








前言
视觉语言预训练(VLP)模型最近成功地促进了许多跨多模态的下游任务。大多数现有工作通过比较微调的下游任务性能来评估其系统。然而,只有平均下游任务精度很难评判一个 VLP 模型的优点和缺点。另外,下游任务千千万万,相信很多小伙伴们和我一样,对众多下游任务了解不多,更不用说用具体的下游任务去评测模型啦。今天就给大家安利一款不需要下游任务也能评测预训练模型的工具吧,感兴趣的小伙伴们赶紧去文末上手试用吧!

为什么需要一个统一的评测工具?
视觉语言预训练是多机器学习研究的一项基本任务。最近,由于多模态 Transformer 的出现和大型匹配图像文本语料库的可用性,VLP 取得了快速进展。许多的 VLP 模型有助于实现各种下游多模态任务的最先进性能,包括视觉 QA、多模态检索、视觉 Grounding 等。另一方面,当前评估 VLP 模型的实际方法是通过比较其微调的下游任务性能。然而,基于下游任务的基准 VLP 模型有许多局限性:
1. 可解释性差:下游任务很复杂,依赖于许多相互交织的能力,因此它只提供一个黑盒子得分,很难解释。例如,目前仍然不清楚如何改进在视觉 QA 方面表现出色但在图像检索中表现不佳的 VLP 模型。
2. 不可比较的结果:不同的工作可能会选择不同的任务进行评估,这使得比较困难。这是因为一些 VLP 模型与某些任务不兼容,例如 CLIP 无法直接针对视觉 QA 进行微调。
3. 数据偏置:下游数据分布不全面,因此实际性能可能被高估。此外,不能知道模型是否对输入噪声具有鲁棒性,例如用同义词替换动词。
既然基于下游任务的评测方法有这么多局限性,那有没有什么办法来解决呢?那当然有啦!本文就提出了 VL-CheckList 方法,这是一个可解释的框架,全面评估 VLP 模型,有助于加深理解并激发新的改进想法。VLCheckList 的核心原则主要有三点:
1. 评估VLP模型的基本能力,而不是下游应用的性能:基于这一点,作者选择图像文本匹配(ITM)作为主要评估目标,因为它可能是所有VLP方法中最有效的预训练目标。
2. 将能力分解为更易于分析的相对独立的变量:基于这一点,作者提出了一种分类法,将 VLP 系统的功能分为三类:对象、属性和关系。然后将每个类进一步划分为更细粒度的变量,例如属性由颜色、材料和大小等组成。
3. 语言感知的负样本采样策略,以创建难例负样本:这用于验证 VLP 模型对输入空间中微小变化的识别能力。
最后,基于以上几点,作者提出了预训练模型的测评工具 VL-CheckList,研究者都可以轻松地插入他们的评估预训练模型。在本文中,作者通过分析 7 种流行的 VLP 模型验证了所提出的方法,包括双编码器模型、基于区域的 VLP 模型和端到端 VLP 模型。作者采用了四个数据集(VG、SWIG、VAW 和 HAKE)来生成能力特定评估测试集。
实验结果揭示了一些关于这些模型的有趣见解(心急的小伙伴可以先跳到实验部分看看这些见解吧),这些见解很难从下游任务分数中获得。本文的研究表明,与端到端方法相比,基于区域的方法在谓语推理中的性能更强;交叉注意力模型优于双编码器,尤其是对于较小和边缘对象。(大家可以在“评测结果”这一节中看到更多的有意思的结果哦!)

这个评测工具内部是怎么运行的呢?
VLP 最关键的特点是其多模态数据的对齐能力。评估多模态的直观方法之一是检查模型是否正确预测不同模态之间的对齐。为了评估视觉和语言之间的多模态,作者选择图像-文本匹配(ITM),原因如下:首先,ITM 损失通常是所有 VLP 模型中最有效和最普遍的。其次,ITM 也是模型不可知的,适用于所有融合架构。因此,作者选择使用 ITM 公平地比较 VLP 模型,而无需将其调整到下游任务。
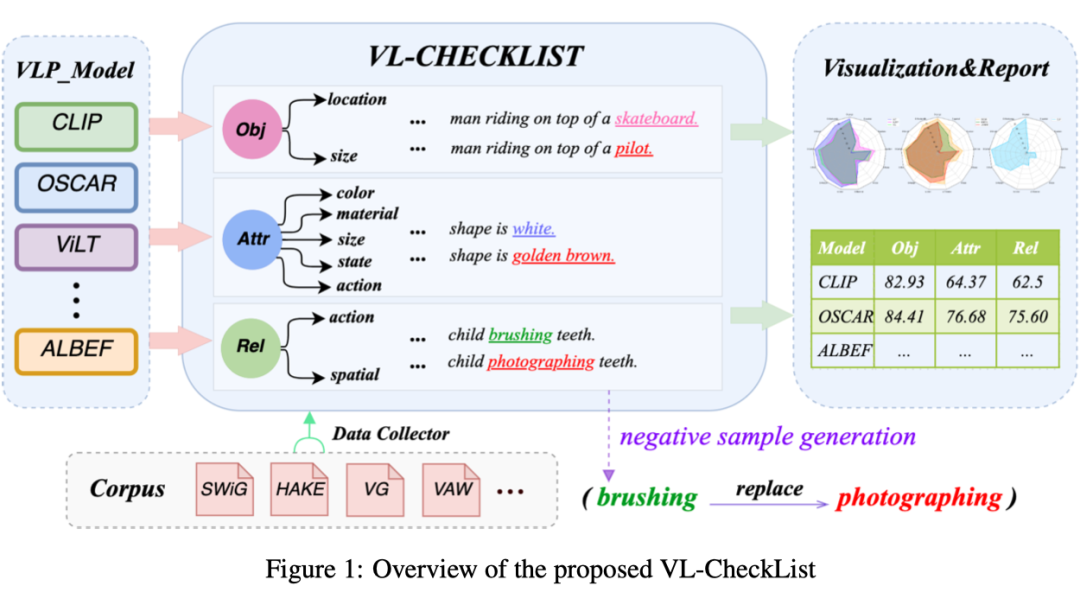
VL-CheckList 的总体流程描述如上图所示,具体来说分为以下几步:
(1)通过将样本分类为三个类(对象、属性和关系)来转换图像-文本配对数据集。
(2)重写每个图像的成对文本,以生成每个类的负样本。
(3)使用 VLP 模型的 ITM 头来区分给定图像的正文本和负文本。
(4)生成各方面模型的综合分析报告。
2.1 VL-CheckList的分类
评估类型通常根据常见错误或频繁使用来选择。基于 VLP 模型中的常见问题,该框架将三个输入属性(对象、属性和关系)作为评估分类的顶层。
2.1.1 对象
一个强大的 VLP 模型应该能够识别文本中提到的对象是否存在于图像中。因此,如果用其他一些随机名词短语替换正确文本中的宾语,VLP 模型的 ITM 分数应该低于原始句子。此外,一个强大的 VLP 模型应该能
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









