






多语言UI不匹配问题(英)
常见问题一:文本重叠
情况1. 很多界面有标题文本和帮助图标,但是未做自适应文本长度,导致文本变长的时候文本直接和图标重叠

情况2. 当文本1和文本2处于同一行,且文本2接在1后,需要对文本1做自适应长度处理,否则文本1可能和文本2重叠

问题处理:
-
以情况1为例,需要将标题文本的obj添加Content Size Fitter组件,并设置Horizontal Fit为Preferred Size(横向自适应)
-
然后将希望位于标题文本后面的obj作为标题obj的子物体,设置锚点为右中心,自行调整合适的位置即可
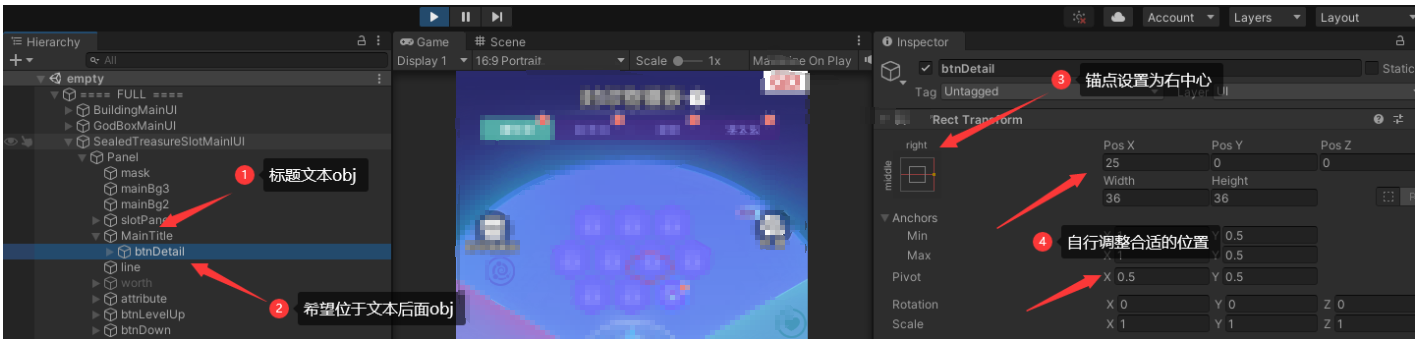
-
需要注意的是,如果调整了层级关系,需要去代码做对应修改。如果调整的是预制,需要修改所有使用到该预制的UI的代码;如果调整时涉及到item代码文件的修改,需要找到所有使用到该item的预制,并同步修改该预制的层级。
常见问题二:文本展示不全
情况1. 因为文本框长度不够长导致英文文本超框不显示

情况2. 文本超出界面显示
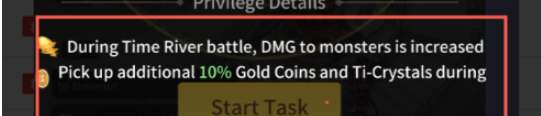

问题处理:
- 以情况1为例,建议将文本框的属性设置为Wrap+Truncate,然后固定文本框的长度(选择一个合适的长度),最后设置字体自适应,这样可以满足大部分情况下的多语言处理,如果英文文本实在是过长,可以考虑缩短翻译
- 情况2和情况1处理方式相同。如果还是不满意可以减小字体行距,这样过长的文本可以换行显示。但这样需要注意中文如果换行会不会有问题(一般不会有,因为中文的长度一般不会超框)
常见问题三:拼接文本问题
情况1. 时间文本拼接问题,中文的年月日大部分是拼接显示(2024 + 年 + 6 + 月 + 19 + 日),但英文实际应该显示April 29th, 2024, at 15:49:32

情况2. 拼接缺少空格,此处中文翻译为冷淡2阶(冷淡 + 2阶),翻译成英文就是(ApathyT2)中间少了个空格

问题处理:
-
时间翻译主要是解决两个问题,一个是英文的1号是1st,2号是2nd这些特殊的规则,还有一个是不同语言的语序不一样。这里选择的处理方式是将1-12月,周一到周日,1-31号的英文单独字段化。然后时间的处理统一调用函数timeConvertYearMonthDay,在这里面判断当前语言,并对不同语言的语序做了单独的处理。
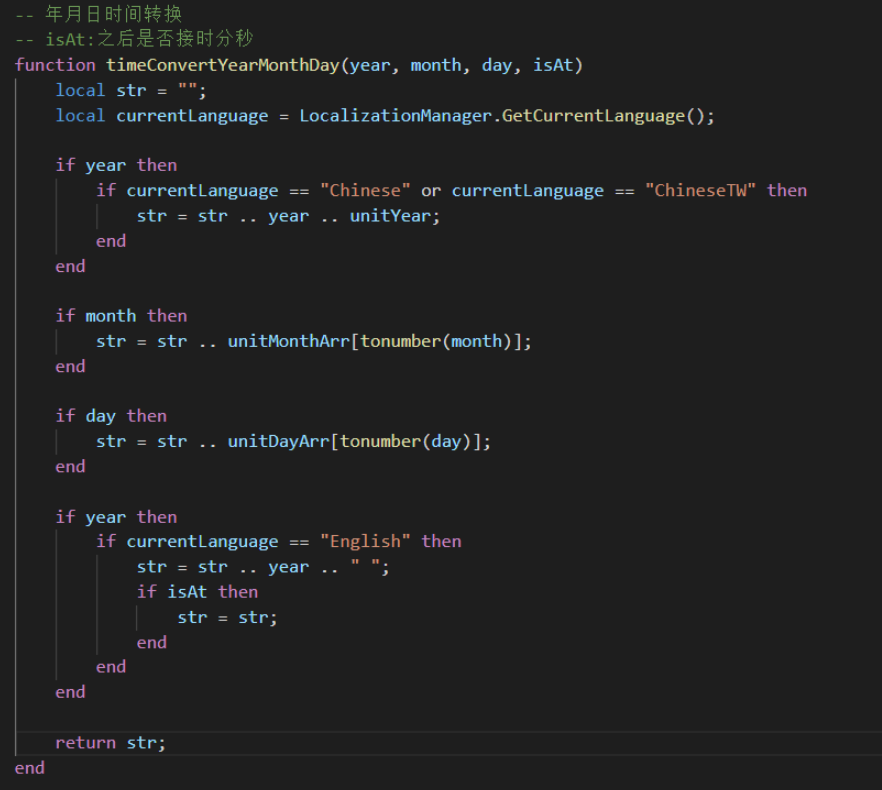
-
情况2则是需要考虑到拼接的问题,使用一个字段two_chains单独处理这种两两拼接。
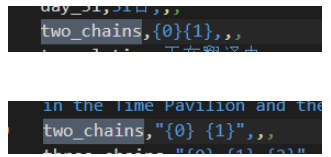















 6312
6312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









