







本文为 12 月 27 日,北京航空航天大学博士生、微软亚洲研究院实习生——吴俣在第 21 期 PhD Talk 中的直播分享实录。
本次 Talk 的主题是基于动态词表的对话生成研究。首先,吴俣博士带大家回顾了近几年来聊天机器人领域的发展,并仔细对比检索式聊天机器人和生成式聊天机器人的优点和缺点。
随后,他还以第一作者的身份,解读了北京航空航天大学和微软亚洲研究院于 AAAI 2018 发表的工作 Neural Response Generation with Dynamic Vocabularies。
这篇论文致力于在对话生成时构建动态词典,在使 decoding 速度加快的同时,还能去除不相关词汇的干扰。在不影响效果的前提下,本文模型将在线生成速度提升了 40%。
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.588235294117647" data-w="432" data-src="http://v.qq.com/iframe/player.html?vid=p0528wsqjvb&width=654&height=367.875&auto=0" style="display: block; width: 654px !important; height: 367.875px !important;" width="654" height="367.875" data-vh="367.875" data-vw="654" src="http://v.qq.com/iframe/player.html?vid=p0528wsqjvb&width=654&height=367.875&auto=0"/>
△ Talk 实录回放
浅析对话系统

对话系统主要分为两类,一类是任务型,另一类是非任务型。任务型对话系统主要应用于企业客服、订票、天气查询等场景,非任务型驱动对话系统则是指以微软小冰为代表的聊天机器人形式。
之所以强调这一点,是因为今年我在 ACL 发表了一篇论文,有同学发邮件问我为什么参考了论文和源代码,还是无法让聊天机器人帮忙订披萨。我只能说,目前聊天机器人实在种类繁多,有的机器人只负责闲聊,有的机器人可以帮你完成某些特定任务。
本次 Talk 会更侧重于介绍闲聊机器人,也就是非任务驱动型对话系统。首先我想给大家推荐一篇关于聊天机器人的综述文章 — A Survey on Dialogue Systems: Recent Advances and New Frontiers。
这篇文章来自京东数据科学团队,是一篇较为全面的对话系统综述,其中引用了 121 篇相关论文,并对论文进行了归类。不仅非常适合初学者,也能让大家对聊天机器人领域有一个更为全面的认识。
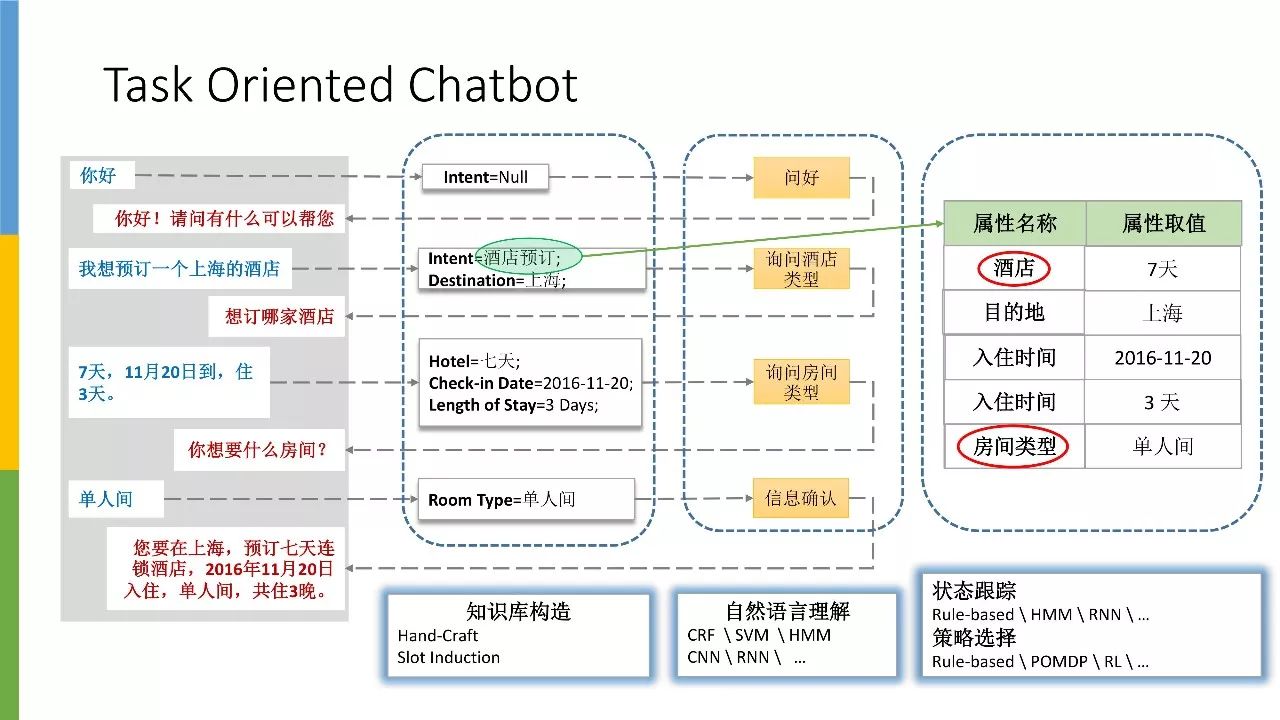
面向任务的对话系统主要分为知识库构造、自然语言理解、状态跟踪和策略选择。针对知识库构造,假设我们的使用场景为酒店预订,那首先我们需要构建一些和酒店相关的知识,比如酒店房型、报价以及酒店位置。
具备了这些基础知识之后,接下来就需要展开对话,通过自然语言理解去分辨问题类型(酒店类型、房间类型等)。确认好相关类型后,我们需要借助 policy 模块,让系统切换到下一个需要向用户确认的信息。更直观地说,我们需要循循善诱引导用户将右表信息填写完整。
聊天机器人类型

普遍来说,聊天机器人主要分为两类,我认为准确来说应该分为三类。
比较早期的研究基本属于第一类:基于模板的聊天机器人,它会定义一些规则,对你的话语进行分析得到某些实体,然后再将这些实体和已经定义好的规则去进行组合,从而给出回复。这类回复往往都是基于模板的,比如说填空。
除了聊天机器人,这种基于模板的文本形成方式还可以应用于很多其他领域,比如自动写稿机器人。
目前比较热门的聊天机器人应该是另外两类,一类是检索型,另一类则是生成型。检索型聊天机器人,主要是指从事先定义好的索引中进行搜索。这需要我们先从互联网上获取一些对话 pairs,然后基于这些数据构造一个搜索引擎,再根据文本相似度进行查找。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









