







 本文探讨了跨语言语音合成的发展,包括使用中间特征、文本表示和对抗式训练等方法,旨在解决不同语言之间的音色差异问题。研究通过多种网络结构和损失函数优化,提高了跨语言语音合成的自然度和说话人相似度。
本文探讨了跨语言语音合成的发展,包括使用中间特征、文本表示和对抗式训练等方法,旨在解决不同语言之间的音色差异问题。研究通过多种网络结构和损失函数优化,提高了跨语言语音合成的自然度和说话人相似度。

©PaperWeekly 原创 · 作者 | 音月

引言
语音合成(Text-to-Speech, TTS)是指文字转语音相关技术。随着人工智能技术的发展,TTS 的声学模型和声码器模型效果都在不断提高,单一语言在数据量足够的情况下已经可以合成较高品质的语音。研究人员们也逐渐开始关注跨语言语音合成领域,本文主要介绍了近年来跨语言语音合成方法的发展趋势与方向。

背景
早期人们为了合成跨语言的发音只能用多个语音合成系统来合成不同语言的文本,这样会导致不同语言发音时的音色差异较大,影响使用体验。为了改善这种问题,出现了双语语料库,即让同一个说话人录制多种语言的语音数据。虽然一定程度解决了这种问题,但是双语语料库的制作成本较高,音色数量也较难扩展。
另外也有研究人员根据各语言发音特点设计了源语言到目标语言的音素映射表,用于模仿目标语言的发音,但大多数语言常用的音素集不完全一致,依旧会存在一些无法发音或者发音错误的问题。研究人员开始考虑如何对不同语言的数据进行建模,以达到让目标说话人可以合成其他语言的语音。
下面介绍近年来的一些跨语言语音合成方法。

跨语言的中间特征
Statistical parametric speech synthesis based on speaker and language factorization(IEEE Trans 2012)[1] 中提出将说话人信息与语言信息分开建模的方法。
Learning cross-lingual information with multilingual BLSTM for speech synthesis of low-resource languages(ICASSP 2016)[2]
该论文使用了普通话、英语和粤语三种语料,每种语料为 1 个女性说话人。论文将不同 language 的语言学特征拼接起来后,输入共享的中间层得到中间特征作为跨语言特征表示,经过 language-dependent 的输出层得到声学特征。
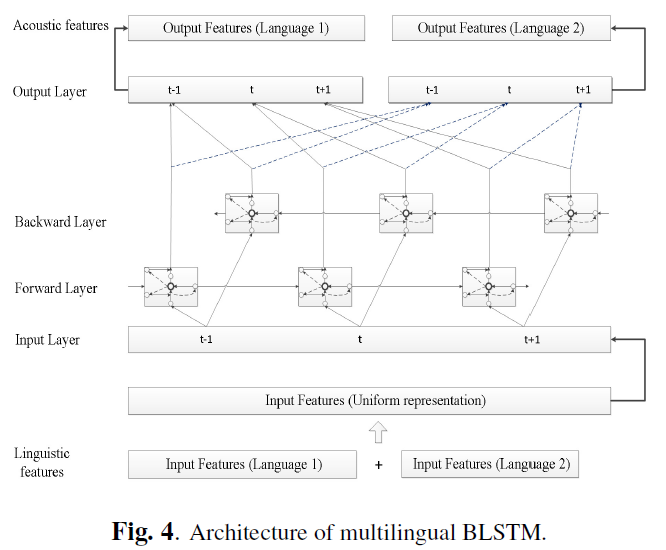
作者假设输入输出层的特征是 language-dependent 的,而中间层如果选择合适的训练方式可以得到 language-independent 的特征表示。实验表明共享的 BLSTM 网络可以学习跨语言信息,能得到比单语言语料训练的 BLSTM 更好的声学特征,从而合成出更高质量的语音。

Speaker and language factorization in DNN-based TTS synthesis(ICASSP 2016)[3]
该论文使用了类似的方法分别构造了 language-dependent 相关和 speaker-dependent 的 DNN 网络。
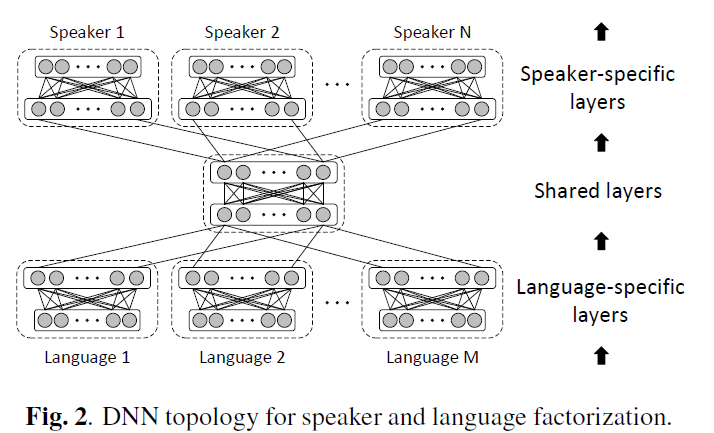
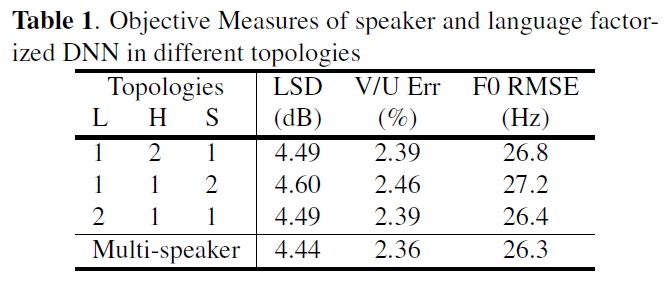
实验涉及了普通话和英语,总共 3 个说话人(两女一男)。论文对比了不同网络拓扑结构后发现使用 2 个 language-dependent 相关网络、1 个共享网络、1 个 speaker-dependent 网络能取得最接近多说话人模型的效果,与 [1] 不同的是,论文的主观评测结果表明跨语言合成的自然程度和相似度的 MOS 值都出现了下降。
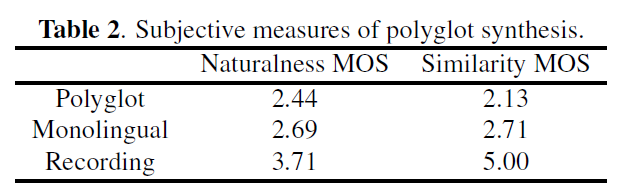
Unsupervised polyglot text to speech(ICASSP 2019)[4]
该论文为了改善跨语言合成说话人相似度的问题,除了 language-dependent 的 text encoder,还加入了 language-dependent 的 speaker encoder 来提取说话人 embedding。论文实验了 VCTK 数据集(109 个英语说话人),DIMEx100 数据集(100 个西班牙语说话人),PhonDat1(201 个德语说话人)。
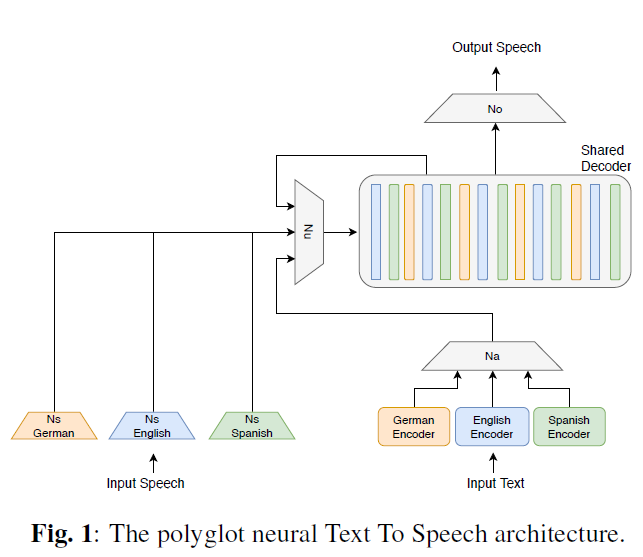
为了进一步改善说话人相似度,论文提出了一种新的损失函数及多阶段训练方法,即在模型初步收敛后使用:语言 a 的语音 ya 经过 a 语言的 speaker encoder 提取的 embedding1(说话人 a 的音色信息),与语言 b 的文本 s 生成语音 ob,最小化 ob 经过 a 语言的 speaker encoder 提取的 embedding2(语言 b 语音的音色信息)的 L1 loss,以期望该 speaker encoder 只提取说话人音色信息而不包含语言信息,该阶段只训练各个语言的 speaker encoder。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









