








论文标题:
Class-Aware Generative Adversarial Transformers for Medical Image Segmentation
收录会议:
NeurlPS 2022
论文链接:
https://arxiv.org/abs/2201.10737

解决的问题
本论文关注的领域是医学图像分割。在分割领域,Transformer 变得越来越流行,这得益于 Transformer 可以在全局建立长范围联系(long-range dependencipes)。但目前而言其也有其缺点,下面首先介绍传统 Transformer 在分割领域表示出来的一些不足。
1.1 传统Transformer只有单尺度特征表示
传统 Transformer 使用 Self-Attention 来计算特征表示(feature representation),如 [2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(arxiv.org)[1] 论文所示,将图片块类比于句子中的单词,通过 embedding 进行注意力计算,最后得到的特征表示不具有多尺度概念。但在图像分割中多尺度特征对最后的结果也许会有很重要的提升。
1.2 传统Transformer采用的tokenization具有很大的盲目性
如 [2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(arxiv.org)[1] 所示,传统 Transformer 进行硬分割,将多少大小的像素点划为一个 patch,之后便送入 Transformer Encoder Module 中进行计算,这样固然可以连接全局联系,但在图像分割中我们总有需要关注的重点,例如本篇医学领域论文所需要重点关注器官、人体组织等局部部分,而其他背景区域则很可能对最终目标构成干扰。所以如何采取更具针对性的 tokenzation 方法也是十分重要的。
1.3 传统分割网络架构没能很好利用语义上下文
传统分割网络在得到特征表示后进行像素级别的分类,这个过程并不能完全利用好特征表示中的上下文特征。

解决问题的方法
2.1 使用CNN实现多尺度特征表示
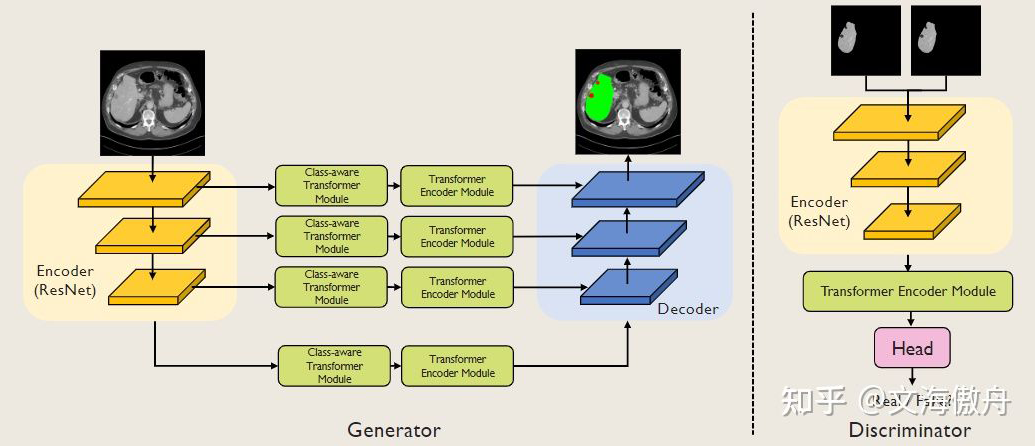
如图所示,这里使用 ResNet 作为特征提取网络以得到多尺度特征图,并将多尺度特征图作为输入,以此来解决传统 Transformer 中单尺度的问题。这里共得到 4 个不同尺度的特征图,分别为:
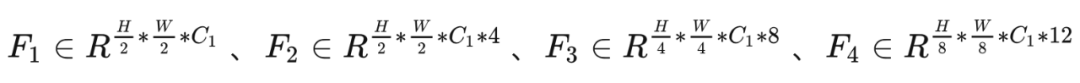
2.2 使用Class-Aware Transformer Module实现针对性取样
上文分析过原 Transformer 使用硬分割选取 token 导致取样不具备针对性,在分割任务中也许会掺揉一些背景 token 导致准确率下降。这里受 [2108.01684] Vision Transformer with Progressive Sampling(arxiv.org)[2] 启发,采用迭代式方式逐步找到想要关注的局部信息。这里首先以原论文中的 tokenization 方法进行说明。
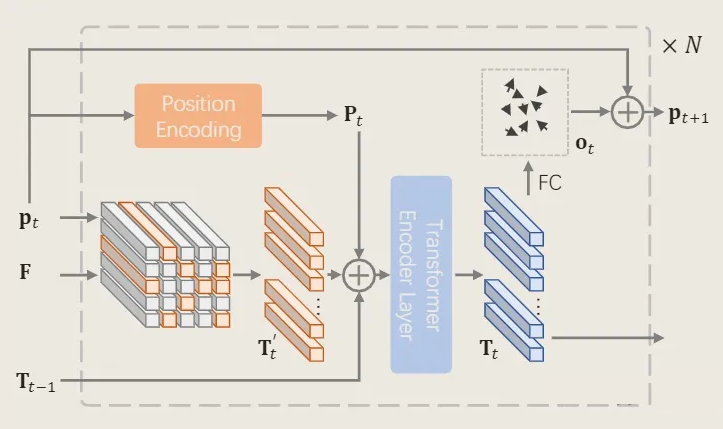
▲ 迭代式取样方法图解
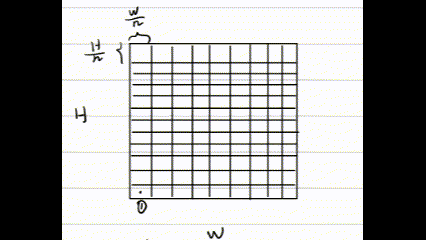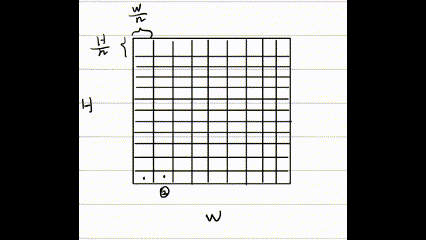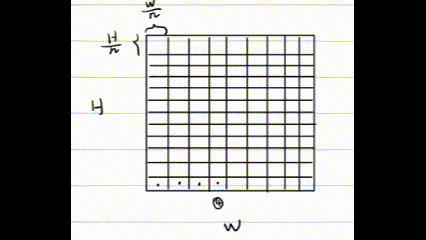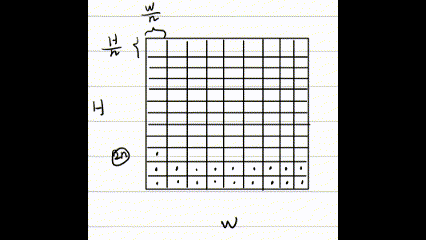
看输入和输出,对于输入的特征图 我们最终希望可以得到具有关注度价值的取样 token,这里假设最终取样 个样本,对于 的情况下,最后输出便是 。
现在问题便是如何迭代取样。在迭代初始阶段,我们没有任何偏好,采用标准 ViT 中的均匀取样方法。值得注意的是,标准 ViT 中将取样的中心点和周围点一起构成一个 ,而这里仅仅采用中心点作为 。以上过程可以表示为如下公式:
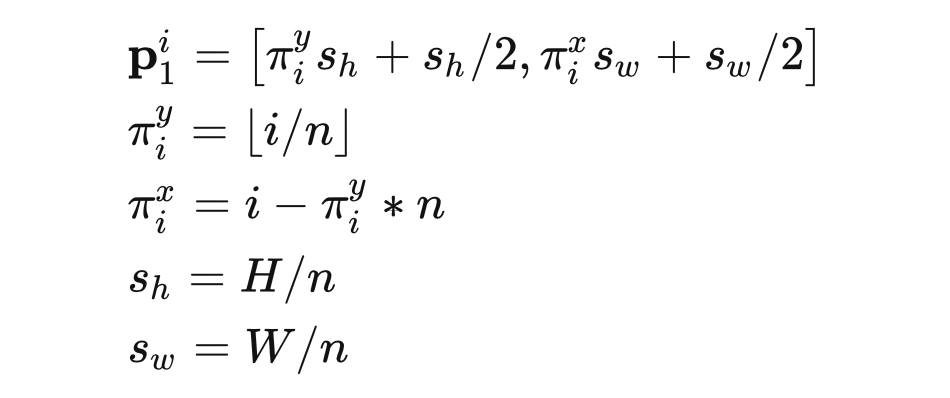
这里 表示第一次迭代过程的第i个取样,由取样数最终为 ,可以理解 H、W 分别取样 n 个,类似 ViT 将原图划分为 个块,于是 、 分别表示每个块的边长,、 则分别表示每个块的一半长度,加上这部分便得到每个块的中心点,于是前面部分便是得到第几个块的长度,以下 GIF 为展示:
对于选取的点集合 在相应特征图 中通过双线性插值得到相应的 token ,之后如图所示进行下列计算

这里便得到了该阶段的 ,而整个过程是一个迭代过程,这里预测下一阶段取样点坐标通过公式
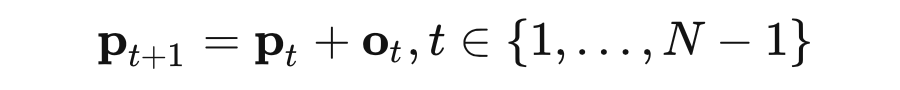
这里 通过一个 MLP 形式 得到的取样偏移矩阵,这样上一阶段取样坐标加上偏移坐标便得到这一次迭代的取样坐标。
本论文借鉴该思想,可以看到本论文中的模块示意图和 [2108.01684] Vision Transformer with Progressive Sampling(arxiv.org)[2] 中的模块示意图表示过程相同。
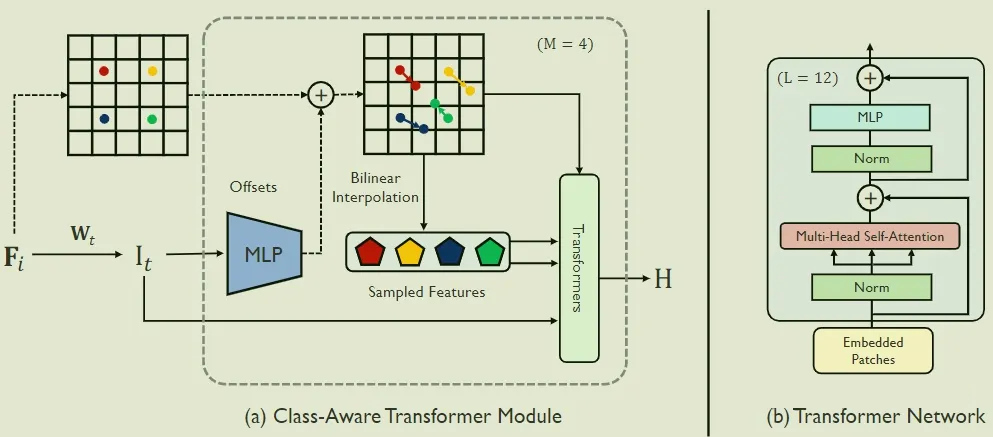
2.3 使用GAN训练策略更好利用上下文语义信息
如标题所示,使用 GAN 的训练策略来使网络更好地利用像素级上下文信息,通过分割图像和 GT 图像进行对抗性的零和游戏,使分割图像更好地对分割部位信息进行学习。在涉及 GAN 网络和图像分割同时处理时,这里将不同任务的损失函数取权重相加,构成这里的损失函数。
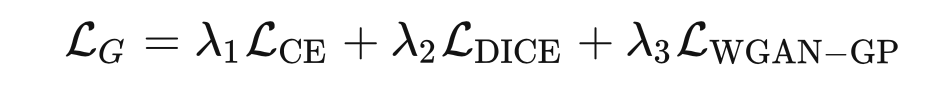

实验证明有效性
3.1 整体网络有效性
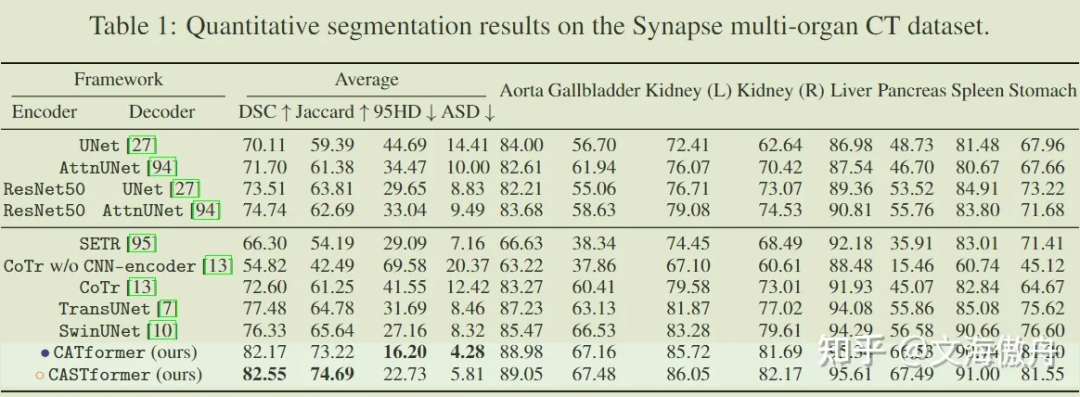
首先介绍四个评价标准,DSC 和 Jacard 倾向于分割内部的相似性,即分割部位重叠越多该得分越高;95HD 和 ASD 倾向于分割边缘的平均距离,即平均距离越小则边缘越重合。
可以发现在所有框架比较中,CATformer 和 CASTformer 都取得比其他网络框架更好的效果。这里有趣的是 CATformer 和 CASTformer 的比较,CATformer 的DSC 和 Jaccard效果比 CASTformer 好,但在 95HD 和 ASD 标准处却不如CASTformer。这里我猜测,相较于 CATformer,CASTformer 使用了 GAN 的训练方式,在损失函数处使用了 DICE Loss,该损失标准偏向于内部重叠而忽略了边缘部分,导致使用了 GAN 网络训练方式在内部重叠标准处取得了较好结果,但在边缘处反而效果有所下降。
3.2 实验结构有效性(消融实验)
A. 迁移学习的有效性:
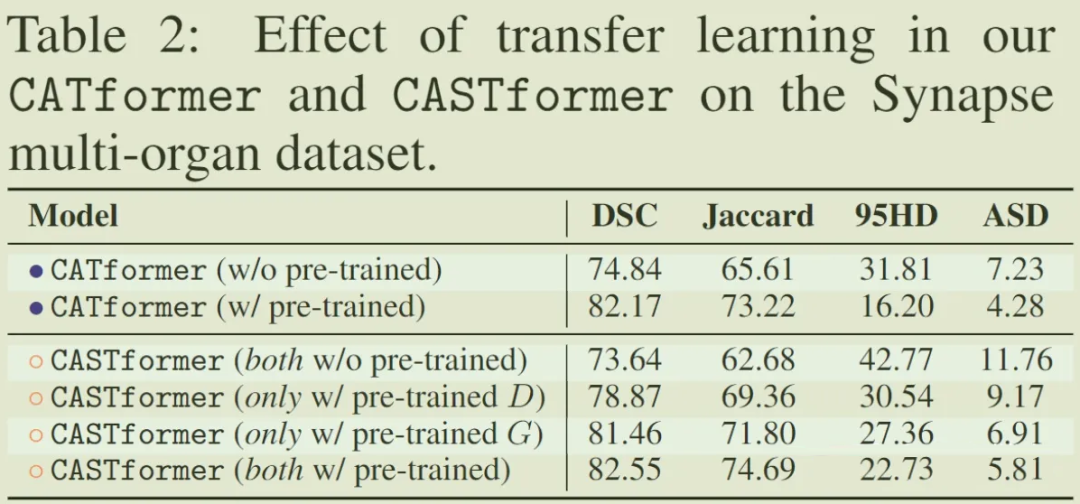
可以看到在使用 pre-trained 的模块在各个衡量标准上都起到较好效果,尤其在 CASTformer 中对 G、D 的消融实验中可以看到仅对 D 进行预训练也可以提升准确率,这说明 D 部分对更好利用语义信息起到促进作用。
B. CAT 和 TEM 模块的有效性:
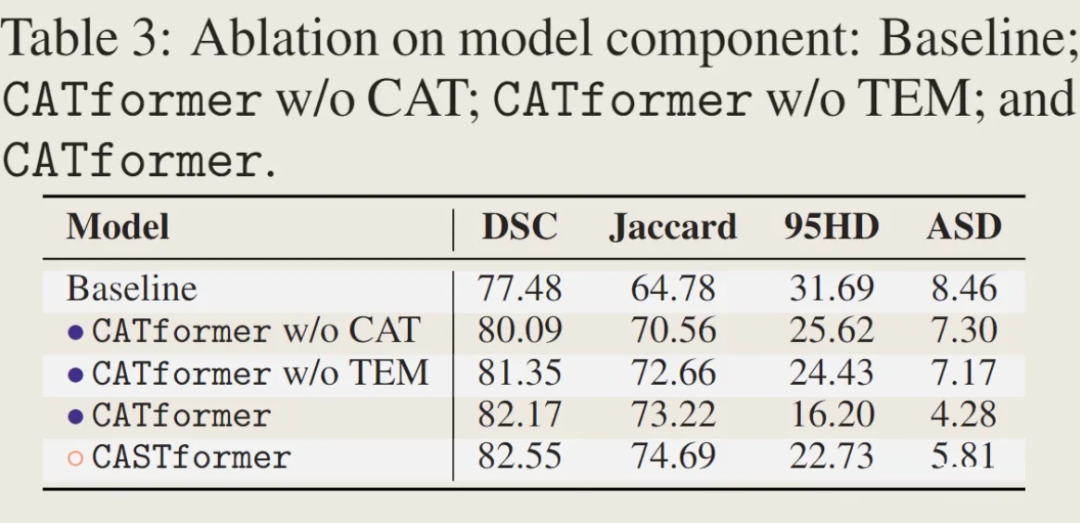
3.3 参数选择有效性
A. 迭代次数 N 和取样数 n 选择:
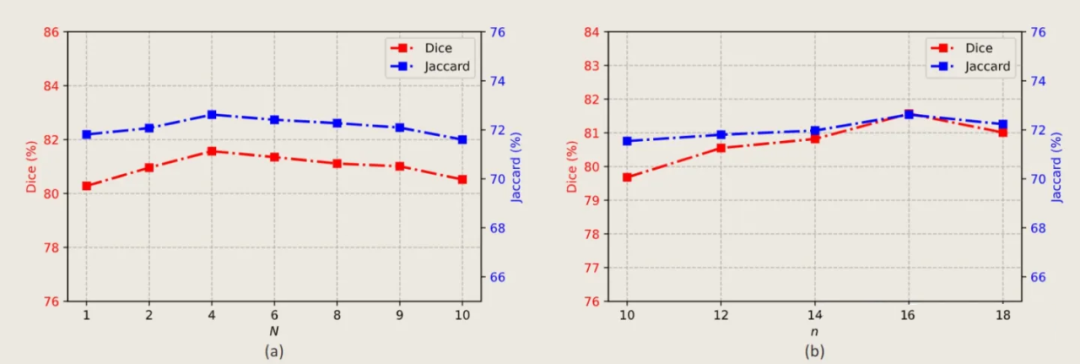
B. 损失函数权重参数
C. GAN网络损失函数选择
D. 分割损失函数选择

E. Decoder选择
这里 FPN 是指 Feature Pyramid Network。
F. 取样方法选择

3.4 可视化
这里箭头初始点是初始取样位置(p1),箭头的终端是最终取样点位置(p4)。通过可视化可以发现取样点的偏移方向倾向于高度语义相关的地区,这也证明了 CAT 模块的有效性。

这里是注意力分布概率的可视化结果。注意力分布概率表示是 query patch 和 key patch 点积的 Softmax 结果分布,这里可以表示其他 patch 与 Query patch 的联系关系。
从可视化结果可以看出,在 layer1 到 layer4 的第一组 layers 中,模型中与 Query patch 具有相关联系的 patch 只是在色彩或纹理上有一定相似性,表明这里模型并没有建立起类知晓性质(class−awarenessproperty)。
而在 layer5 到 layer6第二组中可以发现模型开始关注那些与 Query patch 类系统的 patch,这里表现为在 layer5-2 中开始取样相同类的 patch,在 layer5-3 和 layer5-6 中关注所在类的边界。
而在更深的 layer 中,可以看到模型的注意力开始集中,并且开始关注其他类,这表明模型已经建立起类意识。

参考文献
[1] https://arxiv.org/abs/2010.11929
[2] https://arxiv.org/abs/2108.01684
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
















 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









