








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
看了标题,可能读者会有疑惑,大家不都想着将大模型缩小吗?怎么你想着将小模型放大了?其实背景是这样的:通常来说更大的模型加更多的数据确实能起得更好的效果,然而算力有限的情况下,从零预训练一个大的模型时间成本太大了,如果还要调试几次参数,那么可能几个月就过去了。
这时候“穷人思维”就冒出来了(土豪可以无视):能否先训练一个同样层数的小模型,然后放大后继续训练? 这样一来,预训练后的小模型权重经过放大后,就是大模型一个起点很高的初始化权重,那么大模型阶段的训练步数就可以减少了,从而缩短整体的训练时间。
那么,小模型可以无损地放大为一个大模型吗?本文就来从理论上分析这个问题。

含义
有的读者可能想到:这肯定可以呀,大模型的拟合能力肯定大于小模型呀。的确,从拟合能力角度来看,这件事肯定是可以办到的,但这还不是本文关心的“无损放大”的全部。
以 BERT 为例,预训练阶段主要就是一个 MLM 模型,那么“无损放大”的含义就是:是否可以通过某种变换,把一个小模型直接变换成一个大模型,并且输出完全不改变?
这里的变换,指的是对权重做一些确定性的变换,而不用通过梯度下降来继续训练;输出完全不改变,指的是对于同一个输入,小模型和大模型给出的预测结果是完全一致的,也就是说它们表面上看起来不一样,但数学上它们是完全一致的函数,所以称为“无损放大”。由于是无损放大,我们至少可以保证大模型不差于小模型,所以继续预训练理论上有正的收益。至于先小后大这样预训练在效果上能不能比得上一开始就从大训练,这个需要实验来确定,并不是本文关心的问题。
直觉来想,这种放大也不困难,比如通过“重复”、“补零”等操作就可以实现模型权重的自然放大。事实上尝试的方向也是如此,但难点在于我们需要仔细分析模型的每一个模块在被放大之后所产生的后果,以确保最终的结果是无损的。

尝试
下面我们以“将一个 BERT 放大为 2 倍”为例子进行分析尝试,来确定最终的变换形式。这里的“放大”指的是仅仅扩大隐层向量的维度,并不改变模型的层数,也不改变多头注意力机制的头数。
2.1 Embedding
首先,输入层是 Embedding 层,因此先要解决的是 Embedding 层的放大问题。这也是其中最简单的一环,就是直接将每个 token 的向量维度都放大为 2 倍即可,主要就是“重复”、“补零”两种操作:
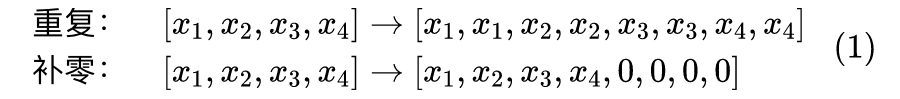
两种方案都可以作为候选方案,但直觉上来想,补零这种方式引入了太多的零,会导致过度稀疏和同一个值重复次数过多,不利于权重的多样性,因此我们还是选择了重复这种方案。不过,就算只看重复,也不指上述一种方式,比如 也是一种方案,但后面关于 Attention 层的分析表明,后一种方案是不可取的。
除此之外,我们通常还希望变换是正交的,这通常能最大程度上保证模型的稳定性,具体来说,正交变换的最基本性质是不改变向量的模型,所以我们将最终的重复变换调整为:
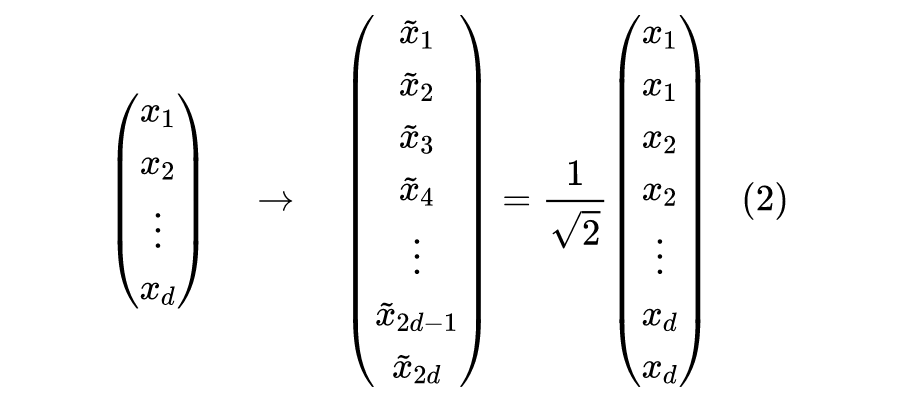
或者简记成 是上取整运算,我们称之为“重复再除以 ”。
2.2 LayerNorm
Embedding 的下一层就是 LayerNorm 了,变换前,LayerNorm 的运算为:
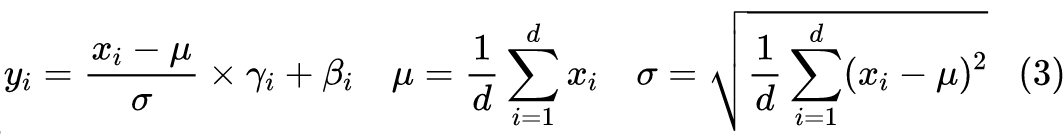
而变换后,我们有:
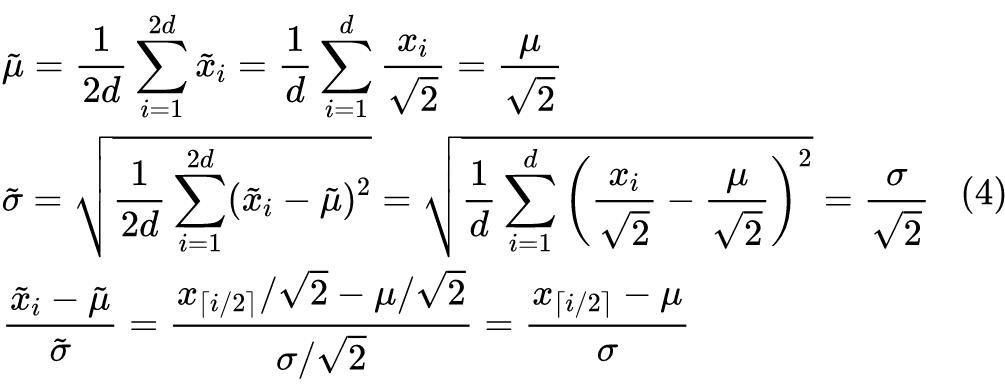
这也就是说,“减均值除以标准差”这一步自动帮我们消去了 这个因子,其结果是放大前结果的直接重复。如果我们将参数向量 也按照公式(2)进行变换,那么结果将是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3123
3123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









