








©PaperWeekly 原创 · 作者 | 张一帆
学校 | 中科院自动化所博士生
研究方向 | 计算机视觉
深度学习盛行的现在,作为一名合格的调参侠,至少都下载/使用过很多个数据集了。而现在 DL 中各种 setting 都涉及着对数据集之间关系的研究,几个典型的例子如下。

但是你真正了解使用过的数据集吗?数据集有什么关系?数据集之间有多像?我们或许对此一无所知。来自 Microsoft 的资深研究员 David Alvarez-Melis 连发多篇 ML 顶会对这个问题加以研究。
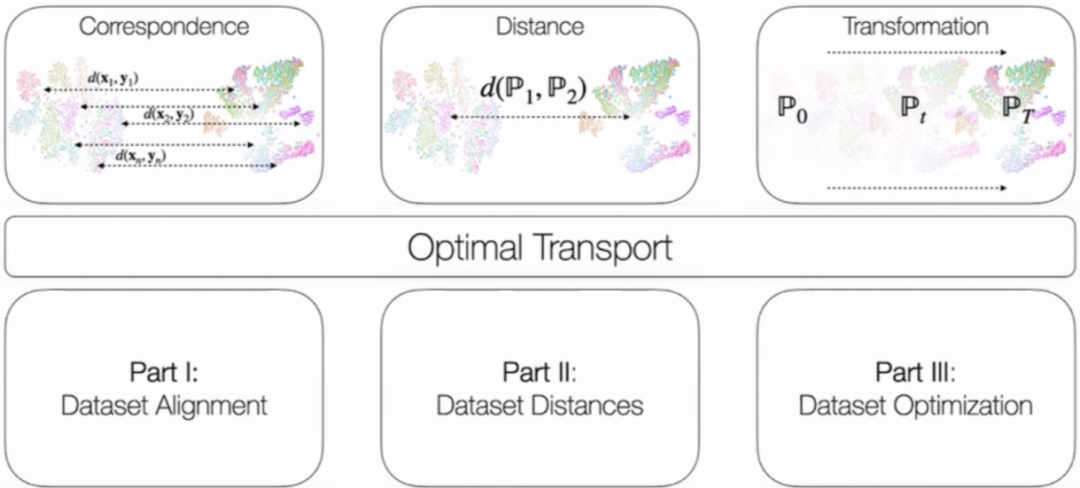
本文将其一系列工作分为三部分介绍:1)如何进行数据集对齐;2)如何定义数据集之间的距离测度;3)如何优化数据集。我们首先介绍知识背景即最优运输理论,然后分别介绍 David Alvarez-Melis 组关于三方面工作的三篇顶会文章。

最优运输理论
最优运输是一种寻找成本最低“将土堆从一个地方运送到另一个地方的方法”的方案。把概率分布想象成一堆泥土,最优传输直观地量化了它们的不同,即“泥土”或概率质量必须铲多少和多远才能将一堆泥土变成另一堆。
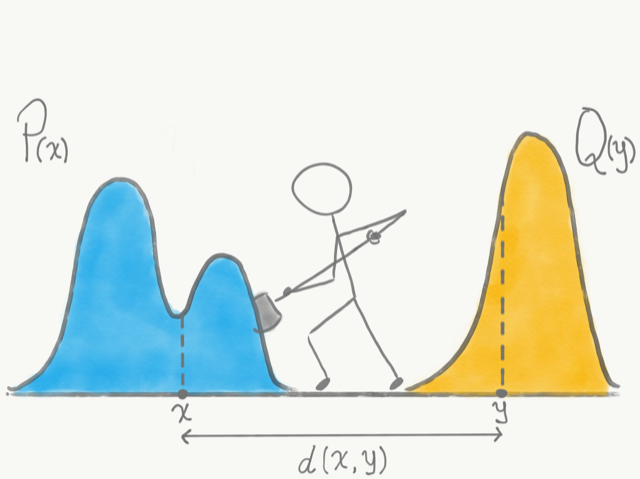
但是土堆和铲子与统计或机器学习有什么关系?我们将概率密度函数视为土堆,其中堆的“高度”对应于该点的概率密度,在堆之间铲土作为从一个点移动到另一个点的概率,其成本为这两点之间的距离。最优运输为我们提供了一种量化两个概率密度函数之间相似性的方法,即通过将一堆堆完全铲成另一堆的形状和位置所产生的最低总成本。对两个概率分布,最优运输理论较为正式的定义为:
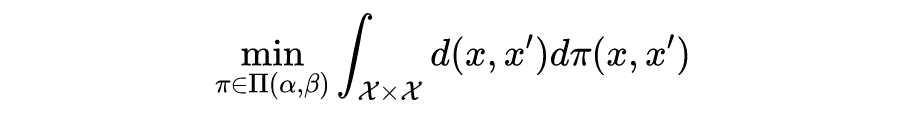
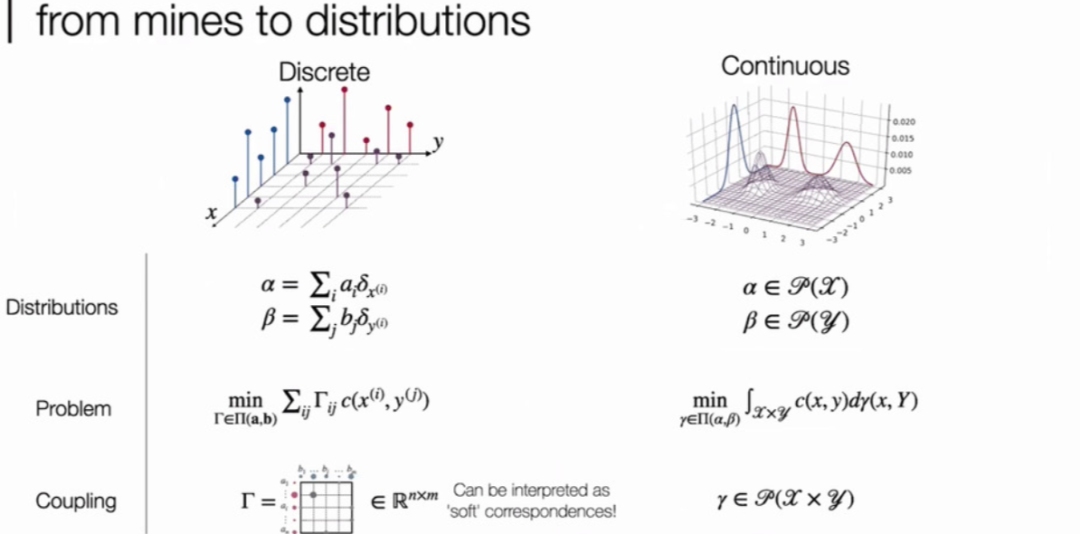
这里是边缘分布的联合分布,“铲土”的花费记作样本距离,这就是我们熟知的 p-Wasserstein distance ,也是 Wasserstein GAN 的理论基础,更相信的定义可以参阅这里 [1]。作者使用的是离散型的 OT,即用狄拉克分布的概率密度函数,这时候 OT 是有能力为每个数据点分配对应关系的。

Dataset alignment
Towards Optimal Transport with Global Invariances(AISTATS'19)
这里使用机器翻译作为例子,正常的机器翻译中我们都需要成对的数据,但是如果没有这种标注,一种可能的策略是通过数据的共现关系来分析词之间的关系。而 embedding 是词的一种更 compact 的表示方式,因此通过 embedding,我们是否能够更好地寻找这种关系?

一种可行的策略是,我们将两个 dataset 的 embedding 全部拿出来,然后计算点对之间的距离,将这个距离设置为 OT 中的花费。但是看下图,我们的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 49
49











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









