








我们都知道,牛顿说过一句名言"If I have seen further, it is by standing on the shoulders of giants". 无可否认,牛顿取得了无与匹敌的成就,人类历史上最伟大的科学家之一,但同样无可否认的是,牛顿确实吸收了大量前人的研究成果,诸如哥白尼、伽利略和开普勒等人,正因如此,联合国为了纪念伽利略首次将望远镜用作天文观测四百周年,2009 年的时候,通过了”国际天文年“的决议,并选中《巨人的肩膀》(Shoulders Of Giants)作为主题曲。我想这大概是告诉后人,“吃水不忘挖井人”,牛顿的成就固然伟大,他脚下的“巨人肩膀”伽利略也同样不能忘了。
也许,“巨人肩膀”无处不在,有些人善于发现,有些人选择性失明,而牛顿的伟大之处在于他能够发现,这是伟大其一,更为重要的是,他还能自己造了梯子爬上“巨人的肩膀”,并成为一个新的“巨人肩膀”,这是伟大其二。
而回到这篇文章的主题,作为平凡人的我们,暂且先把如何发现并造了梯子云云撇开不谈,让我们先来捋一捋现在 NLP 当中可能的“巨人肩膀”在哪里,以及有哪些已经造好的“梯子”可供攀登,余下的,就留给那些立志成为“巨人肩膀”的人文志士们吧。
作者丨许维
单位丨腾讯知文
研究方向丨智能客服、问答系统
戈多会来吗?
在前文深度长文:NLP的巨人肩膀(上)中,我们介绍了好几种获取句子表征的方法,然而值得注意的是,我们并不是只对如何获取更好的句子表征感兴趣。
其实更有趣的是,这些方法在评估他们各自模型性能的时候所采取的方法,回过头去进行梳理,我们发现,无论是稍早些的 InferSent,还是 2018 年提出的 Quick-thoughts 和 Multi-task Learning 获取通用句子表征的方法,他们无一例外都使用了同一种思路:将得到的句子表征,在新的分类任务上进行训练,而此时的模型一般都只用一个全连接层,然后接上softmax进行分类。
分类器足够简单,足够浅层,相比那些在这些分类任务上设计的足够复杂的模型来说简直不值一提。然而令人大跌眼镜的是,这些简单的分类器都能够比肩甚至超越他们各自时代的最好结果,这不能不说是个惊喜。而创造这些惊喜的背后功臣,就是迁移学习。更进一步地,迁移学习的本质,就是给爬上“巨人的肩膀”提供了一架结实的梯子。
具体的,在这些句子级别的任务中,属于 InferSent 和 Quick-thoughts 这些模型的“巨人肩膀”便是他们各自使用的训练数据,迁移学习最后给他们搭了一个梯子,然而这个梯子并没有很好上,磕磕绊绊,人类 AI 算是站在第一级梯子上,试探性的伸出了一只腿,另一只腿即将跨出,只可惜并不知道是否有他们苦苦等待了五年之久的戈多?
一丝曙光
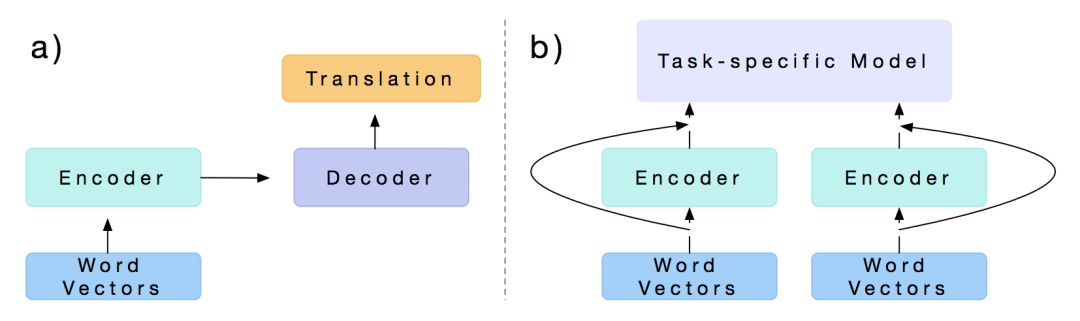
2017 年,Salesforce 的 Bryan McCann 等人发表了一篇文章 Learned in Translation: Contextualized Word Vectors,论文首先用一个 Encoder-Decoder 框架在机器翻译的训练语料上进行预训练,而后用训练好的模型,只取其中的 Embedding 层和 Encoder 层,同时在一个新的任务上设计一个 task-specific 模型,再将原先预训练好的 Embedding 层和 Encoder 层的输出作为这个 task-specific 模型的输入,最终在新的任务场景下进行训练。
他们尝试了很多不同的任务,包括文本分类,Question Answering,Natural Language Inference 和 SQuAD 等,并在这些任务中,与 GloVe 作为模型的输入时候的效果进行比较。实验结果表明他们提出的 Context Vectors 在不同任务中都带来了不同程度效果的提升。
和上文中提到的诸如 Skip-thoughts 方法有所不同的是,CoVe 更侧重于如何将现有数据上预训练得到的表征迁移到新任务场景中,而之前的句子级任务中大多数都只把迁移过程当做一个评估他们表征效果的手段,因此观念上有所不同。
那么,CoVe 似乎通过监督数据上的预训练,取得了让人眼前一亮的结果,是否可以进一步地,撇去监督数据的依赖,直接在无标记数据上预训练呢?
ELMo
2018 年的早些时候,AllenNLP 的 Matthew E. Peters 等人在论文 Deep contextualized word representations(该论文同时被 ICLR 和 NAACL 接受,并且获得了 NAACL 最佳论文奖,可见其含金量)中首次提出了 ELMo,它的全称是 Embeddings from Language Models,从名称上可以看出,ELMo 为了利用无标记数据,使用了语言模型,我们先来看看它是如何利用语言模型的。
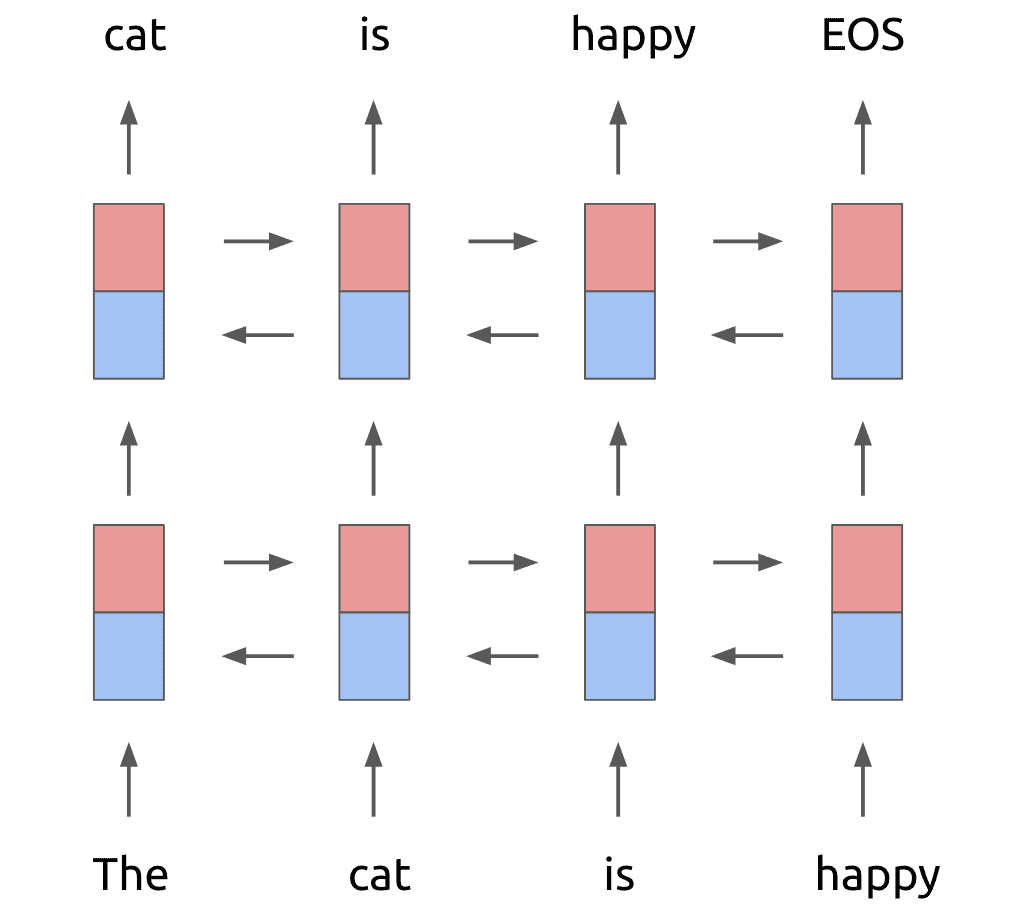
基本框架是一个双层的 Bi-LSTM,不过在第一层和第二层之间加入了一个残差结构(一般来说,残差结构能让训练过程更稳定)。做预训练的时候,ELMo 的训练目标函数为:
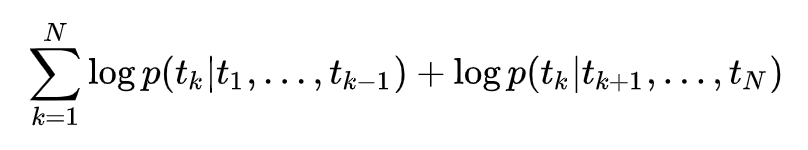
这个式子很清晰,前后有两个概率,第一个概率是来自于正向的由左到右的 RNN 结构,在每一个时刻上的 RNN 输出(也就是这里的第二层 LSTM 输出),然后再接一个 Softmax 层将其变为概率含义,就自然得到了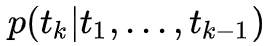 ;与此类似,第二个概率来自反向的由右到左的 RNN 结构,每一个时刻 RNN 的输出经过 Softmax 层后也能得到一个概率大小,表示从某个词的下文推断该词的概率大小。
;与此类似,第二个概率来自反向的由右到左的 RNN 结构,每一个时刻 RNN 的输出经过 Softmax 层后也能得到一个概率大小,表示从某个词的下文推断该词的概率大小。
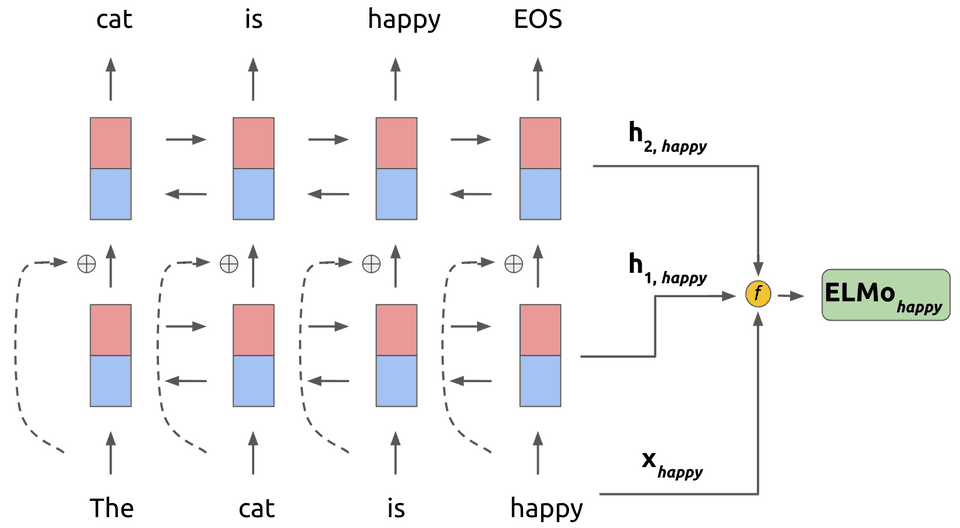
ELMo 的基本框架便是 2-stacked biLSTM + Residual 的结构,不过和普通 RNN 结构的不同之处在于,ELMo 借鉴了 2016 年 Google Brain 的 Rafal Jozefowicz 等人发表的 Exploring the Limits of Language Modeling,其主要改进在于输入层和输出层不再是 word,而是变为了一个 char-based CNN 结构,ELMo 在输入层和输出层考虑了使用同样的这种结构,该结构如下图示:
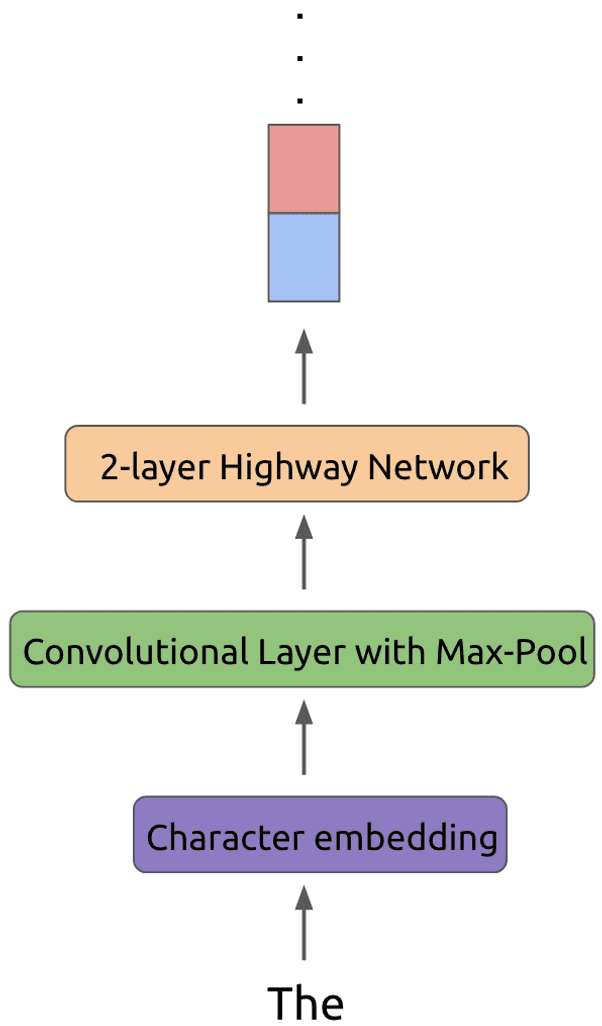
这样做有什么好处呢?因为输入层和输出层都使用了这种 CNN 结构,我们先来看看输出层使用这种结构怎么用,以及有什么优势。我们都知道,在 CBOW 中的普通 Softmax 方法中,为了计算每个词的概率大小,使用的如下公式的计算方法:
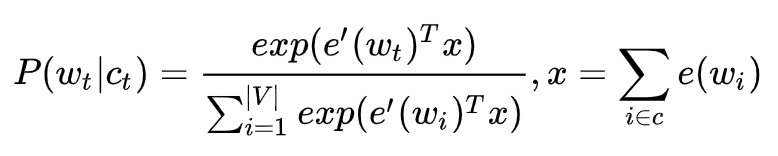
说白了,也就是先通过向量点乘的形式计算得到 logits,然后再通过 softmax 变成概率意义,这本质上和普通分类没什么区别,只不过是一个较大的 |V| 分类问题。
现在我们假定 char-based CNN 模型是现成已有的,对于任意一个目标词都可以得到一个向量表示 CNN(tk) ,当前时刻的 LSTM 的输出向量为 h,那么便可以通过同样的方法得到目标词的概率大小:
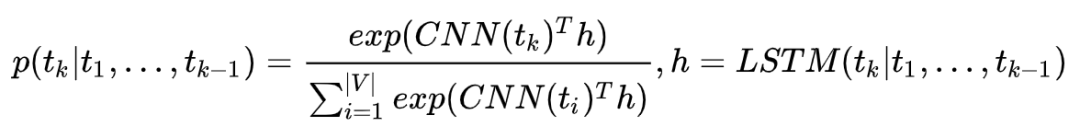
在原论文中,把这种先经过 CNN 得到词向量,然后再计算 Softmax 的方法叫做 CNN Softmax。利用 CNN 解决有三点优势值得注意:
1. CNN 能减少普通做 Softmax 时全连接层中的必须要有的 |V|h 的参数规模,只需保持 CNN 内部的参数大小即可。一般来说,CNN 中的参数规模都要比 |V|h 的参数规模小得多;
2. CNN 可以解决 OOV (Out-of-Vocabulary)问题,这个在翻译问题中尤其头疼;
3. 在预测阶段,CNN 对于每一个词向量的计算可以预先做好,更能够减轻 inference 阶段的计算压力。
补充一句,普通 Softmax 在大词典上的计算压力,都是因为来自于这种方法需要把一个神经网络的输出通过全连接层映射为单个值(而每个类别需要一个映射一次。
一次 h 大小的计算规模,|V| 次映射便需要总共 |V|*h 这么多次的映射规模),对于每个类别的映射参数都不同,而 CNN Softmax 的好处就在于能够做到对于不同的词,映射参数都是共享的,这个共享便体现在使用的 CNN 中的参数都是同一套,从而大大减少参数的规模。
同样的,对于输入层,ELMo 也是用了一样的 CNN 结构,只不过参数不一样而已。和输出层中的分析类似,输入层中 CNN 的引入同样可以减少参数规模。不过 Exploring the Limits of Language Modeling 文中也指出了训练时间会略微增加,因为原来的 look-up 操作可以做到更快一些,对 OOV 问题也能够比较好的应对,从而把词典大小不再限定在一个固定的词典大小上。
最终 ELMo 的主要结构便如下图(b)所示,可见输入层和输出层都是一个 CNN,中间使用 Bi-LSTM 框架,至于具体细节便如上两张图中所示。
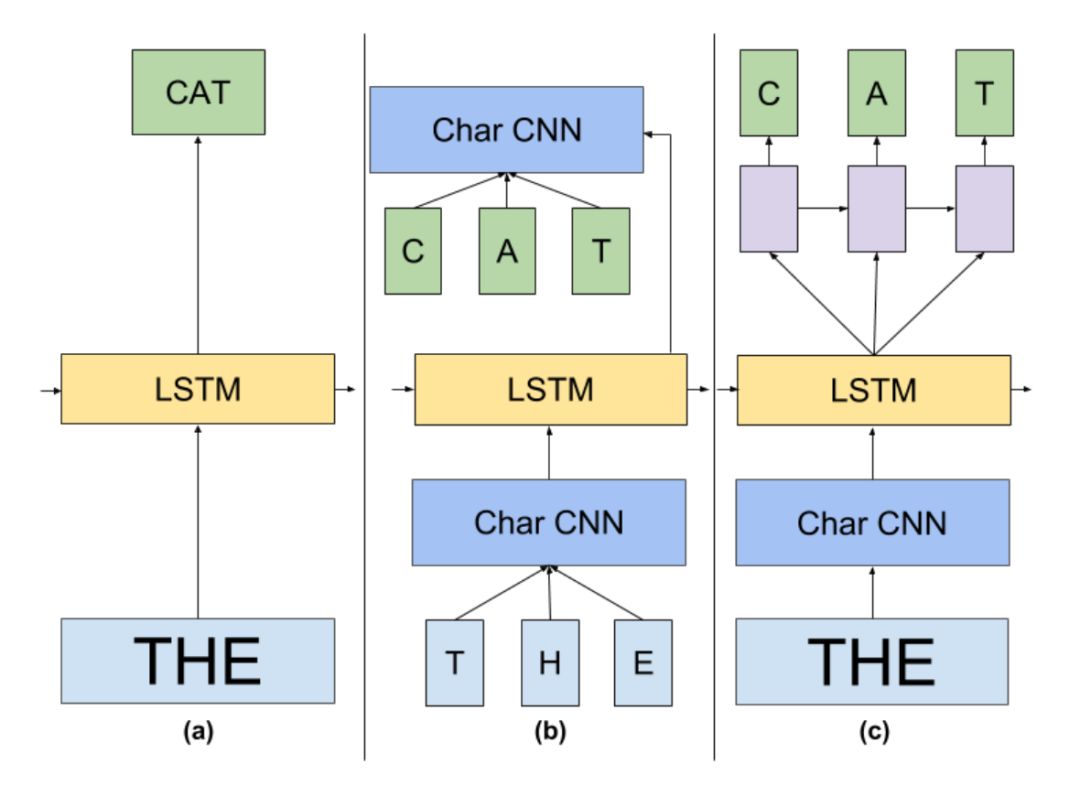
最后,在大规模语料上训练完成的这种 CNN-BIG-LSTM 模型,怎么用呢?其实,如果把每一层的输出结果拿出来,这里大概有三层的词向量可以利用:输入层 CNN 的输出,即是 LSTM 的输入向量,第一层 LSTM 的输出和第二层的输出向量。
又因为 LSTM 是双向的,因此对于任意一个词,如果 LSTM 的层数为 L 的话,总共可获得的向量个数为 2L+1,表示如下:
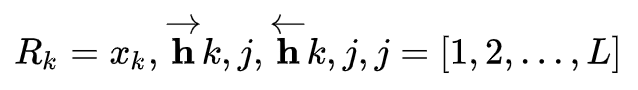
到这里还只是把 ELMo 的向量给抽取出来了。对于每一个词,可以根据下面的式子得到它的向量,其中 γ 是一个 scale 因子,加入这个因子主要是想将 ELMo 的向量与具体任务的向量分布拉平到同一个分布水平,这时候便需要这么一个缩放因子了。
另外, sj 便是针对每一层的输出向量,利用一个 softmax 的参数来学习不同层的权值参数,因为不同任务需要的词语意义粒度也不一致,一般认为浅层的表征比较倾向于句法,而高层输出的向量比较倾向于语义信息。因此通过一个 softmax 的结构让任务自动去学习各层之间的权重,自然也是比较合理的做法。
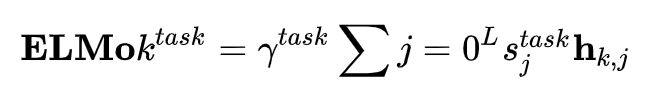
前面我们说过,无论是基于传统统计的 N-gram 还是普通神经网络的 NNLM 结构,都会有一个很严重的问题,那就是计算复杂度随着上下文窗口 N 大小的增大急剧上升。其中 N-gram 是指数上升,NNLM 是以 |d| × N 的形式增加,|d| 是词向量的维度,虽然 NNLM 已经改观了很多,但依然是一个斜率很大的线性增加关系。
后来 CBOW 和 Skip-gram 以及再后来的 GloVe 终于做到了计算复杂度与所选窗口大小无关,只与词典大小和词向量维度相关。
不过需要指出的是,这里讨论的计算复杂度只是预测单个词的计算时间复杂度,如果是求整个输入序列的话,还是避免不了要与序列长度相关,在这一点上和下面要分析的 RNN 在横向的时间序列上有一个时间复杂度,其原因是一致的。
并且近些年得益于硬件持续的摩尔定律发挥威力,机器的计算能力也有长足的进步,因此在这两方面因素的作用下,以 word2vec 为代表的方法大放光彩,引领了一波 NLP 的发展浪潮。
然而,在今天看来,无论 word2vec 中的模型、还是 GloVe 的模型,都过于简单,它们都受限于所使用的模型表征能力,某种意义上都只能得到比较偏上下文共现意义上的词向量,并且也很少考虑过词序对于词的意义的影响(比如 CBOW 从其名称来看就是一个 bag-of-words,在模型的输入中没有词序的概念)。
理论上,RNN 结构的计算复杂度,跟两个方向上都有关系,一方面是纵向上,另一方面是横向上,纵向上主要是 RNN 结构本身的时间复杂度,这个复杂度只与 RNN 结构内部的 hidden state 维度以及模型结构的复杂度,在 ELMo 中的话还跟词典大小相关(因为最后一层还是一个词典大小上的分类问题,以及输入也需要维护一个词典大小的 loop up 操作)。
在横向上的计算复杂度,就主要是受制于输入序列的长度,而 RNN 结构本身因为在时间序列上共享参数,其自身计算复杂度这一部分不变,因而总的 ELMo 结构计算复杂度主要有词典大小、隐藏层输出维度大小、模型的结构复杂度以及最后的输入序列长度。
前三者可以认为和之前的模型保持一致,最后的输入序列长度,也只是与其保持线性关系,虽然系数是单个 RNN 单元的计算复杂度,斜率依然很大(通常 RNN 结构的训练都比较费时),但是在机器性能提升的情况下,这一部分至少不是阻碍词向量技术发展的最关键的因素了。
因此,在新的时代下,机器性能得到更进一步提升的背景下,算法人员都急需一种能够揭示无论词还是句子更深层语义的方法出现,我想 ELMo 正是顺应了这种时代的需要而华丽诞生。
ELMo 的思想足够简单,相比它的前辈们,可以说 ELMo 并没有本质上的创新,连模型也基本是引用和拼接别人的工作,它的思想在很多年前就已经有人在用,并没有特别新奇的地方。
这似乎从反面证明了真正漂亮的工作从来不是突出各自的模型有多么绚丽,只有无其他亮点的论文,才需要依靠描摹了高清足够喜人眼球的图片去吸引评审人的注意力。因此从这个角度去看,似乎可以得出一个啼笑皆非的结论:论文的漂亮程度与论文图的漂亮程度呈反比。
但同时它的效果又足够惊艳,它的出现,在 2018 年初,这个也许在 NLP 历史上并没有多么显眼的年头,掀起了一阵不小的波澜,至少在 6 项 NLP 任务上横扫当时的最好结果,包括 SQuAD,SNLI,SRL,NER,Coref 和 SST-5。
而后来的故事以及可预见的将来里,这或许仅仅只是一个开始,就如山洪海啸前的一朵清秀的涟漪。
ULMFit
差不多和 ELMo 同期,另一个同样非常惊艳的工作也被提出来,这个团队是致力于将深度学习普及和易用的 Fast AI,而论文两位共同作者之一的 Jeremy Howard,其实就是 Fast AI 的创始人,是 Kaggle 之前的 president 和首席科学家,并且亲自参与过 Kaggle 上很多比赛,长期排在排行榜的第一。
在论文 Universal Language Model Fine-tuning for Text Classification 中,他们提出了 ULMFit 结构,其实这本质上是他们提出的一个方法,而不是具体的某种结构或模型。只不过正如论文标题所言,他们主要把它应用于文本分类问题中。
和 ELMo 相同的地方在于,ULMFit 同样使用了语言模型,并且预训练的模型主要也是LSTM,基本思路也是预训练完成后在具体任务上进行 finetune,但不同之处也有很多。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









