







我们接着学习Transformer相关内容,我们先回顾一下这个经典的图再开始我们的学习。
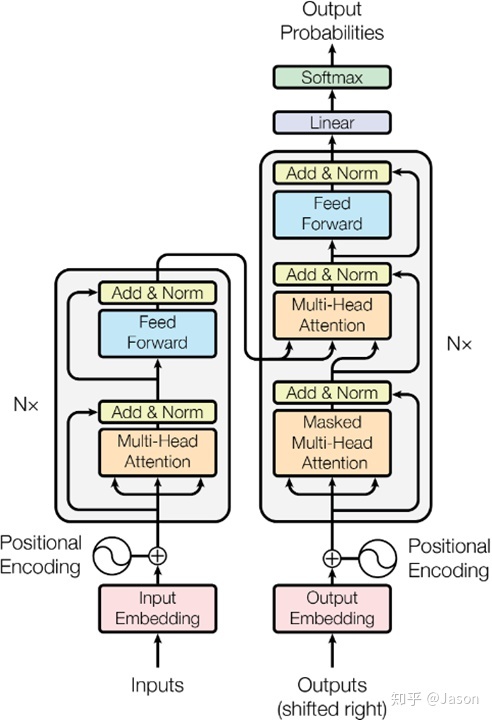
残差: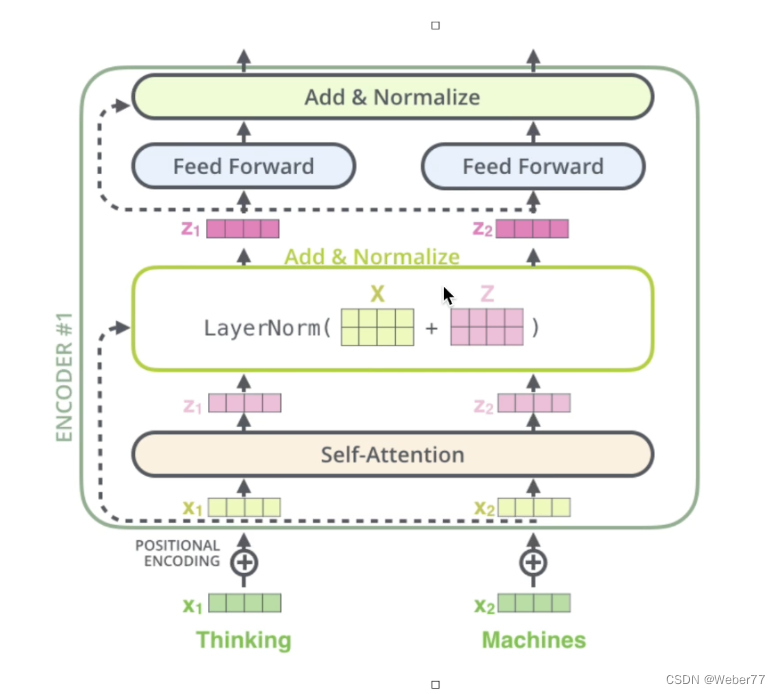
我们从底层向上看,最下面的x1和x2是我们的词向量,经过位置编码后加入了位置信息成了新的x1和x2,接下来经过自注意力层得到注意力结果z1和z2。
残差:我们可以看到我们会对z向量加上经过位置编码的x向量,这一步叫做残差。这意味着z向量和x向量的维度一致。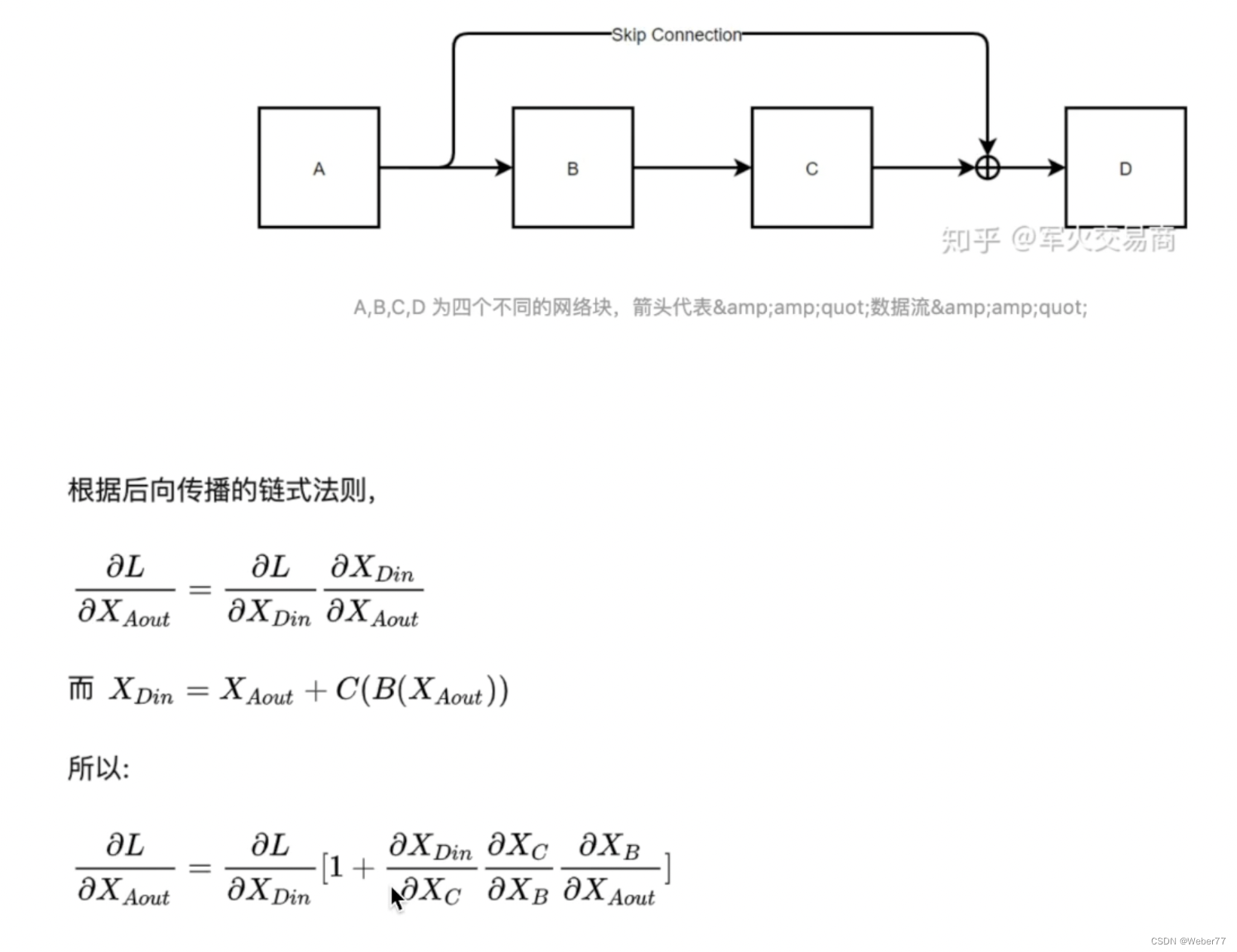
这一张图说明了残差的作用,即使序列再长经过求导以后梯度接近于0,但是仍有一个常数项1,不至于让模型收敛很慢,这也是如果用到了残差网络模型通常可以变得比较深的原因。
LayerNorm
在讲解LN之前我们首先复习一下BN(batch normlization),并且探讨一下为什么在序列预测中BN不如LN有用。
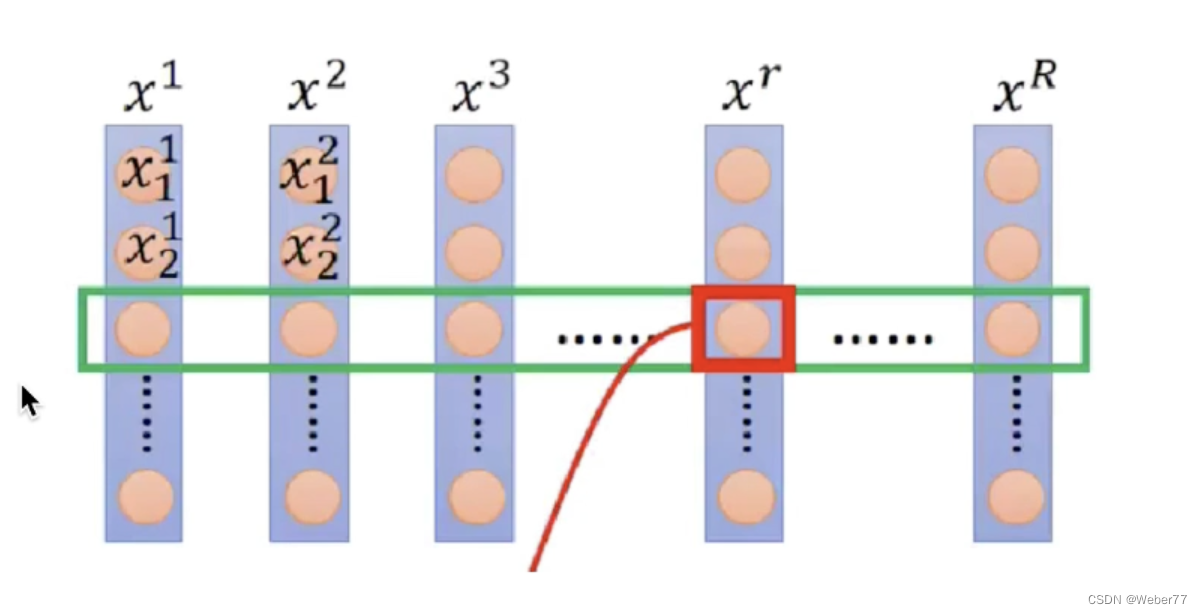
我们假设每一个紫色的列为一个样本,每一行为同一种特
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











