






大型语言模型(LLM)在近些年取得了重大进展,特别是在英语方面,然而,LLM 在中文指令调优方面仍然存在明显差距。不久前,一篇人工智能论文将弱智吧推上AI圈的风口浪尖,该贴吧竟然成为了最好的中文训练数据!具体来说,使用弱智吧数据训练的大模型,跑分超过百科、知乎、豆瓣、小红书等平台,甚至是研究团队精心挑选的数据集。在问答、头脑风暴、分类、生成、总结、提取等8项测试中取得最高分。
5月8日-5月9日,我们邀请到国内某高校副教授,某著名期刊青年编委成员Kimi老师为我们带来——大模型微调神器!"弱智吧"is all you need,带我们深入解析中文大模型领域具有重要意义的论文!
免费扫码参与直播
领导师亲自整理100+篇最新大模型论文&99个大模型微调数据集


100+篇热门大模型论文部分展示
01直播
直播导师:Kimi老师


-国内某高校副教授,某著名期刊青年编委成员
-发表SCI论文近20篇且全部为顶会或CCF推荐期刊或SCI一区
-研究方向:自然语言处理&深度学习
-近三年来,累计带领超过50名学生成功发表SCI或顶会论文,其中大部分为中科院一区或CCF推荐期刊。独创NTR快速论文写作法,擅长指导学生76天内快速出文
02
直播大纲


1. 介绍大型语言模型(LLMs)的背景,讨论现有LLMs在英文上的进展和中文LLMs发展的差距。
2. 探讨高质量中文指令调整数据集的必要性。介绍指令微调的概念和重要性。讨论现有英文和中文指令调整数据集的差异。
3. 解释数据混合策略对模型性能的影响。
4. COIG-CQIA数据集介绍
5. 分析不同数据源对模型性能的影响。探讨不同基础模型在CQIA-Subset上的性能。分析数据源对模型安全性的影响。

免费扫码参与直播
领导师亲自整理100+篇最新大模型论文&99个大模型微调数据集

弱智吧是百度贴吧上的一个子版块,这是一个非常神奇的地方,吧友们热衷于创作和分享一语双关、一词多义、因果倒置、谐音梗等带着逻辑陷阱的内容,而且部分帖子甚至带有一定的哲学意味。但是,拿这些东西训练全知全能伟大的大模型?能行吗。
答案是非常行!由中科院深圳先进技术研究院、中科院自动化研究所,滑铁卢大学等众多高校、研究机构联合团队提出了 COIG-CQIA(全称 Chinese Open Instruction Generalist - Quality Is All You Need),这是一个高质量的中文指令调优数据集。数据来源包括问答社区、维基百科、考试题目和现有的 NLP 数据集,并且经过严格过滤和处理。
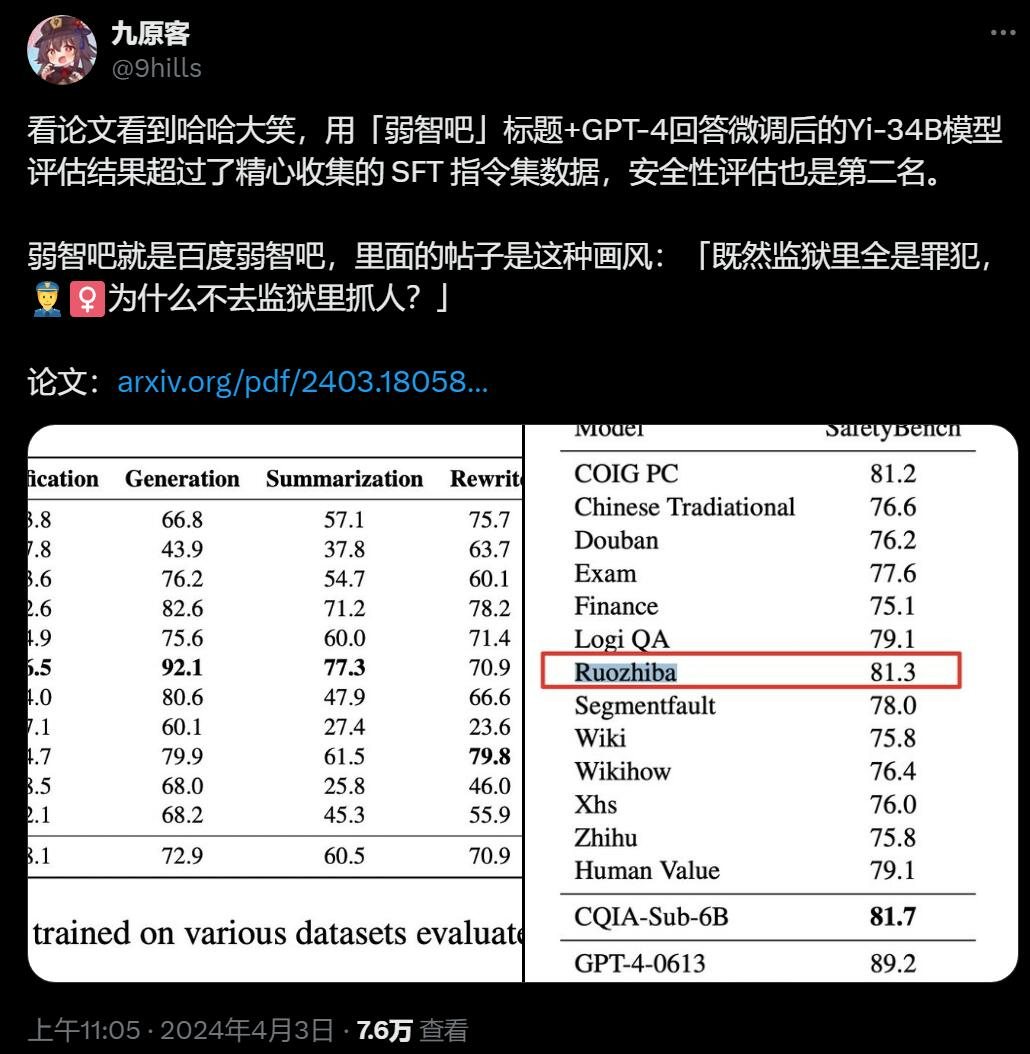
在做完了整理工作后,研究团队使用COIG-CQIA数据集对多个开源中文大模型做了微调。
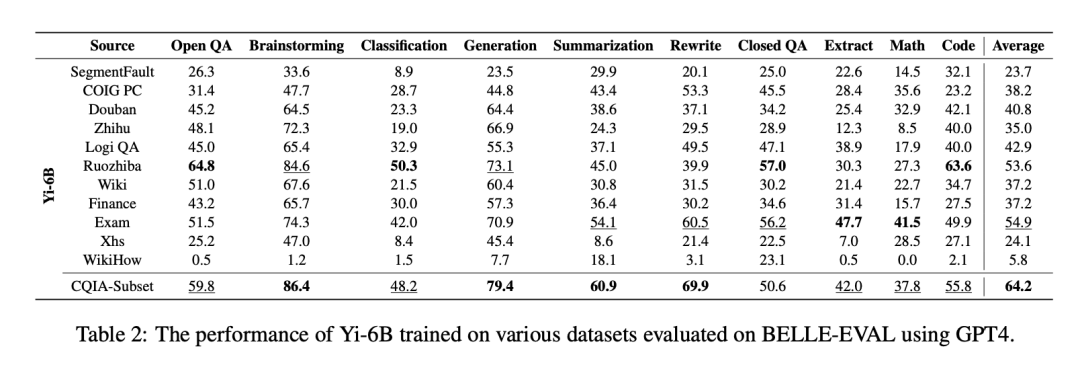
当然弱智吧并不是这项研究的全部,它的真正贡献在于为中文大模型开发提供了一个高质量的指令微调数据集COIG-CQIA。通过对各种中文互联网数据源的探索,这项研究为构建中文指令数据集提供了很多有益的启示。比如社交媒体数据虽然开放多样,但也存在不少有害信息风险;而百科类数据专业性强,但覆盖面可能不够广。
指令微调(Instruction Tuning)是一种训练大型语言模型的技术,它通过在特定任务上对模型进行再训练(fine-tuning),使模型能够更好地理解和执行给定的指令。这种方法特别适用于需要模型进行特定任务执行的场景,比如编写代码、解决数学问题或提供事实查询的答案。指令微调的关键在于构建高质量的指令-输出对数据集,这些数据集包含了人类指令和对应的模型输出,通过这些数据集对模型进行训练,可以显著提高模型执行特定任务的能力。
然而,对于中文这样的语言,高质量的指令调整数据集的建设面临着独特的挑战。中文的语法结构、语言表达习惯与英语存在显著差异,且中文社区的互动模式也与英语社区不同。因此,为了提升中文LLMs的性能,需要专门针对中文设计和构建指令调整数据集。这些数据集需要覆盖广泛的中文语言使用场景,包含丰富的语言特征和文化元素,以确保模型能够准确理解和执行中文指令。
免费扫码参与直播
领导师亲自整理100+篇最新大模型论文&99个大模型微调数据集

对于想要发表论文,对科研感兴趣或正在为科研做准备的同学,想要快速发论文有两点至关重
对于还没有发过第一篇论文,还不能通过其它方面来证明自己天赋异禀的科研新手,学会如何写论文、发顶会的重要性不言而喻。
发顶会到底难不难?近年来各大顶会的论文接收数量逐年攀升,身边的朋友同学也常有听闻成功发顶会,总让人觉得发顶会这事儿好像没那么难!
但是到了真正实操阶段才发现,并不那么简单,可能照着自己的想法做下去并不能写出一篇好的论文、甚至不能写出论文。掌握方法,有人指点和引导很重要!
还在为创新点而头秃的CSer,还在愁如何写出一篇好论文的科研党,一定都需要来自顶会论文作者、顶会审稿人的经验传授和指点。
很可能你卡了很久的某个点,在和学术前辈们聊完之后就能轻松解决。
扫描二维码
与大牛导师一对一meeting

文末福利
给大家送一波大福利!我整理了100节计算机全方向必学课程,包含CV&NLP&论文写作经典课程,限时免费领!


立即扫码 赠系列课程
-END-

















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









