








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
在《你可能不需要 BERT-flow:一个线性变换媲美 BERT-flow》中,笔者提出了 BERT-whitening,验证了一个线性变换就能媲美当时的 SOTA 方法 BERT-flow。此外,BERT-whitening 还可以对句向量进行降维,带来更低的内存占用和更快的检索速度。然而,在《无监督语义相似度哪家强?我们做了个比较全面的评测》中我们也发现,whitening 操作并非总能带来提升,有些模型本身就很贴合任务(如经过有监督训练的 SimBERT),那么额外的 whitening 操作往往会降低效果。
为了弥补这个不足,本文提出往 BERT-whitening 中引入了两个超参数,通过调节这两个超参数,我们几乎可以总是获得“降维不掉点”的结果。换句话说,即便是原来加上 whitening 后效果会下降的任务,如今也有机会在降维的同时获得相近甚至更好的效果了。

方法概要
目前 BERT-whitening 的流程是:
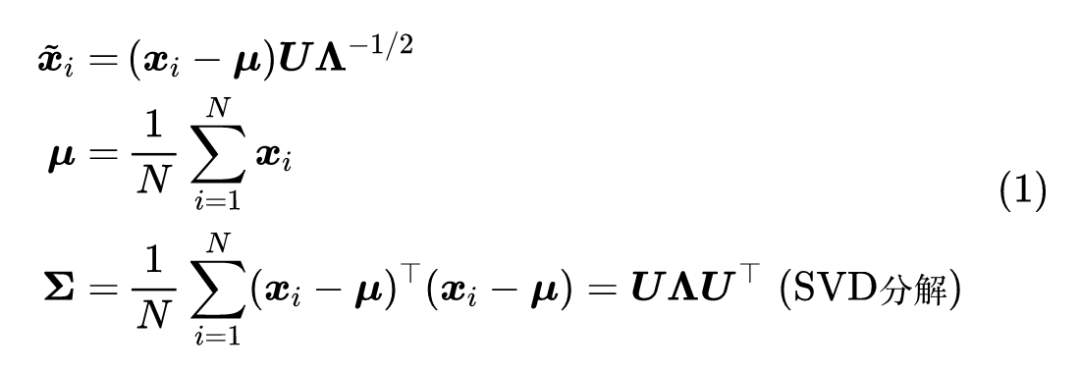
其中 是给定的句向量(如无说明,向量默认为行向量), 是变换后的向量,SVD 分解的结果中, 是正交矩阵, 是对角矩阵,并且
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









