








作者丨张琨
学校丨中国科学技术大学博士生
研究方向丨自然语言处理


论文动机
自从 BERT 被提出之后,整个自然语言处理领域进入了一个全新的阶段,大家纷纷使用 BERT 作为模型的初始化,或者说在 BERT 上进行微调。BERT 的优势就在于使用了超大规模的文本语料,从而使得模型能够掌握丰富的语义模式。
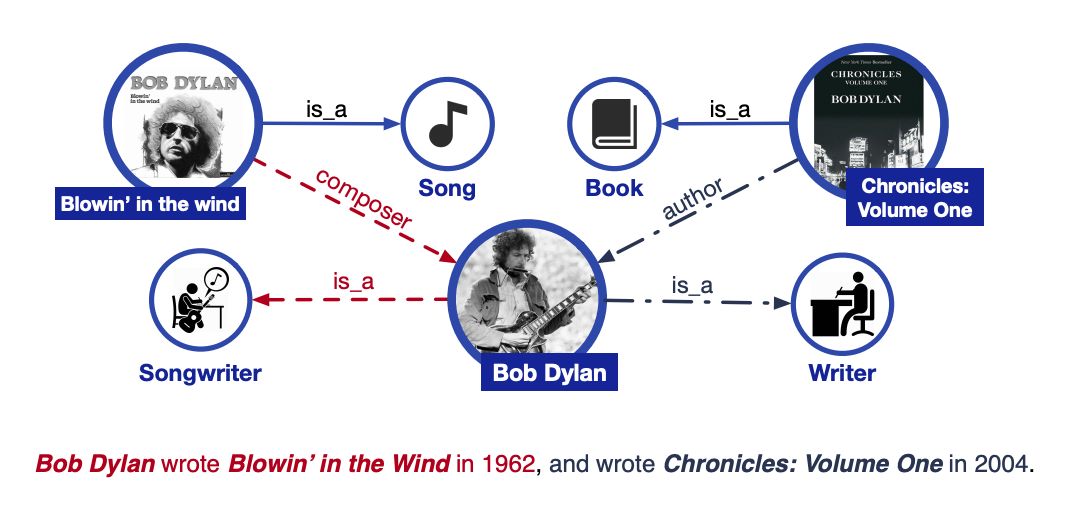
但 BERT 是否还有改进的空间呢?如下图,当提到*鲍勃迪伦*的时候,单纯依靠大规模的普通文本很难理解到底是指音乐家还是作者,但如果加入充分的先验知识,那么模型可能就会学习到更加精细化的语义表示,如何让 BERT 掌握更多的人类先验知识呢?
本文就提出了一种方法,将知识图谱的信息加入到模型的训练中,这样模型就可以从大规模的文本语料和先验知识丰富的知识图谱中学习到字、词、句以及知识表示等内容,从而有助于其解决更加复杂、更加抽象的自然语言处理问题。
模型结构
整个模型的动机就是将知识图谱的信息有效融入到模型的训练中,考虑到 BERT 的复杂结构,如何将知识图谱的信息进行有效融合呢?作者提出了如下的结构:
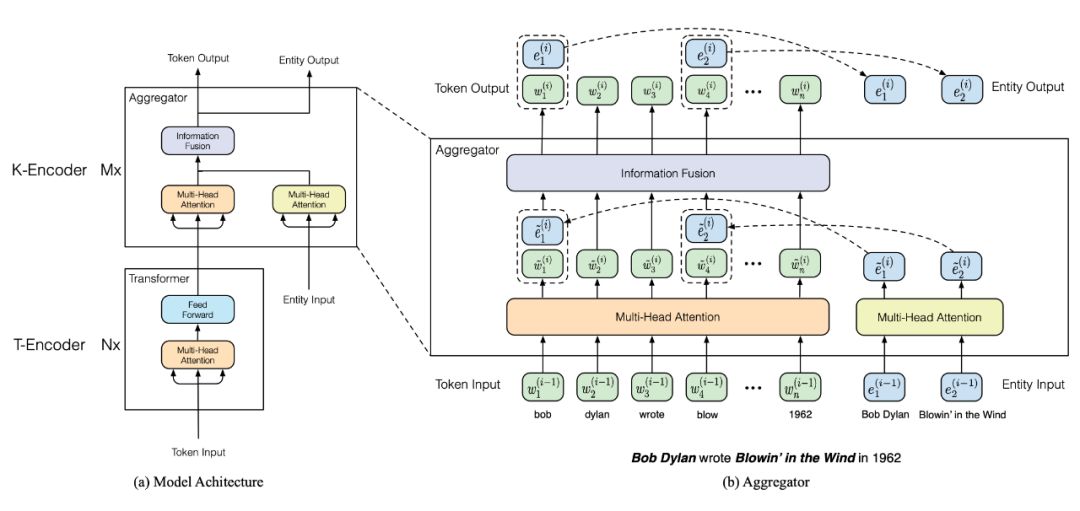
可以看出,模型将 BERT 中的 Encoder 替换为了 T-Encoder+K-Encoder,T-Encoder 依然是对原来的文本进行编码,这部分和 BERT 是一样的,在 K-Encoder 中,可以看到输入输出都变成了两个,多了 entity 的信息。
具体来说,首先可以利用 TransE 的方法对知识图谱中的内容进行表示,并对文本中的实体进行识别,这样文本中的实体都会有一个来自知识图谱的实体表示,需要注意的是文本的长度和实体的长度并不相等,然后先用 mutli-head attention 对文本和实体分别进行处理,得到在整个序列中情境感知的语义表示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









