







 本文探讨了检索增强生成(RAG)模型的鲁棒性问题,即在使用外部数据时可能出现的错误信息引入,导致模型输出错误答案。研究指出,模型可能因检索到的无关或错误信息(如反事实知识)而产生误导。针对此问题,文章介绍了五篇近期研究,包括SKR框架,通过模型自我知识判断是否需要检索增强;RECALL基准测试,展示了反事实信息对模型的负面影响;以及端到端训练方法、思维链蒸馏和Self-RAG框架,旨在增强模型对检索增强输入的鲁棒性。这些研究为改进大模型的可靠性提供了新思路。
本文探讨了检索增强生成(RAG)模型的鲁棒性问题,即在使用外部数据时可能出现的错误信息引入,导致模型输出错误答案。研究指出,模型可能因检索到的无关或错误信息(如反事实知识)而产生误导。针对此问题,文章介绍了五篇近期研究,包括SKR框架,通过模型自我知识判断是否需要检索增强;RECALL基准测试,展示了反事实信息对模型的负面影响;以及端到端训练方法、思维链蒸馏和Self-RAG框架,旨在增强模型对检索增强输入的鲁棒性。这些研究为改进大模型的可靠性提供了新思路。

©PaperWeekly 原创 · 作者 | 陈思硕
单位 | 北京大学
研究方向 | 自然语言处理
很久没有写论文 notes 了,近期因为参与对检索增强生成(Retrieval-Augmented Generation, RAG)范式鲁棒性的研究,注意到了近两个月来社区中涌现了一小批关于这个话题的工作,简单梳理以飨读者。

何为检索增强:模型可以开卷考
纯参数化的大语言模型将其在海量语料上学习到的世界知识存储在模型参数中,虽然已经展现出来强大能力并改变整个 NLP 乃至深度学习社区的研究范式,但纯参数化的模型存在诸多不足:
1. 长尾记忆困难:不能记住所有训练语料中的所有知识,尤其是对低频的长尾知识记忆困难;
2. 容易过时:参数中的知识容易过时(ChatGPT 和 LLaMa肯定不知道周二国足的比分,硬预测的话应该会预测个比三比零更大的数 x),更新起来很困难(训练代价且容易造成灾难性遗忘);
3. 参数太多导致计算代价大:训练和推理代价高昂(虽然有 Scaling Law,但参数量上去之后就没什么人训练甚至部署得起了→_→)。
类似地,人也很难记住所有的知识(除了高考这种几乎纯比拼 memorization 的考试之前),很多长尾的冷知识和新知识需要的时候从外部的消息源现查就好了。

▲ 全都背下来就会像硬吃记忆面包一样痛苦
同样地,语言模型可以是半参数化的,也就是(参数化的)模型可以外挂一个(非参数化的)语料数据库,推理时以从语料库召回的部分数据为参考组织答案(具体的形式可以是作为额外的上文输入,也可以插在中间的 cross attention 或者输出中),这一范式被称为检索增强生成(Retrieval-Augmented Generation,RAG)。
检索增强的语言模型(Retrieval-Augmented Language Model,RALM)的正式定义是:
A language model (LM) that uses an external datastore at test time.
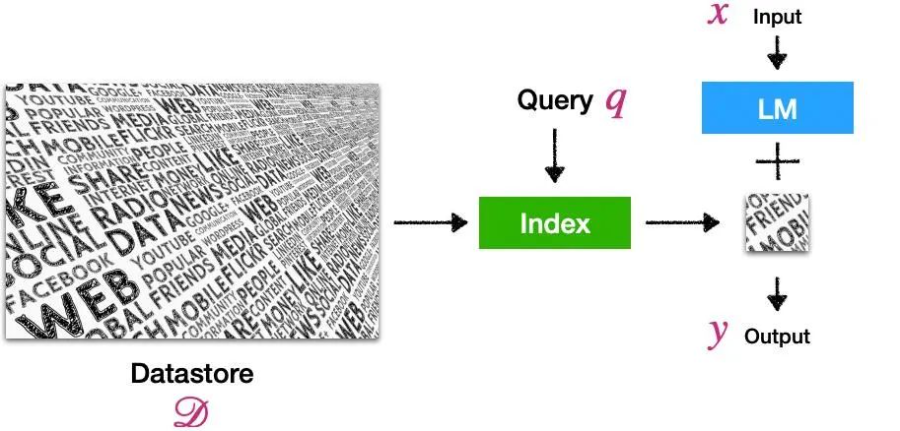
▲ 以上定义和示意图来自ACL 2023的Tutorial [1]
示意图如上,对用户输入的文本 x,我们构造记为 q 的 query ,从数据库 D 的索引中召回了小一部分相关文档(右侧的小块简报),模型以其为参考生成最后的输出 y。除了缓解以上三个问题(长尾记忆困难、容易过时、参数太多导致计算代价大)之外,还可以起到给模型的回答提供可靠的消息来源、防止模型权重泄露隐私信息等作用,具体的机制和代表性工作可以参见今年 ACL 上陈丹琦老师领衔的 Tutorial [1],此处不详细展开。

检索增强是否一定可靠:开卷翻到了毒蘑菇呢?
交代完了 RAG 这一大背景,回到今天想聊的鲁棒性的正题。我们知道,人在翻书找长尾知识或者上网冲浪吃新瓜的时候,如果不加审慎的分辨,很容易以讹传讹:

当然,语言模型也不比人高明,如果检索增强的时候召回的是和输入问题无关的内容(噪声干扰),甚至是反事实的 fake news 或者被篡改的百科,模型就会像吃了毒蘑菇一样胡言乱语。

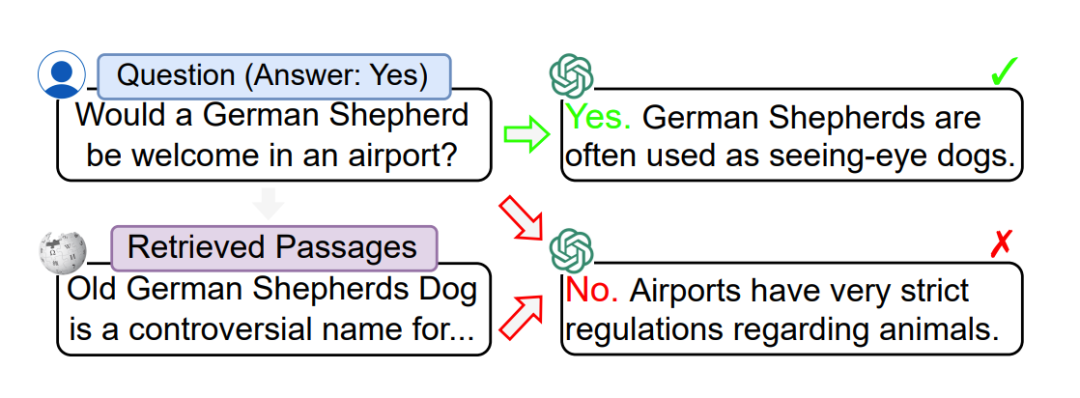
以下是来自论文 [2] 的一个检索回无关内容后输出被影响的例子,原本对“德牧能不能进机场”这样的简单的问题,ChatGPT是高度认可小狗同志作为导盲犬的价值的,果断说 yes,但是检索模块召回了一段“老德牧是一类 balabala 某种狗的争议性名称”的百科介绍作为额外上文输入后,模型突然对小狗变凶了,说出了“机场不许你入内”这样的负心话。
以下是来自论文 [3] 的检索到反事实信息造成模型错误输出的例子。对博闻强识的大模型来说,17-18 赛季的欧冠冠军是道简单题,不用检索增强就知道是皇马,但如果有恶意用户某一天编辑了相关的维基百科把答案改成巴萨,模型通过检索模块吃到这样与自身知识冲突的辅助输入就会被忽悠住,人云亦云,复读出错误的答案。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









