real-time rendering of 5122 px without convolutional upsamplers, with image quality and diversity matching the state of the art on challenging single-view datasets of human bodies.
2.我们展示了迄今为止最快的3D GAN架构,在没有卷积上采样器的情况下实现了 5122 px的实时渲染,图像质量和多样性与具有挑战性的人体单视图数据集的最新技术水平相匹配。
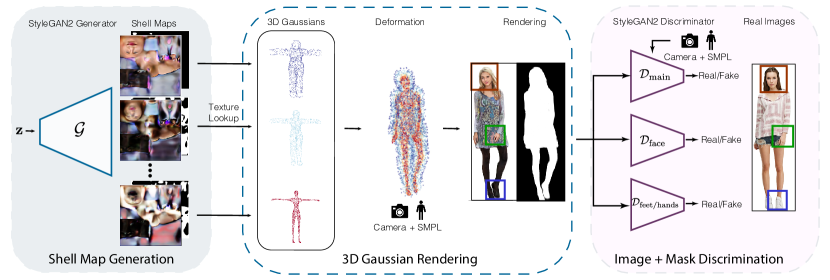
Figure 2:Method Overview. We propose an expressive yet highly efficient representation, Gaussian Shell Map (GSM), for 3D human generation. Combining the idea of 3D Gaussians and Shell Maps (Sec. 3), we sample 3D Gaussians on “shells”, which are mesh layers offsetted from the SMPL template, forming a shell volume to model complex and diverse geometry and appearance; the Gaussian parameters are learned in the texture space, allowing us to leverage existing CNN-based generative architecture (Sec. 4.1). Articulation is straightforward by interpolating the deformation of the shell (Sec. 4.2). The generation is supervised by single-view 2D images using several discriminator critics, including part-specific face, hands, and feet discriminators (Sec. 4.3).
图2:方法概述。我们提出了一种高效的表达,高斯壳映射(GSM),三维人体生成。结合3D高斯和壳映射的想法(第二节)。3),我们在“壳”上采样3D高斯,壳是从SMPL模板偏移的网格层,形成壳体积来模拟复杂和多样化的几何形状和外观;高斯参数在纹理空间中学习,使我们能够利用现有的基于CNN的生成架构(第2节)。4.1)。通过内插壳体的变形,关节连接是简单的(第2节)。4.2)。生成过程由单视图2D图像进行监督,使用几个识别器,包括特定部位的面部、手部和脚部识别器(第二节)。4.3)。
2Related Work 2相关工作
3D-Aware Generative Models.
3D感知生成模型。
GANs and diffusion models are two very powerful generative models emerging as a result of efficient architectures and high-quality datasets [25, 48]. With the quality of image generation reaching photo-realism, the community started leveraging these SOTA generative models for 3D generation by combining neural rendering methods [64, 65] to produce high-quality multi-view consistent 3D objects from image collections. Several 3D GAN architectures have explored implicit or explicit neural volume representations for modeling 3D objects, including [57, 10, 39, 40, 11, 22, 69, 42, 62, 59, 70, 2, 14]. 3D diffusion models, on the other hand, typically use the priors encoded by pre-trained text-to-image 2D diffusion models, e.g. [53, 4, 51, 44, 29, 7, 9, 33, 12, 66, 8, 46, 34] (see this survey for more details [45]). Due to the lack of high-quality, large-scale multi-view datasets curated for specific categories like humans, the choice of a suitable generative model becomes critical. Using diffusion models to generate high-resolution multi-view consistent 3D objects is still an unsolved problem [45]. 3D GANs, on the other hand, exhibit better quality and multi-view consistency at higher resolutions that do not assume multi-view data [71, 15, 11, 62]. This motivates our choice of building an efficient representation using a 3D GAN framework.
GAN和扩散模型是两个非常强大的生成模型,由于高效的架构和高质量的数据集而出现[25,48]。随着图像生成的质量达到照片现实主义,社区开始利用这些SOTA生成模型,通过结合神经渲染方法[64,65]从图像集合中生成高质量的多视图一致的3D对象。几种3D GAN架构已经探索了用于建模3D对象的隐式或显式神经体积表示,包括[57,10,39,40,11,22,69,42,62,59,70,2,14]。另一方面,3D扩散模型通常使用由预训练的文本到图像2D扩散模型编码的先验,例如[53,4,51,44,29,7,9,33,12,66,8,46,34](更多细节请参见本调查[45])。由于缺乏针对人类等特定类别的高质量、大规模多视图数据集,选择合适的生成模型变得至关重要。 使用扩散模型来生成高分辨率多视图一致的3D对象仍然是一个未解决的问题[45]。另一方面,3D GAN在不假设多视图数据的更高分辨率下表现出更好的质量和多视图一致性[71,15,11,62]。这促使我们选择使用3D GAN框架构建有效的表示。
Generative Articulated 3D Digital Humans.
3D数字人(3D Digital Humans)
3D-GAN frameworks have been proposed to generate the appearance, geometry, and identity-preserving novel views of digital humans [6, 71, 23, 74, 76, 15, 13, 72]. Most of these GANs are trained on single-view image collections [35, 32, 16]. A popular approach is to use a neural radiance representation [6, 41, 24, 74, 23] where a canonically posed human can be articulated via deformation. Other approaches are based on meshes, where a template can be fixed or learned during the training [19, 72, 63, 3, 18]. Related to this line of work, a concurrent paper, LSV-GAN [71], offsets the SMPL template meshes into layered surfaces and composites the per-layer rasterization result to form the final rendering. While it provides a faster alternative to the volume rendering-based approaches, it can only accommodate a small offset from the SMPL mesh, which hampers diversity. Our GSM method differs from LSV-GAN as we employ 3D Gaussians [28] as primitives on the layered surfaces, which, by having a learnable spatial span, allows for larger deviation from the template mesh and can thus generate more intricate details.
已经提出了3D-GAN框架来生成数字人的外观,几何形状和身份保留的新视图[6,71,23,74,76,15,13,72]。大多数GAN都是在单视图图像集合上训练的[35,32,16]。一种流行的方法是使用神经辐射表示[6,41,24,74,23],其中可以通过变形来表达标准姿势的人。其他方法基于网格,其中模板可以在训练期间固定或学习[19,72,63,3,18]。与这一系列工作相关的是一份并发论文LSV-GAN [71],它将SMPL模板网格偏移到分层表面中,并合成每层光栅化结果以形成最终渲染。虽然它提供了一个更快的替代体渲染为基础的方法,它只能容纳一个小的偏移SMPL网格,这妨碍了多样性。 我们的GSM方法与LSV-GAN不同,因为我们采用3D高斯[28]作为分层表面上的基元,通过具有可学习的空间跨度,允许与模板网格有更大的偏差,从而可以生成更复杂的细节。
Point-Based Rendering. 基于点的渲染。
Earlier point-based methods efficiently render point clouds and rasterize them by fixing the size [20, 21, 54]. While efficient in terms of speed and parallel rasterization on graphics processing units [56, 31], they are not differentiable [49, 28]. To combine these methods with the neural networks and perform view synthesis, recent works have developed differentiable point-based rendering techniques [73, 67, 52, 1, 68, 75, 77]. More recently, 3D Gaussian-based point splatting gained traction due to the flexibility of anisotropic covariance and density control with efficient depth sorting [28]. This allows 3D Gaussian splats to handle complex scenes composed of high and low-frequency features. Relevant to human bodies, 3D Gaussians have also been used in pose estimation and tracking [38, 61, 50]. While the Gaussian primitives have been used for efficient scene reconstruction and novel view synthesis, it is not trivial to deploy Gaussians in a generative setup. To the best of our knowledge, our method is the first to propose a combination of 3D Gaussians and 3D GANs.
早期的基于点的方法有效地渲染点云,并通过固定大小对它们进行光栅扫描[20,21,54]。虽然在图形处理单元上的速度和并行光栅化方面是有效的[56,31],但它们是不可区分的[49,28]。为了将这些方法与神经网络联合收割机结合并执行视图合成,最近的工作已经开发了基于可微分点的渲染技术[73,67,52,1,68,75,77]。最近,由于各向异性协方差和密度控制的灵活性以及有效的深度排序,基于3D高斯的点溅射获得了牵引力[28]。这允许3D高斯splats处理由高频和低频特征组成的复杂场景。与人体相关,3D高斯也被用于姿态估计和跟踪[38,61,50]。虽然高斯基元已被用于高效的场景重建和新颖的视图合成,但在生成设置中部署高斯并不是微不足道的。 据我们所知,我们的方法是第一个提出3D高斯和3D GAN的组合。

Figure 3:Novel Views and Animation. We can render a generated identity in novel views and articulate it for animations.
图3:新颖的视图和动画。我们可以在新的视图中呈现生成的身份,并将其表达为动画。
3Background 3背景
3D Gaussians. 3D高斯模型
These point-based primitives can be differentiably and efficiently rendered using EWA (elliptical weighted average) volume splatting [78]. 3D Gaussians have recently demonstrated outstanding expressivity for 3D scene reconstruction [28], in which the Gaussian parameters, position 𝐱∈ℝ3, opacity �∈ℝ, color 𝐜∈ℝ�ℎ (�ℎ representing the spherical harmonic coefficients), scaling 𝐬∈ℝ3 , and rotation 𝐪∈ℝ4 parameterized as quaternions are jointly optimized to minimize the photometric errors of the rendered images in a set of known camera views. The optimization is accompanied by adaptive control of the density, where the points are added or removed based on the density, size, and gradient of the Gaussians.
这些基于点的基元可以使用EWA(椭圆加权平均)体积溅射[78]进行区分和有效渲染。3D高斯最近已经证明了3D场景重建的出色表现力[28],其中高斯参数,位置 𝐱∈ℝ3 ,不透明度 �∈ℝ ,颜色 𝐜∈ℝ�ℎ ( �ℎ 表示球谐系数),缩放 𝐬∈ℝ3 ,旋转 𝐪∈ℝ4 被参数化为四元数的多个相机视图被联合优化,以最小化一组已知相机视图中的渲染图像的光度误差。优化伴随着密度的自适应控制,其中基于高斯的密度、大小和梯度来添加或移除点。
Specifically, each Gaussian is defined as
具体地,每个高斯被定义为:
| �(𝐱′;𝐱,Σ)=exp−12(𝐱′−𝐱)⊺Σ−1(𝐱′−𝐱), | (1) |
where Σ=������ is the covariance matrix parameterized by the rotation and scaling matrices � and � given by the quaternions 𝐪 and scaling 𝐬.
其中 Σ=������ 是由四元数 𝐪 和缩放 𝐬 给出的旋转和缩放矩阵 � 和 � 参数化的协方差矩阵。
The image formation is governed by classic point-based �-blending of overlapping Gaussians ordered from closest to farthest [30]:
图像形成由从最近到最远排序的重叠高斯的经典基于点的 � 混合控制[30]:
| 𝐂=∑�∈𝒩𝐜�′��′∏�=1�−1(1−�𝐣), | (2) |
where color 𝐜�′ and opacity ��′ is computed by
其中,颜色 𝐜�′ 和不透明度 ��′ 由下式计算:
| 𝐜�′=�(𝐱′;𝐱�)𝐜�and��′=�(𝐱′;𝐱�)��. | (3) |
Thanks to their ability to fit complex geometry and appearance, 3D Gaussians are gaining popularity for 3D scene reconstruction. However, deploying 3D Gaussians for generative tasks remains an unexplored topic and is challenging for several reasons. First, Gaussians are of “Lagrangian” nature – their sparse number and learnable positions are challenging to combine with SOTA “Eulerian” (i.e., grid-based) CNN generators. Second, the parameters of Gaussians are highly correlated. The same radiance field can be equally well explained by many different configurations of Gaussians, varying their locations, sizes, scales, rotations, colors, and opacities. This ambiguity makes it challenging to generalize over a distribution of objects or scenes, which generative methods do.
由于它们能够适应复杂的几何形状和外观,3D高斯模型在3D场景重建中越来越受欢迎。然而,为生成任务部署3D高斯仍然是一个未探索的主题,并且由于几个原因而具有挑战性。首先,高斯函数具有“拉格朗日”性质--它们的稀疏数和可学习位置联合收割机SOTA“欧拉”(即,基于网格的)CNN生成器。第二,高斯分布的参数是高度相关的。同样的辐射场也可以用不同的高斯分布来解释,这些高斯分布可以改变它们的位置、大小、尺度、旋转、颜色和不透明度。这种模糊性使得在对象或场景的分布上进行概括具有挑战性,而生成方法正是这样做的。
Shell Maps. 壳贴图。
Our representation is related to Shell Maps [47, 14, 58], a technique in computer graphics designed to model near-surface details. Shell maps use 3D texture maps to store the fine-scale features in a shell-like volume close to a given base surface, typically represented as a triangle mesh. In essence, they extend UV maps such that every point in the shell volume can be bijectively mapped to the 3D texture map for efficient modeling and rendering in texture space. The shell volume is constructed by offsetting the base mesh along the normal direction while maintaining the topology and avoiding self-intersection. The volume is discretized into tetrahedra that connect the vertices of the base and offset meshes. A unique mapping between the shell space and the texture space can be established by identifying the tetrahedron and subsequently querying the barycentric coordinates inside it. Formally, the mapping from 𝐱 in the shell volume to its position in the 3D texture map is defined as
我们的表示与Shell Maps [47,14,58]相关,这是一种计算机图形学技术,旨在对近表面细节进行建模。壳贴图使用3D纹理贴图将精细比例特征存储在靠近给定基面的壳状体积中,通常表示为三角形网格。本质上,它们扩展了UV贴图,使得壳体中的每个点都可以双射映射到3D纹理贴图,以便在纹理空间中进行高效建模和渲染。壳体积是通过沿法线方向沿着偏移基础网格来构造的,同时保持拓扑并避免自相交。体积被离散为连接基础网格和偏移网格顶点的四面体。可以通过识别四面体并随后查询其内部的重心坐标来建立壳空间和纹理空间之间的唯一映射。形式上,从壳体积中的 𝐱 到其在3D纹理图中的位置的映射被定义为:
| 𝐱�=�(𝐓�,�(𝐱,𝐓)), | (4) |
where 𝐓,𝐓� refer to corresponding tetrahedra in the shell and texture space, �(𝐱,𝐓) is the barycentric coordinates of 𝐱 in 𝐓, and � denotes barycentric interpolation.
其中 𝐓,𝐓� 表示壳和纹理空间中的对应四面体, �(𝐱,𝐓) 是 𝐱 在 𝐓 中的重心坐标,并且 � 表示重心插值。

Figure 4: Latent Code Interpolation. Latent code interpolation of our model trained on DeepFashion Dataset.
图4:潜在代码插值。在DeepFashion Dataset上训练的模型的潜在代码插值。

Figure 5:Qualitative Comparison. We compare our results with GNARF and EVA3D baselines on DeepFashion and SHHQ datasets. In each case, we show the deformed body poses of the identities generated by the methods. The competing methods exhibit artifacts marked in red. Notice that our approach generates high-quality textures, like facial details and more realistic deformations.
图5:定性比较。我们将我们的结果与DeepFashion和SHHQ数据集上的GNARF和EVA3D基线进行了比较。在每一种情况下,我们显示的变形的身体姿势的方法产生的身份。竞争方法显示红色标记的伪影。请注意,我们的方法生成高质量的纹理,如面部细节和更逼真的变形。
4Gaussian Shell Maps (GSM)
4高斯壳映射(GSM)
GSM is a framework that connects 3D Gaussians with SOTA CNN-based generator networks [11] in a GAN setting. The key idea is to anchor the 3D Gaussians at fixed locations on a set of “shells” derived from the SMPL [36] human body template mesh. These shells span a volume to model surface details that deviate from the unclothed template mesh. We learn the relevant Gaussian parameters in the texture space, allowing us to leverage established CNN-based generative backbones while seamlessly utilizing the parametric deformation model for articulation. The overall pipeline is shown in Figure 2.
GSM是一个框架,在GAN设置中将3D高斯模型与基于SOTA CNN的生成器网络[11]连接起来。关键思想是将3D高斯锚在从SMPL [36]人体模板网格导出的一组“壳”上的固定位置。这些壳跨越一个体积,以模拟偏离未覆盖模板网格的表面细节。我们在纹理空间中学习相关的高斯参数,使我们能够利用已建立的基于CNN的生成主干,同时无缝地利用参数化变形模型进行连接。整个管道如图2所示。
4.1Representation
Our method utilizes the concept of shell maps to leverage the inherent planar structure of texture space for seamless integration with CNN-based generative architectures and, at the same time, encapsulate diverse and complex surface details without directly modifying the template mesh. Specifically, the shell volume is defined by the boundary mesh layers, created by inflating and deflating the T-pose SMPL mesh using Laplacian Smoothing [60] with the smoothing factor set to negative for inflation and positive for deflation. We then represent this shell volume using � mesh layers, i.e. “shells”, by linearly spacing the vertices between the aforementioned boundary shells. In parallel, we apply a similar discretization strategy to the 3D texture space, creating � 2D texture maps storing neural features that can be referenced for each shell using the UV mapping inherited from the SMPL template.
我们的方法利用壳映射的概念来利用纹理空间的固有平面结构,与基于CNN的生成架构无缝集成,同时封装各种复杂的表面细节,而无需直接修改模板网格。具体而言,壳体积由边界网格层定义,通过使用拉普拉斯平滑[60]对T姿态SMPL网格进行膨胀和收缩来创建,其中将平滑因子设置为膨胀为负,收缩为正。然后,我们使用 � 网格层,即“壳”,通过线性间隔上述边界壳之间的顶点来表示该壳体积。同时,我们将类似的离散化策略应用于3D纹理空间,创建 � 2D纹理映射,存储可以使用从SMPL模板继承的UV映射为每个外壳引用的神经特征。
As shown in Figure 2, we use the shell maps to generate all Gaussian parameters except the positions, as those are sampled and anchored w.r.t. to the shells at every iteration (explained below in detail). This results in a feature volume of 𝖳�×�×�×11, comprised of 3D color 𝖳𝐜, 1D opacity 𝖳�, 3D scaling 𝖳𝐬, and 4D rotation 𝖳𝐪 features.
如图2所示,我们使用壳映射来生成除位置之外的所有高斯参数,因为这些参数是通过w.r.t.在每一次迭代中,都将其添加到shell中(下面将详细解释)。这导致 𝖳�×�×�×11 的特征体积,包括3D颜色 𝖳𝐜 、1D不透明度 𝖳� 、3D缩放 𝖳𝐬 和4D旋转 𝖳𝐪 特征。
We create Gaussians in our shell volume. This is done by sampling a fixed number of Gaussians quasi-uniformly on the shells based on the triangle areas. Once sampled, the Gaussians are anchored on the shells using barycentric coordinates so that every Gaussian center 𝐱 can be mapped to a point 𝐱� on the corresponding shell map using Eq. 4, except that the tetrahedra are replaced with the triangle in which the Gaussian resides. This anchoring is a crucial design choice, as it enables straightforward feature retrieval from the shell maps. More importantly, it simplifies the learning by fixing the Gaussian positions and offloading geometry modeling to opacity � and sigma Σ.
我们在壳体积中创建高斯体。这是通过基于三角形面积在壳上准均匀地采样固定数量的高斯来完成的。一旦被采样,使用重心坐标将高斯锚定在壳上,使得每个高斯中心 𝐱 可以使用等式(1)被映射到对应壳映射上的点 𝐱� 。4,除了四面体被替换为高斯驻留的三角形。这种锚定是一个至关重要的设计选择,因为它可以从shell映射中直接检索特征。更重要的是,它通过固定高斯位置并将几何建模卸载到opacity � 和sigma Σ 来简化学习。
The spatial span of the Gaussians plays a significant role in reconstructing the features defined on the discrete shells into a continuous signal within the 3D space. It enables every point—whether on the shells, between them, or outside them—to receive a valid opacity and color value by evaluating Eq. 3. This process allows us to model diverse appearances and body shapes, excelling mesh-based representation while at the same time maintaining efficient rendering, which is critical for GAN training.
高斯的空间跨度在将离散壳上定义的特征重建为3D空间内的连续信号中起着重要作用。它使每个点-无论是在壳上,壳之间,还是壳外-都可以通过计算Eq. 3.这个过程使我们能够对不同的外观和身体形状进行建模,在保持高效渲染的同时,出色地表现出基于网格的表示,这对于GAN训练至关重要。
Formally, Gaussian opacity, color, scale, and rotation can be interpolated from the shell maps 𝖳
形式上,高斯不透明度、颜色、比例和旋转可以从壳贴图 𝖳 插值
| �=𝖳�(𝐱�), where �={�,𝐜,𝐬,𝐪}. | (5) |
4.2Deformation
The deformation step updates the Gaussians’ locations and orientations based on the SMPL template mesh 𝐌, pose 𝜽, and shape 𝜷. Note that, different from SMPL, our template mesh could be any of the shells. Since each Gaussian is anchored on the shells using barycentric coordinates, we can query its new location and orientation simply from the associated vertices. In particular, given the barycentric coordinates �(𝐱,𝐓) of a Gaussian inside triangle 𝐓, and the deformed position 𝐓new and the rotation quaternions 𝐏 on the vertices, we can obtain the new location and orientation of the Gaussian as
变形步骤基于SMPL模板网格 𝐌 、姿态 𝜽 和形状 𝜷 更新高斯的位置和取向。请注意,与SMPL不同,我们的模板网格可以是任何壳。由于每个高斯都使用重心坐标锚定在壳上,因此我们可以简单地从相关顶点查询其新位置和方向。特别地,给定高斯内部三角形 𝐓 的重心坐标 �(𝐱,𝐓) 以及顶点上的变形位置 𝐓new 和旋转四元数 𝐏 ,我们可以获得高斯的新位置和取向为
| 𝐱new=�(𝐓new,�(𝐱,𝐓)), | (6) | ||
| 𝐪new=𝐩^‖𝐩^‖𝐪,where 𝐩^=�(𝐏,�(𝐱,𝐓)). | (7) |
The deformed mesh is given by the SMPL deformation model SMPL, and the quaternions 𝐏 are a result of the linear blend skinning (LBS) from regressed joints and skinning weights, {��}1��, i.e., 𝐌new=SMPL(𝜽,𝜷,𝐌) and 𝐩=rot2quat2����(∑�=1������(𝜽,�(𝜷))), where �� is the rotation matrix of the �-th joint, and � is the regressor function that maps the shape parameters to the joint locations.
变形网格由SMPL变形模型 SMPL 给出,四元数 𝐏 是来自回归关节和蒙皮权重 {��}1�� 的线性混合蒙皮(LBS)的结果,即, 𝐌new=SMPL(𝜽,𝜷,𝐌) 和 𝐩=rot2quat2����(∑�=1������(𝜽,�(𝜷))) ,其中 �� 是第 � 个关节的旋转矩阵, � 是将形状参数映射到关节位置的回归函数。
4.3GAN training 4.3 GAN训练
Generator. 生成器.
Similar to prior work [11], we adopt StyleGAN2 without camera and pose conditioning [6, 71] for the generator. We use separate MLPs with different activations for 𝐜,�,𝐪, and 𝐬: for 𝐜, we use shifted sigmoid following the practice proposed in Mip-NeRF [5]; for � we use sigmoid to constrain the range to (0,1); for 𝐪 we normalize the raw MLP output to ensure they are quaternions (see Eq. 7); for 𝐬 we use clamped exponential activation to limit the size of the Gaussians, which is critical for convergence based on our empirical study.
与之前的工作类似[11],我们采用StyleGAN 2,没有相机和姿势调节[6,71]用于生成器。对于 𝐜,�,𝐪 和 𝐬 ,我们使用具有不同激活的单独的MLP:对于 𝐜 ,我们按照Mip-NeRF [5]中提出的实践使用移位的sigmoid;对于 � ,我们使用sigmoid将范围限制到 (0,1) ;对于 𝐪 ,我们将原始MLP输出归一化以确保它们是四元数(参见等式11)。7);对于 𝐬 ,我们使用钳位指数激活来限制高斯的大小,这对于基于我们的经验研究的收敛至关重要。
Discriminator. 鉴别器。
Our discriminator closely follows that of [6]. Since it does not have an upsampler, the input to the discriminator is the RGB image concatenated with the alpha channel (foreground mask), which is rendered using Gaussian rasterization with the Gaussian color set to 1 for fake samples and precomputed using off-the-shelf segmentation network [55] for the real samples. We refer to the discriminator using foreground mask “Mask Discriminator”. Including the alpha channel helps prevent the white background from bleeding into the appearance, which causes artifacts during articulation.
我们的[6],就是我们的[7]。由于它没有上采样器,因此RGB图像的输入是与alpha通道(前景蒙版)连接的RGB图像,对于假样本,使用高斯光栅化(高斯颜色设置为1)渲染,对于真实的样本,使用现成的分割网络[55]进行预计算。我们将使用前景掩模的搜索称为“掩模鉴别器”。包含Alpha通道有助于防止白色背景渗入外观,这会在清晰度显示期间导致伪影。
Face, Hand, and Feet Discriminator.
脸、手和脚鉴别器。
As the human body and clothes are diverse, the discriminator may choose to focus on these features and provide a weak signal to the facial, hand, and foot areas, which are crucial for visually appealing results. To avoid this problem, we adopt a dedicated Face Discriminator 𝒟face, Feet-and-Hands Discriminator 𝒟feet/hands in addition to the main Discriminator 𝒟main. All of these part-focused discriminators share the same base architecture as the main discriminator, except that we no longer use any conditioning since these cropped images do not contain distinct pose information. The inputs are crops of the corresponding parts, whose spatial span is determined from the SMPL pose and camera parameters.
由于人体和衣服是多种多样的,因此摄像机可以选择专注于这些特征,并向面部、手部和脚部区域提供弱信号,这些区域对于视觉上吸引人的结果至关重要。为了避免这个问题,除了主鉴别器 𝒟main 之外,我们还采用了专用的面部鉴别器 𝒟face ,脚和手鉴别器 𝒟feet/hands 。所有这些部分聚焦的鉴别器与主鉴别器共享相同的基础架构,除了我们不再使用任何条件,因为这些裁剪的图像不包含不同的姿态信息。输入是相应部分的裁剪,其空间跨度由SMPL姿态和相机参数确定。
Scaling Regularization. 缩放正则化。
In our empirical study, we observe when unconstrained, the network tends to learn overly large or extremely small Gaussians early on during the training and rapidly leads to divergence or model collapse. We experimented with multiple regularization strategies and different activation functions and found the following scaling regularization most effective:
在我们的实证研究中,我们观察到,当不受约束时,网络倾向于在训练早期学习过大或极小的高斯分布,并迅速导致发散或模型崩溃。我们尝试了多种正则化策略和不同的激活函数,发现以下缩放正则化最有效:
| ℒscale=𝖬∘‖𝖳𝐬−�ref‖2 with �ref=1�∑�=1�ln(��), | (8) |
where 𝖬 is the binary mask indicating UV-mapped region on the shell maps, and �ref is a reference scale determined by the closest-neighbor distance � averaged among all the Gaussians.
其中 𝖬 是指示壳映射上的UV映射区域的二进制掩码,并且 �ref 是由在所有高斯中平均的最近邻距离 � 确定的参考比例。
Table 1:Quantitative Evaluation. We compare our method with 3D-GAN baselines using DeepFashion and SHHQ datasets. We compute the FID score to evaluate the quality and diversity of the generated samples. Notice that our scores are comparable to state-of-the-art methods. To evaluate deformation consistency, we compute the PCK metric, where our approach consistently outperforms the baselines. INF. represents the inference speed measured in ms/img on an A6000 GPU at 5122 resolution. Note our method is the fastest across all competing methods. ∗ numbers are adopted from EVA3D [23]; NA represents Not Available; — represents Not Applicable, and + numbers are provided by the authors.
表1:定量评价。我们使用DeepFashion和SHHQ数据集将我们的方法与3D-GAN基线进行了比较。我们计算FID分数来评估生成的样本的质量和多样性。请注意,我们的分数与最先进的方法相当。为了评估变形一致性,我们计算PCK度量,其中我们的方法始终优于基线。INF.表示在A6000 GPU上以 5122 分辨率测量的推理速度,单位为ms/img。注意,我们的方法是所有竞争方法中最快的。 ∗ 编号采用自EVA 3D [23]; NA代表不可用; -代表不适用, + 编号由作者提供。
| Model | Deep Fashion | SHHQ | Comp. | ||
| FID ↓ FID编号0# | PCK ↑ | FID ↓ FID编号0# | PCK ↑ | INF. ↓ | |
| EG3D∗ | 26.38 | — | 32.96 | — | 38 |
| StyleSDF∗ | 92.40 | — | 14.12 | — | 32 |
| ENARF∗ | 77.03 | 43.74 | 80.54 | 40.17 | 104 |
| GNARF | 33.85 | 97.83 | 14.84 | 98.96 | 72 |
| EVA3D∗ | 15.91 | 87.50 | 11.99 | 88.95 | 200 |
| StylePeople | 17.72 | 98.31 | 14.67 | 98.58 | 28 |
| GetAvatar | 19.00+ | NA | NA | NA | 44 |
| AG3D | 10.93 | NA | NA | NA | 105 |
| Ours | 15.78 | 99.48 | 13.30 | 99.27 | 28 |
5Experiment Settings 5实验设置
5.1Datasets
We evaluate our method using the two most common human datasets, DeepFashion [35] and SHHQ [17]. DeepFashion and SHHQ do not provide SMPL parameters, so we use SMPLify-X [43] to obtain the SMPL parameters and camera poses.
我们使用两个最常见的人类数据集DeepFashion [35]和SHHQ [17]来评估我们的方法。DeepFashion和SHHQ不提供SMPL参数,因此我们使用SMPLify-X [43]来获取SMPL参数和相机姿势。















 6961
6961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











